 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuazhong Yang
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Apr 08, 2024
Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$\times$ on CIFAR-10 and 15$\times$ on ImageNet-64). $\textbf{(b) Enhancing pre-trained models.}$ Assuming full training is already done, LCSC can further improve the generation quality or speed of the final converged models. For example, LCSC achieves better performance using 1 number of function evaluation (NFE) than the base model with 2 NFE on consistency distillation, and decreases the NFE of DM from 15 to 9 while maintaining the generation quality on CIFAR-10. Our code is available at https://github.com/imagination-research/LCSC.
FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models
Mar 25, 2024In recent years, there has been significant progress in the development of text-to-image generative models. Evaluating the quality of the generative models is one essential step in the development process. Unfortunately, the evaluation process could consume a significant amount of computational resources, making the required periodic evaluation of model performance (e.g., monitoring training progress) impractical. Therefore, we seek to improve the evaluation efficiency by selecting the representative subset of the text-image dataset. We systematically investigate the design choices, including the selection criteria (textural features or image-based metrics) and the selection granularity (prompt-level or set-level). We find that the insights from prior work on subset selection for training data do not generalize to this problem, and we propose FlashEval, an iterative search algorithm tailored to evaluation data selection. We demonstrate the effectiveness of FlashEval on ranking diffusion models with various configurations, including architectures, quantization levels, and sampler schedules on COCO and DiffusionDB datasets. Our searched 50-item subset could achieve comparable evaluation quality to the randomly sampled 500-item subset for COCO annotations on unseen models, achieving a 10x evaluation speedup. We release the condensed subset of these commonly used datasets to help facilitate diffusion algorithm design and evaluation, and open-source FlashEval as a tool for condensing future datasets, accessible at https://github.com/thu-nics/FlashEval.
Evaluating Quantized Large Language Models
Feb 28, 2024Post-training quantization (PTQ) has emerged as a promising technique to reduce the cost of large language models (LLMs). Specifically, PTQ can effectively mitigate memory consumption and reduce computational overhead in LLMs. To meet the requirements of both high efficiency and performance across diverse scenarios, a comprehensive evaluation of quantized LLMs is essential to guide the selection of quantization methods. This paper presents a thorough evaluation of these factors by evaluating the effect of PTQ on Weight, Activation, and KV Cache on 11 model families, including OPT, LLaMA2, Falcon, Bloomz, Mistral, ChatGLM, Vicuna, LongChat, StableLM, Gemma, and Mamba, with parameters ranging from 125M to 180B. The evaluation encompasses five types of tasks: basic NLP, emergent ability, trustworthiness, dialogue, and long-context tasks. Moreover, we also evaluate the state-of-the-art (SOTA) quantization methods to demonstrate their applicability. Based on the extensive experiments, we systematically summarize the effect of quantization, provide recommendations to apply quantization techniques, and point out future directions.
TaskFlex Solver for Multi-Agent Pursuit via Automatic Curriculum Learning
Dec 19, 2023This paper addresses the problem of multi-agent pursuit, where slow pursuers cooperate to capture fast evaders in a confined environment with obstacles. Existing heuristic algorithms often lack expressive coordination strategies and are highly sensitive to task conditions, requiring extensive hyperparameter tuning. In contrast, reinforcement learning (RL) has been applied to this problem and is capable of obtaining cooperative pursuit strategies. However, RL-based methods face challenges in training for complex scenarios due to the vast amount of training data and limited adaptability to varying task conditions, such as different scene sizes, varying numbers and speeds of obstacles, and flexible speed ratios of the evader to the pursuer. In this work, we combine RL and curriculum learning to introduce a flexible solver for multiagent pursuit problems, named TaskFlex Solver (TFS), which is capable of solving multi-agent pursuit problems with diverse and dynamically changing task conditions in both 2-dimensional and 3-dimensional scenarios. TFS utilizes a curriculum learning method that constructs task distributions based on training progress, enhancing training efficiency and final performance. Our algorithm consists of two main components: the Task Evaluator, which evaluates task success rates and selects tasks of moderate difficulty to maintain a curriculum archive, and the Task Sampler, which constructs training distributions by sampling tasks from the curriculum archive to maximize policy improvement. Experiments show that TFS produces much stronger performance than baselines and achieves close to 100% capture rates in both 2-dimensional and 3-dimensional multi-agent pursuit problems with diverse and dynamically changing scenes. The project website is at https://sites.google.com/view/tfs-2023.
