 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuahui Yi
ConES: Concept Embedding Search for Parameter Efficient Tuning Large Vision Language Models
May 30, 2023

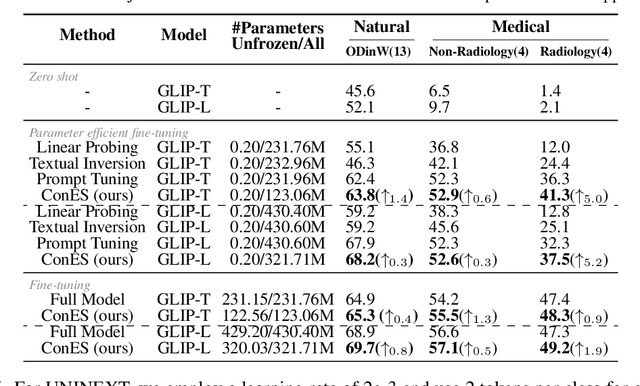
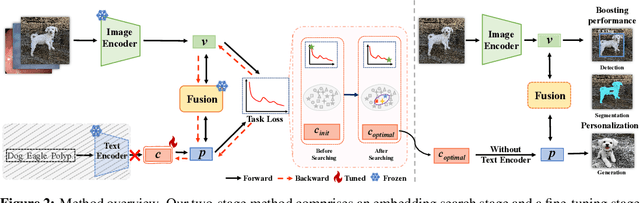
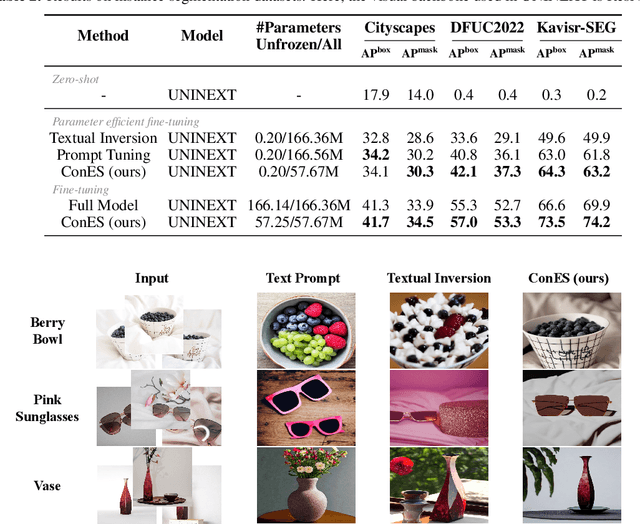
Large pre-trained vision-language models have shown great prominence in transferring pre-acquired knowledge to various domains and downstream tasks with appropriate prompting or tuning. Existing prevalent tuning methods can be generally categorized into three genres: 1) prompt engineering by creating suitable prompt texts, which is time-consuming and requires domain expertise; 2) or simply fine-tuning the whole model, which is extremely inefficient; 3) prompt tuning through parameterized prompt embeddings with the text encoder. Nevertheless, all methods rely on the text encoder for bridging the modality gap between vision and language. In this work, we question the necessity of the cumbersome text encoder for a more lightweight and efficient tuning paradigm as well as more representative prompt embeddings closer to the image representations. To achieve this, we propose a Concept Embedding Search (ConES) approach by optimizing prompt embeddings -- without the need of the text encoder -- to capture the 'concept' of the image modality through a variety of task objectives. By dropping the text encoder, we are able to significantly speed up the learning process, \eg, from about an hour to just ten minutes in our experiments for personalized text-to-image generation without impairing the generation quality. Moreover, our proposed approach is orthogonal to current existing tuning methods since the searched concept embeddings can be further utilized in the next stage of fine-tuning the pre-trained large models for boosting performance. Extensive experiments show that our approach can beat the prompt tuning and textual inversion methods in a variety of downstream tasks including objection detection, instance segmentation, and image generation. Our approach also shows better generalization capability for unseen concepts in specialized domains, such as the medical domain.
