 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJunyi Zhu
Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction
May 03, 2024
Computed Tomography (CT) is pivotal in industrial quality control and medical diagnostics. Sparse-view CT, offering reduced ionizing radiation, faces challenges due to its under-sampled nature, leading to ill-posed reconstruction problems. Recent advancements in Implicit Neural Representations (INRs) have shown promise in addressing sparse-view CT reconstruction. Recognizing that CT often involves scanning similar subjects, we propose a novel approach to improve reconstruction quality through joint reconstruction of multiple objects using INRs. This approach can potentially leverage both the strengths of INRs and the statistical regularities across multiple objects. While current INR joint reconstruction techniques primarily focus on accelerating convergence via meta-initialization, they are not specifically tailored to enhance reconstruction quality. To address this gap, we introduce a novel INR-based Bayesian framework integrating latent variables to capture the inter-object relationships. These variables serve as a dynamic reference throughout the optimization, thereby enhancing individual reconstruction fidelity. Our extensive experiments, which assess various key factors such as reconstruction quality, resistance to overfitting, and generalizability, demonstrate significant improvements over baselines in common numerical metrics. This underscores a notable advancement in CT reconstruction methods.
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Apr 08, 2024Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$\times$ on CIFAR-10 and 15$\times$ on ImageNet-64). $\textbf{(b) Enhancing pre-trained models.}$ Assuming full training is already done, LCSC can further improve the generation quality or speed of the final converged models. For example, LCSC achieves better performance using 1 number of function evaluation (NFE) than the base model with 2 NFE on consistency distillation, and decreases the NFE of DM from 15 to 9 while maintaining the generation quality on CIFAR-10. Our code is available at https://github.com/imagination-research/LCSC.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
Surrogate Model Extension (SME): A Fast and Accurate Weight Update Attack on Federated Learning
May 31, 2023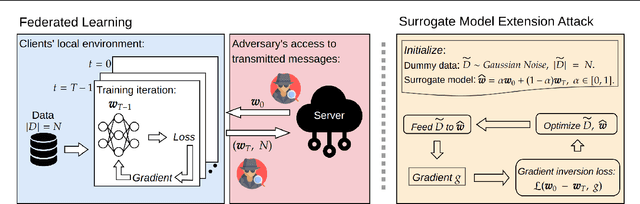

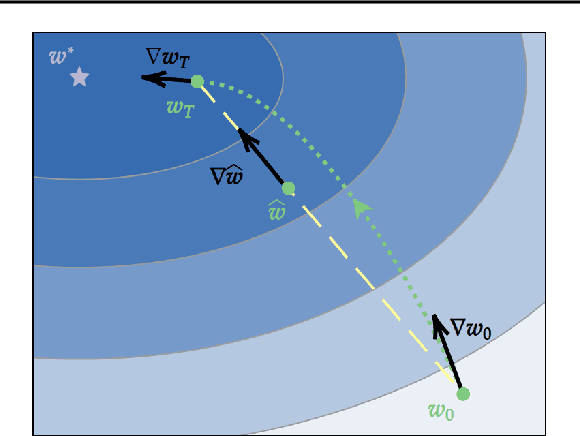
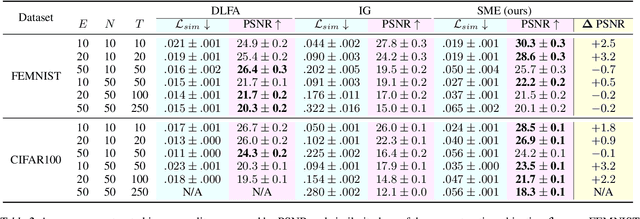
In Federated Learning (FL) and many other distributed training frameworks, collaborators can hold their private data locally and only share the network weights trained with the local data after multiple iterations. Gradient inversion is a family of privacy attacks that recovers data from its generated gradients. Seemingly, FL can provide a degree of protection against gradient inversion attacks on weight updates, since the gradient of a single step is concealed by the accumulation of gradients over multiple local iterations. In this work, we propose a principled way to extend gradient inversion attacks to weight updates in FL, thereby better exposing weaknesses in the presumed privacy protection inherent in FL. In particular, we propose a surrogate model method based on the characteristic of two-dimensional gradient flow and low-rank property of local updates. Our method largely boosts the ability of gradient inversion attacks on weight updates containing many iterations and achieves state-of-the-art (SOTA) performance. Additionally, our method runs up to $100\times$ faster than the SOTA baseline in the common FL scenario. Our work re-evaluates and highlights the privacy risk of sharing network weights. Our code is available at https://github.com/JunyiZhu-AI/surrogate_model_extension.
