 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Zhu
Common Ground Tracking in Multimodal Dialogue
Mar 26, 2024

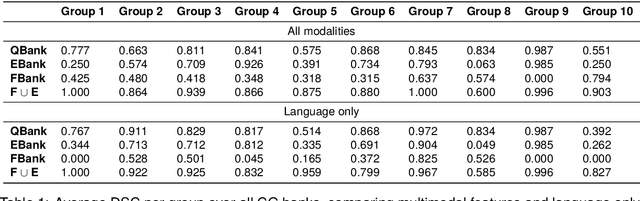


Within Dialogue Modeling research in AI and NLP, considerable attention has been spent on ``dialogue state tracking'' (DST), which is the ability to update the representations of the speaker's needs at each turn in the dialogue by taking into account the past dialogue moves and history. Less studied but just as important to dialogue modeling, however, is ``common ground tracking'' (CGT), which identifies the shared belief space held by all of the participants in a task-oriented dialogue: the task-relevant propositions all participants accept as true. In this paper we present a method for automatically identifying the current set of shared beliefs and ``questions under discussion'' (QUDs) of a group with a shared goal. We annotate a dataset of multimodal interactions in a shared physical space with speech transcriptions, prosodic features, gestures, actions, and facets of collaboration, and operationalize these features for use in a deep neural model to predict moves toward construction of common ground. Model outputs cascade into a set of formal closure rules derived from situated evidence and belief axioms and update operations. We empirically assess the contribution of each feature type toward successful construction of common ground relative to ground truth, establishing a benchmark in this novel, challenging task.
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.
Semantic Object-level Modeling for Robust Visual Camera Relocalization
Feb 10, 2024Visual relocalization is crucial for autonomous visual localization and navigation of mobile robotics. Due to the improvement of CNN-based object detection algorithm, the robustness of visual relocalization is greatly enhanced especially in viewpoints where classical methods fail. However, ellipsoids (quadrics) generated by axis-aligned object detection may limit the accuracy of the object-level representation and degenerate the performance of visual relocalization system. In this paper, we propose a novel method of automatic object-level voxel modeling for accurate ellipsoidal representations of objects. As for visual relocalization, we design a better pose optimization strategy for camera pose recovery, to fully utilize the projection characteristics of 2D fitted ellipses and the 3D accurate ellipsoids. All of these modules are entirely intergrated into visual SLAM system. Experimental results show that our semantic object-level mapping and object-based visual relocalization methods significantly enhance the performance of visual relocalization in terms of robustness to new viewpoints.
Efficient Availability Attacks against Supervised and Contrastive Learning Simultaneously
Feb 06, 2024Availability attacks can prevent the unauthorized use of private data and commercial datasets by generating imperceptible noise and making unlearnable examples before release. Ideally, the obtained unlearnability prevents algorithms from training usable models. When supervised learning (SL) algorithms have failed, a malicious data collector possibly resorts to contrastive learning (CL) algorithms to bypass the protection. Through evaluation, we have found that most of the existing methods are unable to achieve both supervised and contrastive unlearnability, which poses risks to data protection. Different from recent methods based on contrastive error minimization, we employ contrastive-like data augmentations in supervised error minimization or maximization frameworks to obtain attacks effective for both SL and CL. Our proposed AUE and AAP attacks achieve state-of-the-art worst-case unlearnability across SL and CL algorithms with less computation consumption, showcasing prospects in real-world applications.
Detection and Defense of Unlearnable Examples
Dec 14, 2023Privacy preserving has become increasingly critical with the emergence of social media. Unlearnable examples have been proposed to avoid leaking personal information on the Internet by degrading generalization abilities of deep learning models. However, our study reveals that unlearnable examples are easily detectable. We provide theoretical results on linear separability of certain unlearnable poisoned dataset and simple network based detection methods that can identify all existing unlearnable examples, as demonstrated by extensive experiments. Detectability of unlearnable examples with simple networks motivates us to design a novel defense method. We propose using stronger data augmentations coupled with adversarial noises generated by simple networks, to degrade the detectability and thus provide effective defense against unlearnable examples with a lower cost. Adversarial training with large budgets is a widely-used defense method on unlearnable examples. We establish quantitative criteria between the poison and adversarial budgets which determine the existence of robust unlearnable examples or the failure of the adversarial defense.
