 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHong Jun Jeon
Adaptive Crowdsourcing Via Self-Supervised Learning
Feb 02, 2024
Common crowdsourcing systems average estimates of a latent quantity of interest provided by many crowdworkers to produce a group estimate. We develop a new approach -- predict-each-worker -- that leverages self-supervised learning and a novel aggregation scheme. This approach adapts weights assigned to crowdworkers based on estimates they provided for previous quantities. When skills vary across crowdworkers or their estimates correlate, the weighted sum offers a more accurate group estimate than the average. Existing algorithms such as expectation maximization can, at least in principle, produce similarly accurate group estimates. However, their computational requirements become onerous when complex models, such as neural networks, are required to express relationships among crowdworkers. Predict-each-worker accommodates such complexity as well as many other practical challenges. We analyze the efficacy of predict-each-worker through theoretical and computational studies. Among other things, we establish asymptotic optimality as the number of engagements per crowdworker grows.
An Information-Theoretic Analysis of In-Context Learning
Jan 28, 2024Previous theoretical results pertaining to meta-learning on sequences build on contrived assumptions and are somewhat convoluted. We introduce new information-theoretic tools that lead to an elegant and very general decomposition of error into three components: irreducible error, meta-learning error, and intra-task error. These tools unify analyses across many meta-learning challenges. To illustrate, we apply them to establish new results about in-context learning with transformers. Our theoretical results characterizes how error decays in both the number of training sequences and sequence lengths. Our results are very general; for example, they avoid contrived mixing time assumptions made by all prior results that establish decay of error with sequence length.
Continual Learning as Computationally Constrained Reinforcement Learning
Jul 10, 2023An agent that efficiently accumulates knowledge to develop increasingly sophisticated skills over a long lifetime could advance the frontier of artificial intelligence capabilities. The design of such agents, which remains a long-standing challenge of artificial intelligence, is addressed by the subject of continual learning. This monograph clarifies and formalizes concepts of continual learning, introducing a framework and set of tools to stimulate further research.
An Information-Theoretic Analysis of Compute-Optimal Neural Scaling Laws
Dec 02, 2022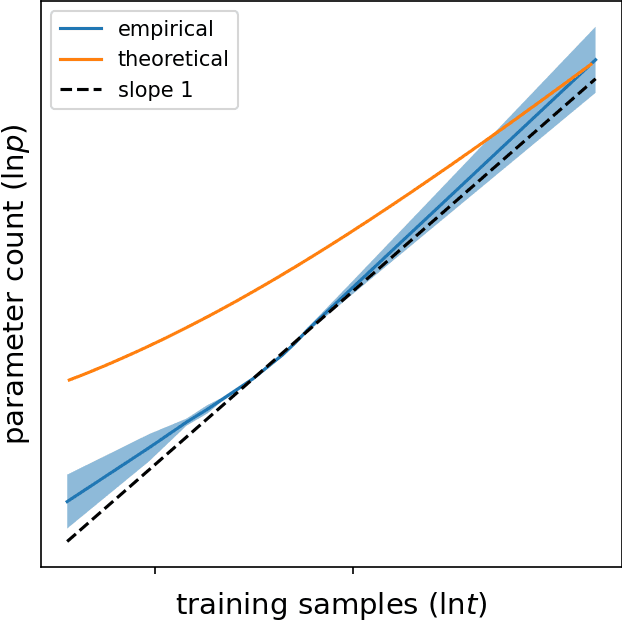
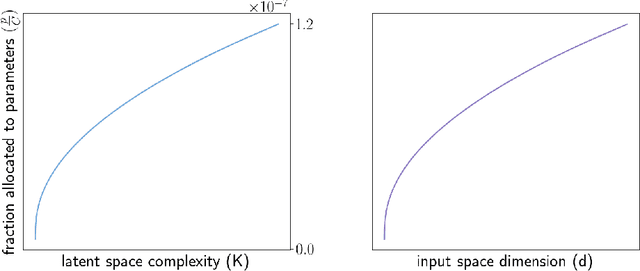

We study the compute-optimal trade-off between model and training data set sizes for large neural networks. Our result suggests a linear relation similar to that supported by the empirical analysis of Chinchilla. While that work studies transformer-based large language models trained on the MassiveText corpus (gopher), as a starting point for development of a mathematical theory, we focus on a simpler learning model and data generating process, each based on a neural network with a sigmoidal output unit and single hidden layer of ReLU activation units. We establish an upper bound on the minimal information-theoretically achievable expected error as a function of model and data set sizes. We then derive allocations of computation that minimize this bound. We present empirical results which suggest that this approximation correctly identifies an asymptotic linear compute-optimal scaling. This approximation can also generate new insights. Among other things, it suggests that, as the input space dimension or latent space complexity grows, as might be the case for example if a longer history of tokens is taken as input to a language model, a larger fraction of the compute budget should be allocated to growing the learning model rather than training data set.