Towards General Purpose Medical AI: Continual Learning Medical Foundation Model
Mar 12, 2023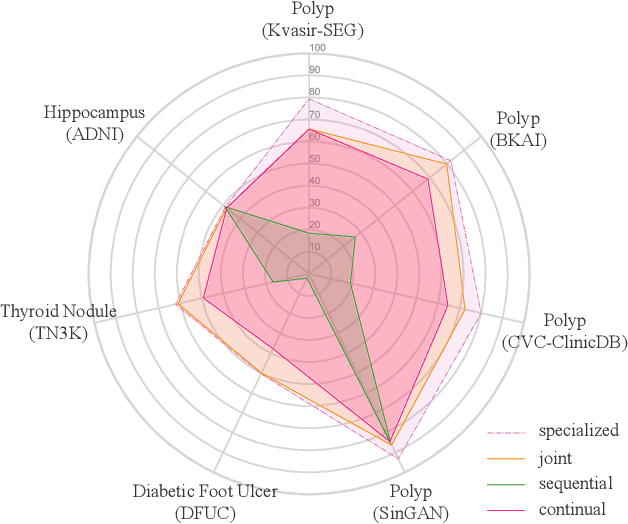
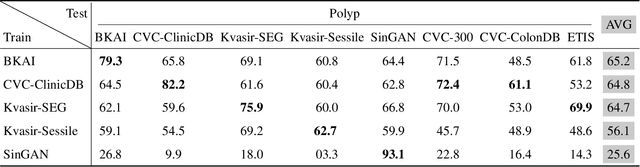
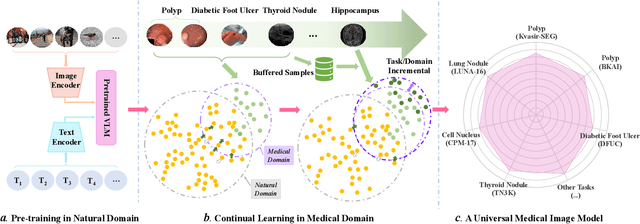
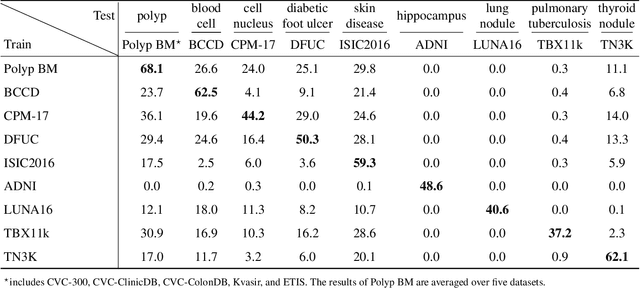
Inevitable domain and task discrepancies in real-world scenarios can impair the generalization performance of the pre-trained deep models for medical data. Therefore, we audaciously propose that we should build a general-purpose medical AI system that can be seamlessly adapted to downstream domains/tasks. Since the domain/task adaption procedures usually involve additional labeling work for the target data, designing a data-efficient adaption algorithm is desired to save the cost of transferring the learned knowledge. Our recent work found that vision-language models (VLMs) are efficient learners with extraordinary cross-domain ability. Therefore, in this work, we further explore the possibility of leveraging pre-trained VLMs as medical foundation models for building general-purpose medical AI, where we thoroughly investigate three machine-learning paradigms, i.e., domain/task-specialized learning, joint learning, and continual learning, for training the VLMs and evaluate their generalization performance on cross-domain and cross-task test sets. To alleviate the catastrophic forgetting during sequential training, we employ rehearsal learning and receive a sharp boost in terms of generalization capability. In a nutshell, our empirical evidence suggests that continual learning may be a practical and efficient learning paradigm for the medical foundation model. And we hope researchers can use our empirical evidence as basement to further explore the path toward medical foundation model.
Medical Image Understanding with Pretrained Vision Language Models: A Comprehensive Study
Sep 30, 2022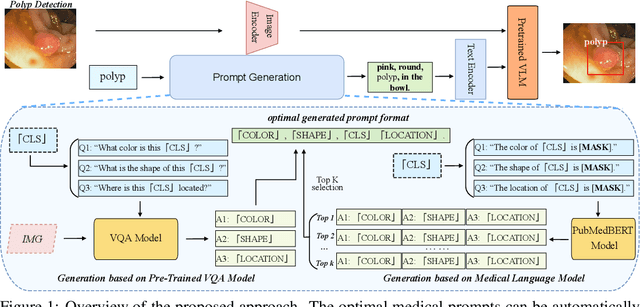
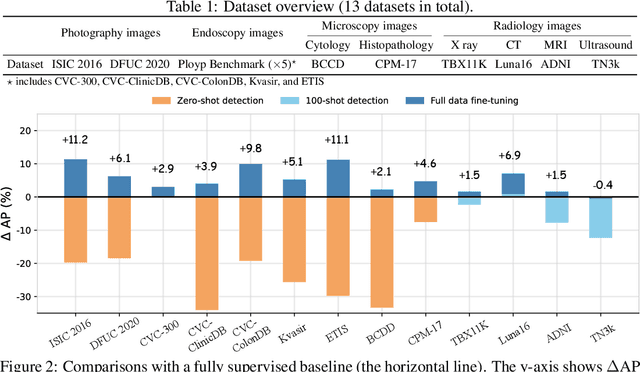

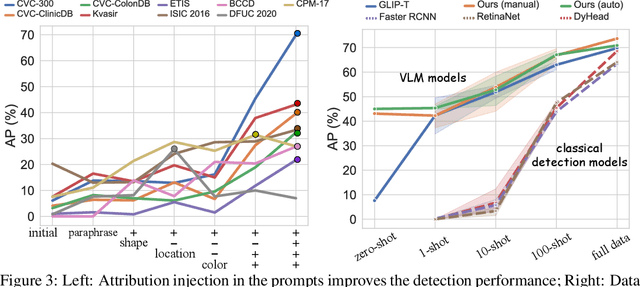
The large-scale pre-trained vision language models (VLM) have shown remarkable domain transfer capability on natural images. However, it remains unknown whether this capability can also apply to the medical image domain. This paper thoroughly studies the knowledge transferability of pre-trained VLMs to the medical domain, where we show that well-designed medical prompts are the key to elicit knowledge from pre-trained VLMs. We demonstrate that by prompting with expressive attributes that are shared between domains, the VLM can carry the knowledge across domains and improve its generalization. This mechanism empowers VLMs to recognize novel objects with fewer or without image samples. Furthermore, to avoid the laborious manual designing process, we develop three approaches for automatic generation of medical prompts, which can inject expert-level medical knowledge and image-specific information into the prompts for fine-grained grounding. We conduct extensive experiments on thirteen different medical datasets across various modalities, showing that our well-designed prompts greatly improve the zero-shot performance compared to the default prompts, and our fine-tuned models surpass the supervised models by a significant margin.