Learning and Autonomy for Extraterrestrial Terrain Sampling: An Experience Report from OWLAT Deployment
Dec 04, 2023Extraterrestrial autonomous lander missions increasingly demand adaptive capabilities to handle the unpredictable and diverse nature of the terrain. This paper discusses the deployment of a Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa) trained model for terrain scooping tasks in Ocean Worlds Lander Autonomy Testbed (OWLAT) at NASA Jet Propulsion Laboratory. The CoDeGa-powered scooping strategy is designed to adapt to novel terrains, selecting scooping actions based on the available RGB-D image data and limited experience. The paper presents our experiences with transferring the scooping framework with CoDeGa-trained model from a low-fidelity testbed to the high-fidelity OWLAT testbed. Additionally, it validates the method's performance in novel, realistic environments, and shares the lessons learned from deploying learning-based autonomy algorithms for space exploration. Experimental results from OWLAT substantiate the efficacy of CoDeGa in rapidly adapting to unfamiliar terrains and effectively making autonomous decisions under considerable domain shifts, thereby endorsing its potential utility in future extraterrestrial missions.
Scalable CP Decomposition for Tensor Learning using GPU Tensor Cores
Nov 22, 2023
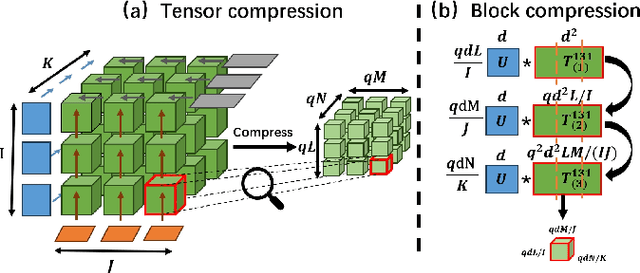
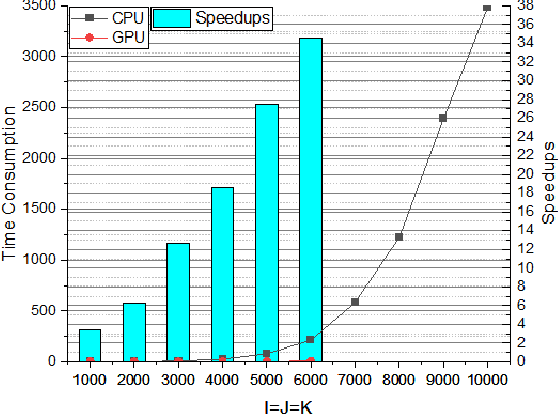

CP decomposition is a powerful tool for data science, especially gene analysis, deep learning, and quantum computation. However, the application of tensor decomposition is largely hindered by the exponential increment of the computational complexity and storage consumption with the size of tensors. While the data in our real world is usually presented as trillion- or even exascale-scale tensors, existing work can only support billion-scale scale tensors. In our work, we propose the Exascale-Tensor to mitigate the significant gap. Specifically, we propose a compression-based tensor decomposition framework, namely the exascale-tensor, to support exascale tensor decomposition. Then, we carefully analyze the inherent parallelism and propose a bag of strategies to improve computational efficiency. Last, we conduct experiments to decompose tensors ranging from million-scale to trillion-scale for evaluation. Compared to the baselines, the exascale-tensor supports 8,000x larger tensors and a speedup up to 6.95x. We also apply our method to two real-world applications, including gene analysis and tensor layer neural networks, of which the numeric results demonstrate the scalability and effectiveness of our method.