Is Stochastic Gradient Descent Near Optimal?
Oct 06, 2022
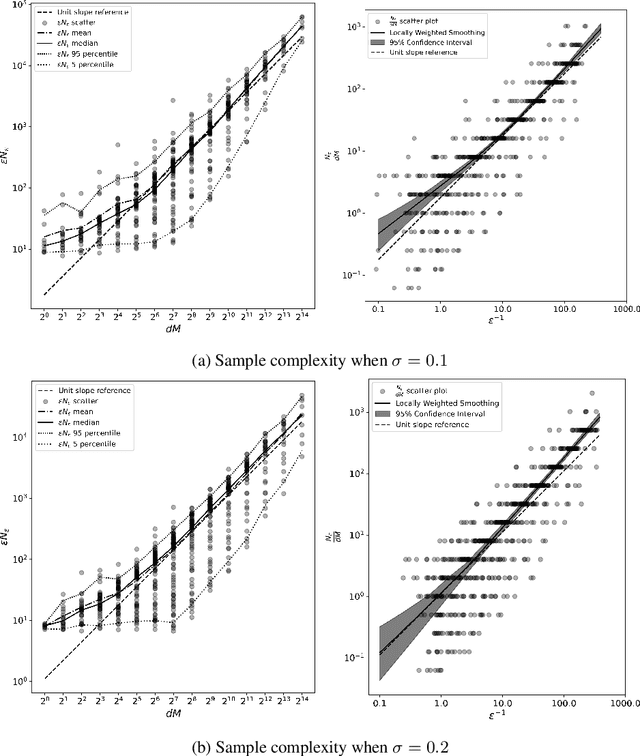


The success of neural networks over the past decade has established them as effective models for many relevant data generating processes. Statistical theory on neural networks indicates graceful scaling of sample complexity. For example, Joen & Van Roy (arXiv:2203.00246) demonstrate that, when data is generated by a ReLU teacher network with $W$ parameters, an optimal learner needs only $\tilde{O}(W/\epsilon)$ samples to attain expected error $\epsilon$. However, existing computational theory suggests that, even for single-hidden-layer teacher networks, to attain small error for all such teacher networks, the computation required to achieve this sample complexity is intractable. In this work, we fit single-hidden-layer neural networks to data generated by single-hidden-layer ReLU teacher networks with parameters drawn from a natural distribution. We demonstrate that stochastic gradient descent (SGD) with automated width selection attains small expected error with a number of samples and total number of queries both nearly linear in the input dimension and width. This suggests that SGD nearly achieves the information-theoretic sample complexity bounds of Joen & Van Roy (arXiv:2203.00246) in a computationally efficient manner. An important difference between our positive empirical results and the negative theoretical results is that the latter address worst-case error of deterministic algorithms, while our analysis centers on expected error of a stochastic algorithm.