A Unified Sampling Framework for Solver Searching of Diffusion Probabilistic Models
Dec 12, 2023Recent years have witnessed the rapid progress and broad application of diffusion probabilistic models (DPMs). Sampling from DPMs can be viewed as solving an ordinary differential equation (ODE). Despite the promising performance, the generation of DPMs usually consumes much time due to the large number of function evaluations (NFE). Though recent works have accelerated the sampling to around 20 steps with high-order solvers, the sample quality with less than 10 NFE can still be improved. In this paper, we propose a unified sampling framework (USF) to study the optional strategies for solver. Under this framework, we further reveal that taking different solving strategies at different timesteps may help further decrease the truncation error, and a carefully designed \emph{solver schedule} has the potential to improve the sample quality by a large margin. Therefore, we propose a new sampling framework based on the exponential integral formulation that allows free choices of solver strategy at each step and design specific decisions for the framework. Moreover, we propose $S^3$, a predictor-based search method that automatically optimizes the solver schedule to get a better time-quality trade-off of sampling. We demonstrate that $S^3$ can find outstanding solver schedules which outperform the state-of-the-art sampling methods on CIFAR-10, CelebA, ImageNet, and LSUN-Bedroom datasets. Specifically, we achieve 2.69 FID with 10 NFE and 6.86 FID with 5 NFE on CIFAR-10 dataset, outperforming the SOTA method significantly. We further apply $S^3$ to Stable-Diffusion model and get an acceleration ratio of 2$\times$, showing the feasibility of sampling in very few steps without retraining the neural network.
MASP: Scalable GNN-based Planning for Multi-Agent Navigation
Dec 05, 2023We investigate the problem of decentralized multi-agent navigation tasks, where multiple agents need to reach initially unassigned targets in a limited time. Classical planning-based methods suffer from expensive computation overhead at each step and offer limited expressiveness for complex cooperation strategies. In contrast, reinforcement learning (RL) has recently become a popular paradigm for addressing this issue. However, RL struggles with low data efficiency and cooperation when directly exploring (nearly) optimal policies in the large search space, especially with an increased agent number (e.g., 10+ agents) or in complex environments (e.g., 3D simulators). In this paper, we propose Multi-Agent Scalable GNN-based P lanner (MASP), a goal-conditioned hierarchical planner for navigation tasks with a substantial number of agents. MASP adopts a hierarchical framework to divide a large search space into multiple smaller spaces, thereby reducing the space complexity and accelerating training convergence. We also leverage graph neural networks (GNN) to model the interaction between agents and goals, improving goal achievement. Besides, to enhance generalization capabilities in scenarios with unseen team sizes, we divide agents into multiple groups, each with a previously trained number of agents. The results demonstrate that MASP outperforms classical planning-based competitors and RL baselines, achieving a nearly 100% success rate with minimal training data in both multi-agent particle environments (MPE) with 50 agents and a quadrotor 3-dimensional environment (OmniDrones) with 20 agents. Furthermore, the learned policy showcases zero-shot generalization across unseen team sizes.
Active Neural Topological Mapping for Multi-Agent Exploration
Nov 01, 2023This paper investigates the multi-agent cooperative exploration problem, which requires multiple agents to explore an unseen environment via sensory signals in a limited time. A popular approach to exploration tasks is to combine active mapping with planning. Metric maps capture the details of the spatial representation, but are with high communication traffic and may vary significantly between scenarios, resulting in inferior generalization. Topological maps are a promising alternative as they consist only of nodes and edges with abstract but essential information and are less influenced by the scene structures. However, most existing topology-based exploration tasks utilize classical methods for planning, which are time-consuming and sub-optimal due to their handcrafted design. Deep reinforcement learning (DRL) has shown great potential for learning (near) optimal policies through fast end-to-end inference. In this paper, we propose Multi-Agent Neural Topological Mapping (MANTM) to improve exploration efficiency and generalization for multi-agent exploration tasks. MANTM mainly comprises a Topological Mapper and a novel RL-based Hierarchical Topological Planner (HTP). The Topological Mapper employs a visual encoder and distance-based heuristics to construct a graph containing main nodes and their corresponding ghost nodes. The HTP leverages graph neural networks to capture correlations between agents and graph nodes in a coarse-to-fine manner for effective global goal selection. Extensive experiments conducted in a physically-realistic simulator, Habitat, demonstrate that MANTM reduces the steps by at least 26.40% over planning-based baselines and by at least 7.63% over RL-based competitors in unseen scenarios.