Human-Inspired Facial Sketch Synthesis with Dynamic Adaptation
Sep 01, 2023
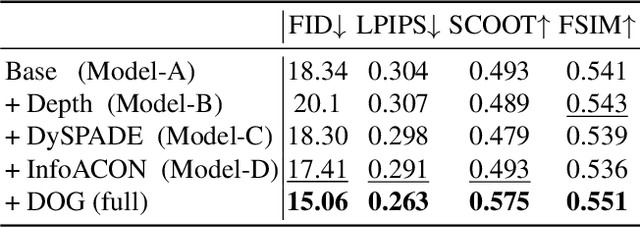
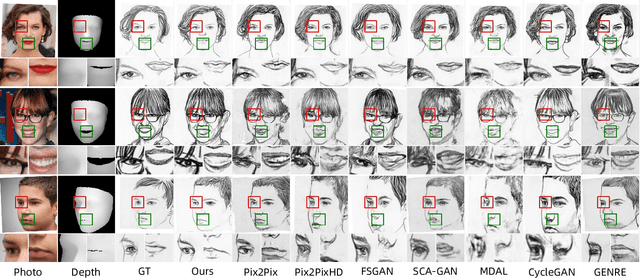
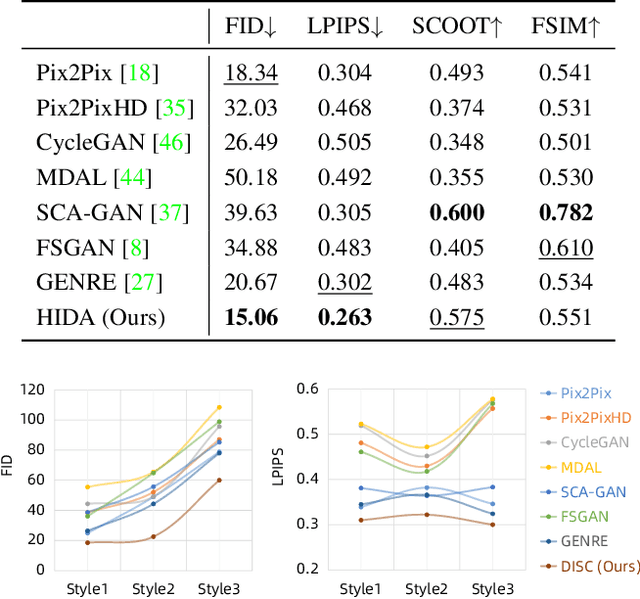
Facial sketch synthesis (FSS) aims to generate a vivid sketch portrait from a given facial photo. Existing FSS methods merely rely on 2D representations of facial semantic or appearance. However, professional human artists usually use outlines or shadings to covey 3D geometry. Thus facial 3D geometry (e.g. depth map) is extremely important for FSS. Besides, different artists may use diverse drawing techniques and create multiple styles of sketches; but the style is globally consistent in a sketch. Inspired by such observations, in this paper, we propose a novel Human-Inspired Dynamic Adaptation (HIDA) method. Specially, we propose to dynamically modulate neuron activations based on a joint consideration of both facial 3D geometry and 2D appearance, as well as globally consistent style control. Besides, we use deformable convolutions at coarse-scales to align deep features, for generating abstract and distinct outlines. Experiments show that HIDA can generate high-quality sketches in multiple styles, and significantly outperforms previous methods, over a large range of challenging faces. Besides, HIDA allows precise style control of the synthesized sketch, and generalizes well to natural scenes and other artistic styles. Our code and results have been released online at: https://github.com/AiArt-HDU/HIDA.
Continual Learning as Computationally Constrained Reinforcement Learning
Jul 10, 2023An agent that efficiently accumulates knowledge to develop increasingly sophisticated skills over a long lifetime could advance the frontier of artificial intelligence capabilities. The design of such agents, which remains a long-standing challenge of artificial intelligence, is addressed by the subject of continual learning. This monograph clarifies and formalizes concepts of continual learning, introducing a framework and set of tools to stimulate further research.
Looking Through the Glass: Neural Surface Reconstruction Against High Specular Reflections
Apr 18, 2023
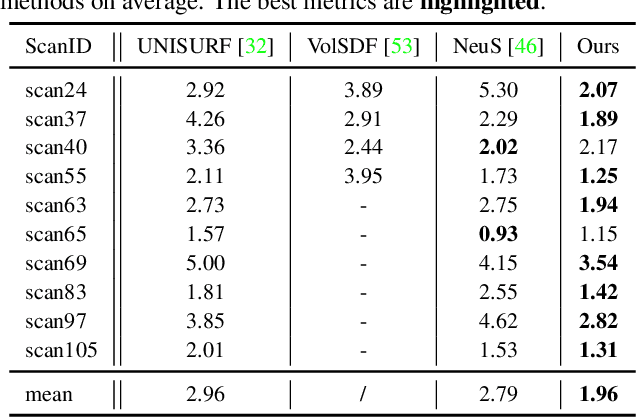


Neural implicit methods have achieved high-quality 3D object surfaces under slight specular highlights. However, high specular reflections (HSR) often appear in front of target objects when we capture them through glasses. The complex ambiguity in these scenes violates the multi-view consistency, then makes it challenging for recent methods to reconstruct target objects correctly. To remedy this issue, we present a novel surface reconstruction framework, NeuS-HSR, based on implicit neural rendering. In NeuS-HSR, the object surface is parameterized as an implicit signed distance function (SDF). To reduce the interference of HSR, we propose decomposing the rendered image into two appearances: the target object and the auxiliary plane. We design a novel auxiliary plane module by combining physical assumptions and neural networks to generate the auxiliary plane appearance. Extensive experiments on synthetic and real-world datasets demonstrate that NeuS-HSR outperforms state-of-the-art approaches for accurate and robust target surface reconstruction against HSR. Code is available at https://github.com/JiaxiongQ/NeuS-HSR.