Sample Complexity versus Depth: An Information Theoretic Analysis
Apr 07, 2022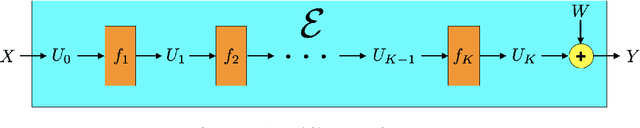
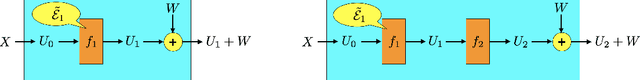
Deep learning has proven effective across a range of data sets. In light of this, a natural inquiry is: "for what data generating processes can deep learning succeed?" In this work, we study the sample complexity of learning multilayer data generating processes of a sort for which deep neural networks seem to be suited. We develop general and elegant information-theoretic tools that accommodate analysis of any data generating process -- shallow or deep, parametric or nonparametric, noiseless or noisy. We then use these tools to characterize the dependence of sample complexity on the depth of multilayer processes. Our results indicate roughly linear dependence on depth. This is in contrast to previous results that suggest exponential or high-order polynomial dependence.
Learning Latent Actions to Control Assistive Robots
Jul 10, 2021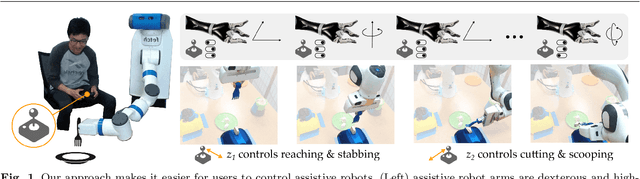


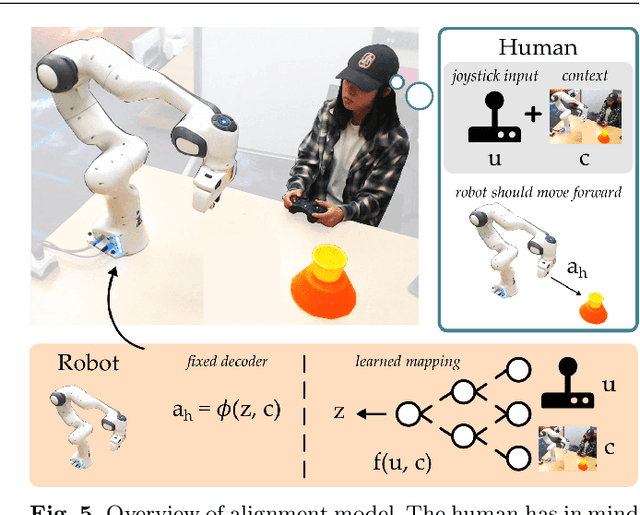
Assistive robot arms enable people with disabilities to conduct everyday tasks on their own. These arms are dexterous and high-dimensional; however, the interfaces people must use to control their robots are low-dimensional. Consider teleoperating a 7-DoF robot arm with a 2-DoF joystick. The robot is helping you eat dinner, and currently you want to cut a piece of tofu. Today's robots assume a pre-defined mapping between joystick inputs and robot actions: in one mode the joystick controls the robot's motion in the x-y plane, in another mode the joystick controls the robot's z-yaw motion, and so on. But this mapping misses out on the task you are trying to perform! Ideally, one joystick axis should control how the robot stabs the tofu and the other axis should control different cutting motions. Our insight is that we can achieve intuitive, user-friendly control of assistive robots by embedding the robot's high-dimensional actions into low-dimensional and human-controllable latent actions. We divide this process into three parts. First, we explore models for learning latent actions from offline task demonstrations, and formalize the properties that latent actions should satisfy. Next, we combine learned latent actions with autonomous robot assistance to help the user reach and maintain their high-level goals. Finally, we learn a personalized alignment model between joystick inputs and latent actions. We evaluate our resulting approach in four user studies where non-disabled participants reach marshmallows, cook apple pie, cut tofu, and assemble dessert. We then test our approach with two disabled adults who leverage assistive devices on a daily basis.
