 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXinyu Guan
OAG-Bench: A Human-Curated Benchmark for Academic Graph Mining
Feb 24, 2024
With the rapid proliferation of scientific literature, versatile academic knowledge services increasingly rely on comprehensive academic graph mining. Despite the availability of public academic graphs, benchmarks, and datasets, these resources often fall short in multi-aspect and fine-grained annotations, are constrained to specific task types and domains, or lack underlying real academic graphs. In this paper, we present OAG-Bench, a comprehensive, multi-aspect, and fine-grained human-curated benchmark based on the Open Academic Graph (OAG). OAG-Bench covers 10 tasks, 20 datasets, 70+ baselines, and 120+ experimental results to date. We propose new data annotation strategies for certain tasks and offer a suite of data pre-processing codes, algorithm implementations, and standardized evaluation protocols to facilitate academic graph mining. Extensive experiments reveal that even advanced algorithms like large language models (LLMs) encounter difficulties in addressing key challenges in certain tasks, such as paper source tracing and scholar profiling. We also introduce the Open Academic Graph Challenge (OAG-Challenge) to encourage community input and sharing. We envisage that OAG-Bench can serve as a common ground for the community to evaluate and compare algorithms in academic graph mining, thereby accelerating algorithm development and advancement in this field. OAG-Bench is accessible at https://www.aminer.cn/data/.
GOAL: A Challenging Knowledge-grounded Video Captioning Benchmark for Real-time Soccer Commentary Generation
Mar 26, 2023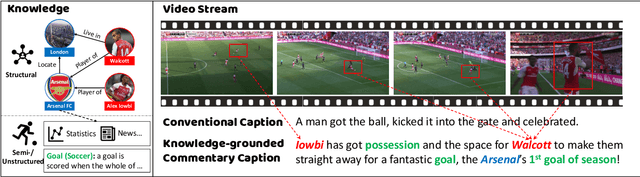
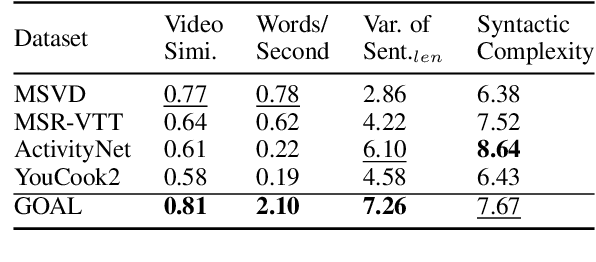
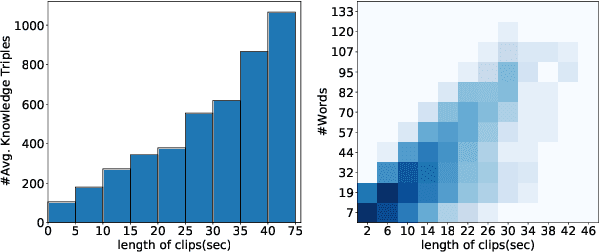
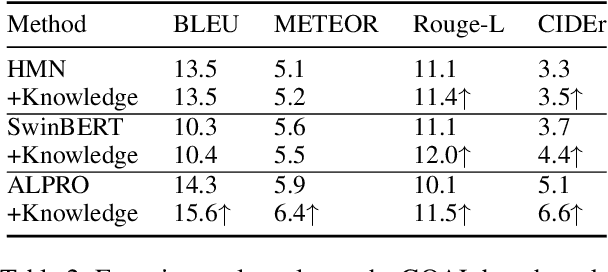
Despite the recent emergence of video captioning models, how to generate vivid, fine-grained video descriptions based on the background knowledge (i.e., long and informative commentary about the domain-specific scenes with appropriate reasoning) is still far from being solved, which however has great applications such as automatic sports narrative. In this paper, we present GOAL, a benchmark of over 8.9k soccer video clips, 22k sentences, and 42k knowledge triples for proposing a challenging new task setting as Knowledge-grounded Video Captioning (KGVC). Moreover, we conduct experimental adaption of existing methods to show the difficulty and potential directions for solving this valuable and applicable task.