Accelerate Multi-Agent Reinforcement Learning in Zero-Sum Games with Subgame Curriculum Learning
Oct 07, 2023

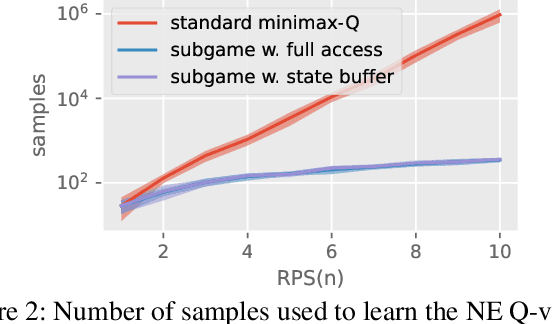

Learning Nash equilibrium (NE) in complex zero-sum games with multi-agent reinforcement learning (MARL) can be extremely computationally expensive. Curriculum learning is an effective way to accelerate learning, but an under-explored dimension for generating a curriculum is the difficulty-to-learn of the subgames -- games induced by starting from a specific state. In this work, we present a novel subgame curriculum learning framework for zero-sum games. It adopts an adaptive initial state distribution by resetting agents to some previously visited states where they can quickly learn to improve performance. Building upon this framework, we derive a subgame selection metric that approximates the squared distance to NE values and further adopt a particle-based state sampler for subgame generation. Integrating these techniques leads to our new algorithm, Subgame Automatic Curriculum Learning (SACL), which is a realization of the subgame curriculum learning framework. SACL can be combined with any MARL algorithm such as MAPPO. Experiments in the particle-world environment and Google Research Football environment show SACL produces much stronger policies than baselines. In the challenging hide-and-seek quadrant environment, SACL produces all four emergent stages and uses only half the samples of MAPPO with self-play. The project website is at https://sites.google.com/view/sacl-rl.
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
Jul 28, 2023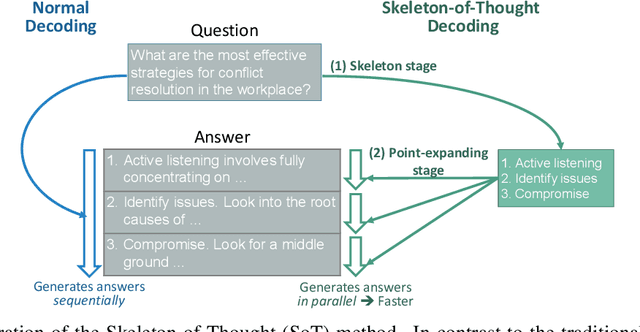

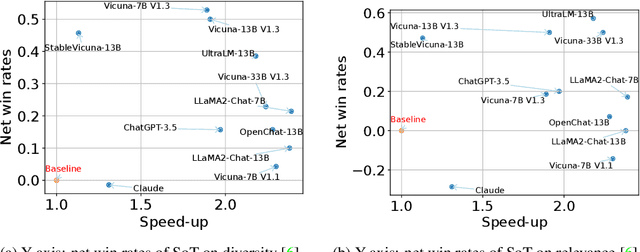
This work aims at decreasing the end-to-end generation latency of large language models (LLMs). One of the major causes of the high generation latency is the sequential decoding approach adopted by almost all state-of-the-art LLMs. In this work, motivated by the thinking and writing process of humans, we propose "Skeleton-of-Thought" (SoT), which guides LLMs to first generate the skeleton of the answer, and then conducts parallel API calls or batched decoding to complete the contents of each skeleton point in parallel. Not only does SoT provide considerable speed-up (up to 2.39x across 11 different LLMs), but it can also potentially improve the answer quality on several question categories in terms of diversity and relevance. SoT is an initial attempt at data-centric optimization for efficiency, and reveal the potential of pushing LLMs to think more like a human for answer quality.