Shared Autonomy with Learned Latent Actions
May 11, 2020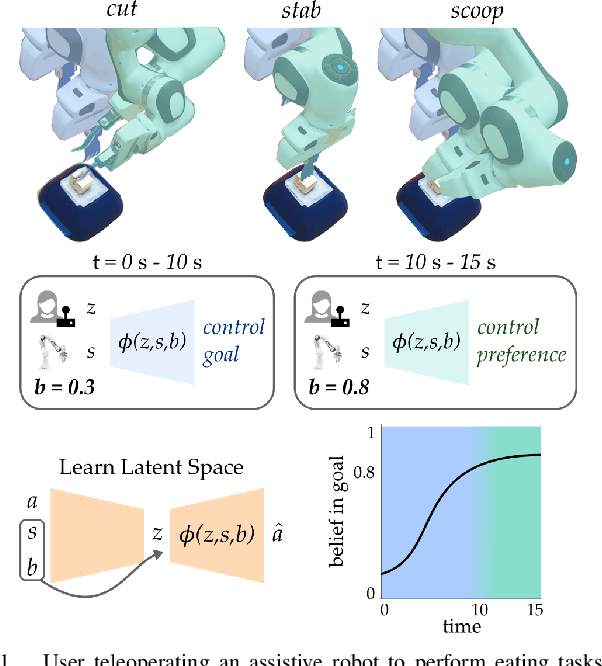
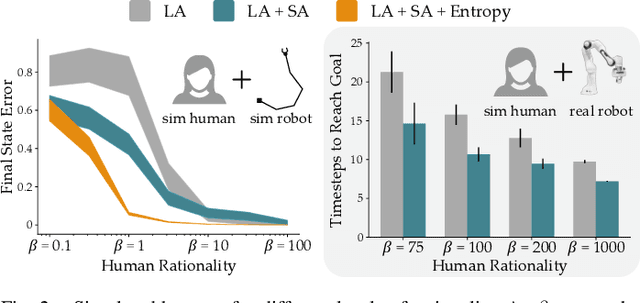
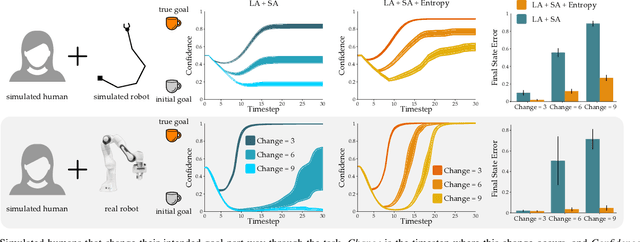
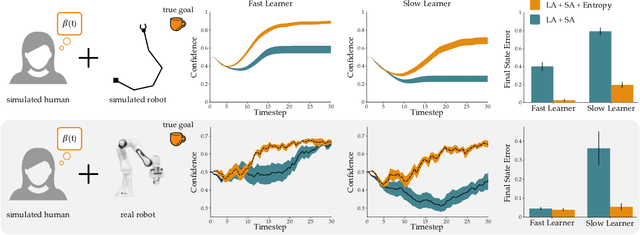
Assistive robots enable people with disabilities to conduct everyday tasks on their own. However, these tasks can be complex, containing both coarse reaching motions and fine-grained manipulation. For example, when eating, not only does one need to move to the correct food item, but they must also precisely manipulate the food in different ways (e.g., cutting, stabbing, scooping). Shared autonomy methods make robot teleoperation safer and more precise by arbitrating user inputs with robot controls. However, these works have focused mainly on the high-level task of reaching a goal from a discrete set, while largely ignoring manipulation of objects at that goal. Meanwhile, dimensionality reduction techniques for teleoperation map useful high-dimensional robot actions into an intuitive low-dimensional controller, but it is unclear if these methods can achieve the requisite precision for tasks like eating. Our insight is that---by combining intuitive embeddings from learned latent actions with robotic assistance from shared autonomy---we can enable precise assistive manipulation. In this work, we adopt learned latent actions for shared autonomy by proposing a new model structure that changes the meaning of the human's input based on the robot's confidence of the goal. We show convergence bounds on the robot's distance to the most likely goal, and develop a training procedure to learn a controller that is able to move between goals even in the presence of shared autonomy. We evaluate our method in simulations and an eating user study. See videos of our experiments here: https://youtu.be/7BouKojzVyk
Reward-rational (implicit) choice: A unifying formalism for reward learning
Feb 12, 2020
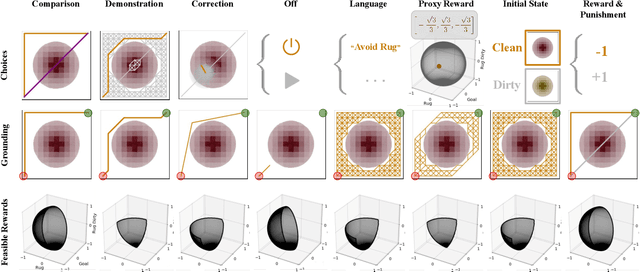

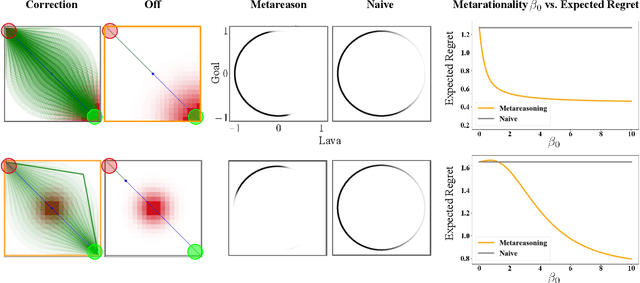