Polycentric Clustering and Structural Regularization for Source-free Unsupervised Domain Adaptation
Oct 14, 2022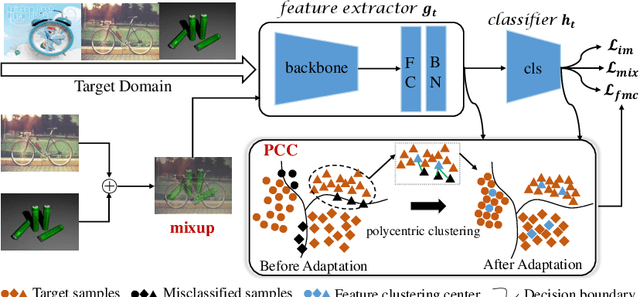
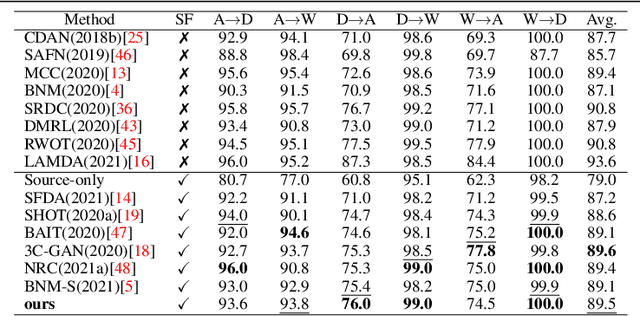
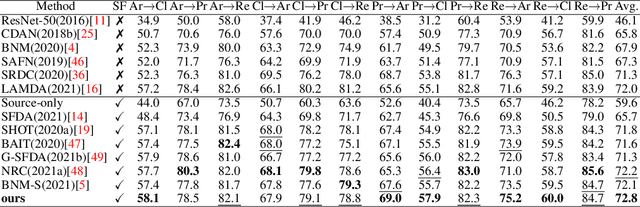
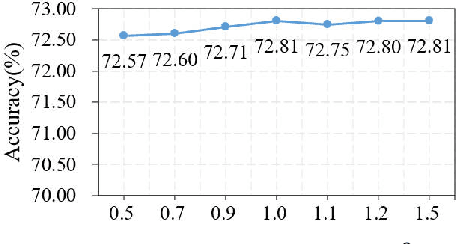
Source-Free Domain Adaptation (SFDA) aims to solve the domain adaptation problem by transferring the knowledge learned from a pre-trained source model to an unseen target domain. Most existing methods assign pseudo-labels to the target data by generating feature prototypes. However, due to the discrepancy in the data distribution between the source domain and the target domain and category imbalance in the target domain, there are severe class biases in the generated feature prototypes and noisy pseudo-labels. Besides, the data structure of the target domain is often ignored, which is crucial for clustering. In this paper, a novel framework named PCSR is proposed to tackle SFDA via a novel intra-class Polycentric Clustering and Structural Regularization strategy. Firstly, an inter-class balanced sampling strategy is proposed to generate representative feature prototypes for each class. Furthermore, k-means clustering is introduced to generate multiple clustering centers for each class in the target domain to obtain robust pseudo-labels. Finally, to enhance the model's generalization, structural regularization is introduced for the target domain. Extensive experiments on three UDA benchmark datasets show that our method performs better or similarly against the other state of the art methods, demonstrating our approach's superiority for visual domain adaptation problems.