Ada3D : Exploiting the Spatial Redundancy with Adaptive Inference for Efficient 3D Object Detection
Jul 17, 2023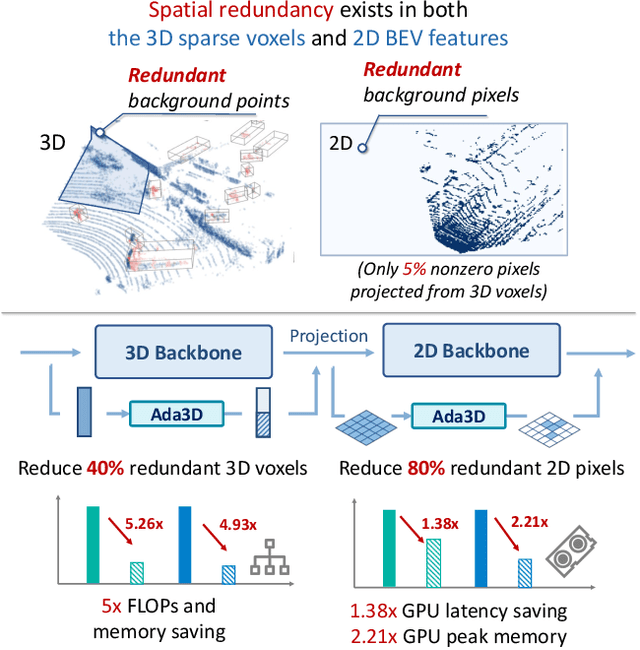
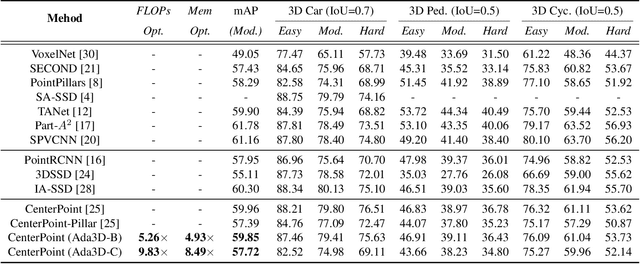
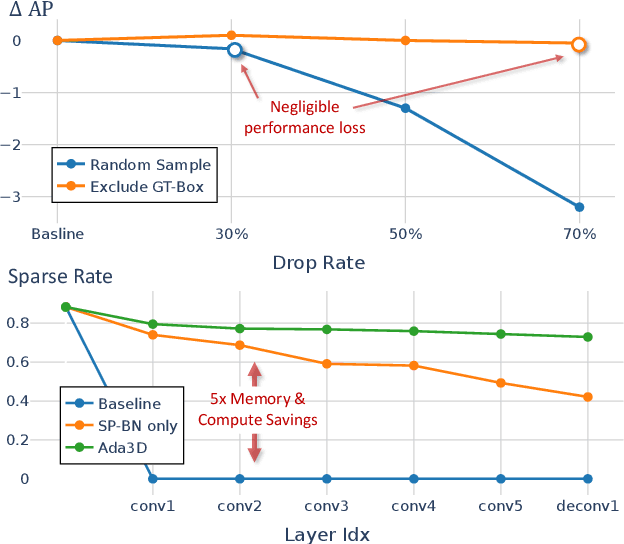
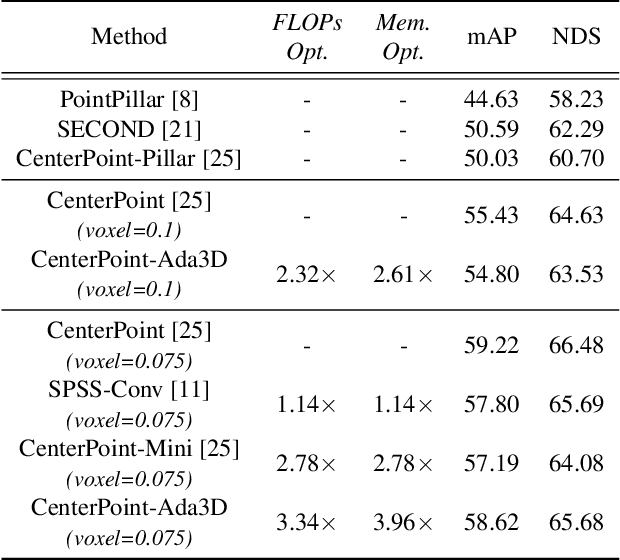
Voxel-based methods have achieved state-of-the-art performance for 3D object detection in autonomous driving. However, their significant computational and memory costs pose a challenge for their application to resource-constrained vehicles. One reason for this high resource consumption is the presence of a large number of redundant background points in Lidar point clouds, resulting in spatial redundancy in both 3D voxel and dense BEV map representations. To address this issue, we propose an adaptive inference framework called Ada3D, which focuses on exploiting the input-level spatial redundancy. Ada3D adaptively filters the redundant input, guided by a lightweight importance predictor and the unique properties of the Lidar point cloud. Additionally, we utilize the BEV features' intrinsic sparsity by introducing the Sparsity Preserving Batch Normalization. With Ada3D, we achieve 40% reduction for 3D voxels and decrease the density of 2D BEV feature maps from 100% to 20% without sacrificing accuracy. Ada3D reduces the model computational and memory cost by 5x, and achieves 1.52x/1.45x end-to-end GPU latency and 1.5x/4.5x GPU peak memory optimization for the 3D and 2D backbone respectively.