It is often difficult to hand-specify what the correct reward function is for a task, so researchers have instead aimed to learn reward functions from human behavior or feedback. The types of behavior interpreted as evidence of the reward function have expanded greatly in recent years. We've gone from demonstrations, to comparisons, to reading into the information leaked when the human is pushing the robot away or turning it off. And surely, there is more to come. How will a robot make sense of all these diverse types of behavior? Our key insight is that different types of behavior can be interpreted in a single unifying formalism - as a reward-rational choice that the human is making, often implicitly. The formalism offers both a unifying lens with which to view past work, as well as a recipe for interpreting new sources of information that are yet to be uncovered. We provide two examples to showcase this: interpreting a new feedback type, and reading into how the choice of feedback itself leaks information about the reward.
Configuration Space Metrics
Aug 12, 2018
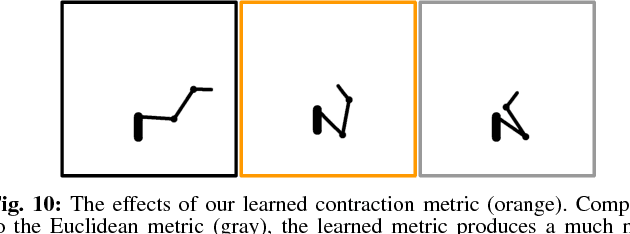
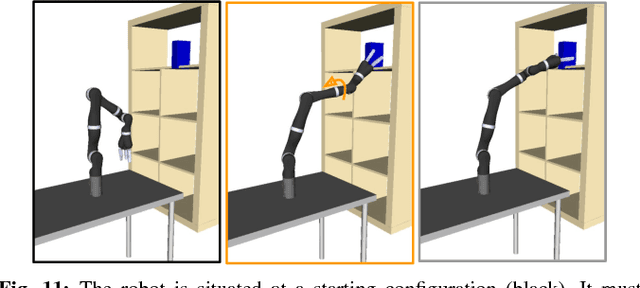

When robot manipulators decide how to reach for an object, hand it over, or obey some task constraint, they implicitly assume a Euclidean distance metric in their configuration space. Their notion of what makes a configuration closer or further is dictated by this assumption. But different distance metrics will lead to different solutions. What is efficient under a Euclidean metric might not necessarily look the most efficient or natural to a person observing the robot. In this paper, we analyze the effect of the metric on robot behavior, examining both Euclidean, as well as non-Euclidean metrics -- metrics that make certain joints cheaper, or that correlate different joints. Our user data suggests that tasks on a 3DOF arm and the Jaco 7DOF arm can typically be grouped into ones where a Euclidean metric works well, and tasks where that is no longer the case: there, surprisingly, penalizing elbow motion (and sometimes correlating the shoulder and wrist) leads to solutions that are more aligned with what users prefer.