TDGIA:Effective Injection Attacks on Graph Neural Networks
Jun 12, 2021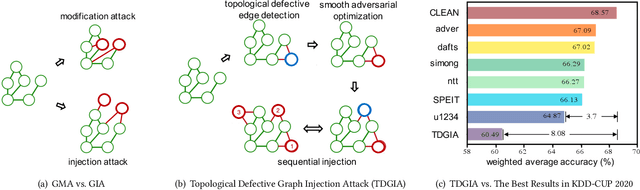
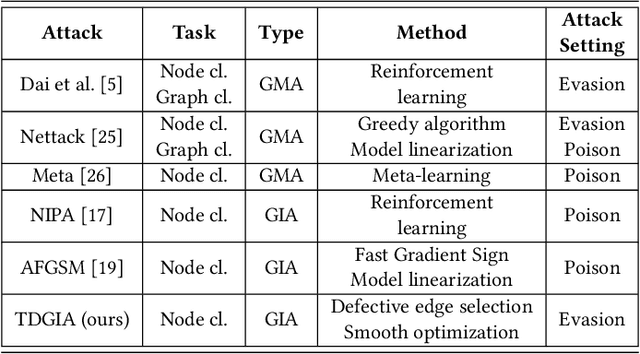
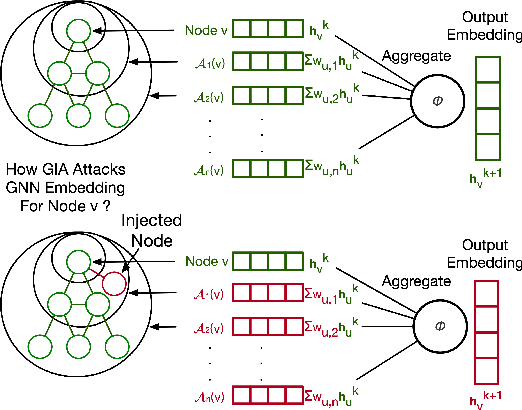

Graph Neural Networks (GNNs) have achieved promising performance in various real-world applications. However, recent studies have shown that GNNs are vulnerable to adversarial attacks. In this paper, we study a recently-introduced realistic attack scenario on graphs -- graph injection attack (GIA). In the GIA scenario, the adversary is not able to modify the existing link structure and node attributes of the input graph, instead the attack is performed by injecting adversarial nodes into it. We present an analysis on the topological vulnerability of GNNs under GIA setting, based on which we propose the Topological Defective Graph Injection Attack (TDGIA) for effective injection attacks. TDGIA first introduces the topological defective edge selection strategy to choose the original nodes for connecting with the injected ones. It then designs the smooth feature optimization objective to generate the features for the injected nodes. Extensive experiments on large-scale datasets show that TDGIA can consistently and significantly outperform various attack baselines in attacking dozens of defense GNN models. Notably, the performance drop on target GNNs resultant from TDGIA is more than double the damage brought by the best attack solution among hundreds of submissions on KDD-CUP 2020.
Machine Learning for Exam Triage
Apr 30, 2018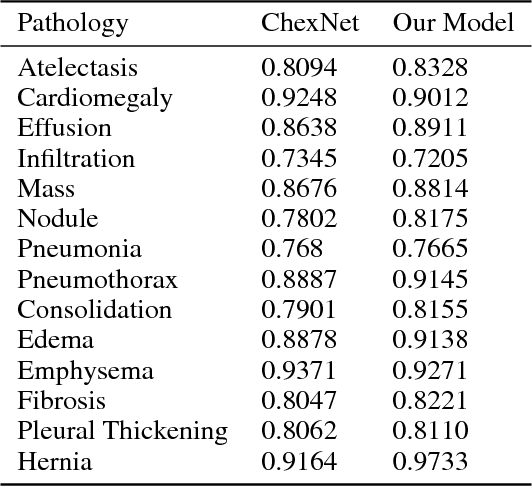
In this project, we extend the state-of-the-art CheXNet (Rajpurkar et al. [2017]) by making use of the additional non-image features in the dataset. Our model produced better AUROC scores than the original CheXNet.