Confidence-aware Personalized Federated Learning via Variational Expectation Maximization
May 21, 2023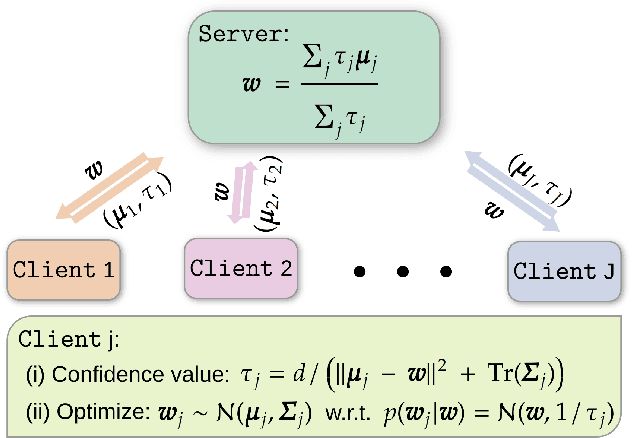
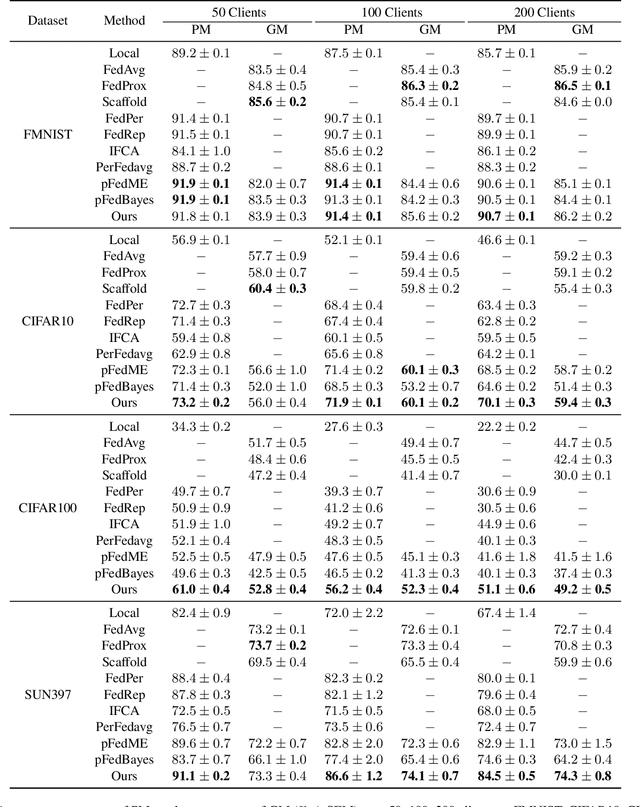
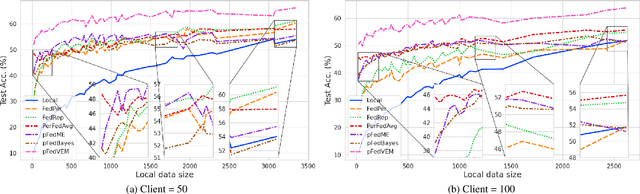

Federated Learning (FL) is a distributed learning scheme to train a shared model across clients. One common and fundamental challenge in FL is that the sets of data across clients could be non-identically distributed and have different sizes. Personalized Federated Learning (PFL) attempts to solve this challenge via locally adapted models. In this work, we present a novel framework for PFL based on hierarchical Bayesian modeling and variational inference. A global model is introduced as a latent variable to augment the joint distribution of clients' parameters and capture the common trends of different clients, optimization is derived based on the principle of maximizing the marginal likelihood and conducted using variational expectation maximization. Our algorithm gives rise to a closed-form estimation of a confidence value which comprises the uncertainty of clients' parameters and local model deviations from the global model. The confidence value is used to weigh clients' parameters in the aggregation stage and adjust the regularization effect of the global model. We evaluate our method through extensive empirical studies on multiple datasets. Experimental results show that our approach obtains competitive results under mild heterogeneous circumstances while significantly outperforming state-of-the-art PFL frameworks in highly heterogeneous settings. Our code is available at https://github.com/JunyiZhu-AI/confidence_aware_PFL.
Differentially Private SGD with Sparse Gradients
Dec 01, 2021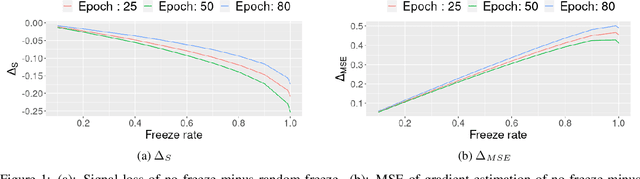
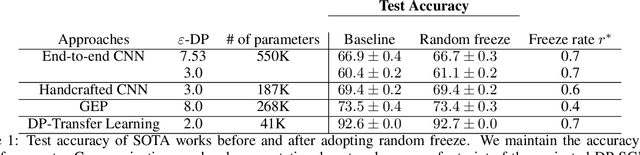
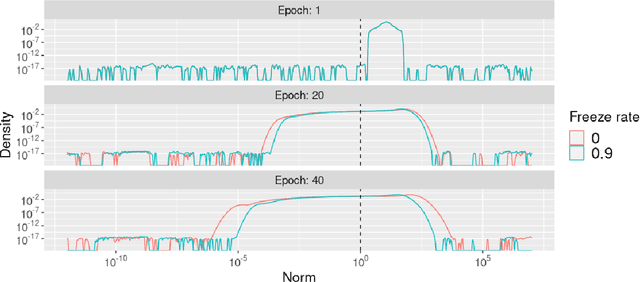
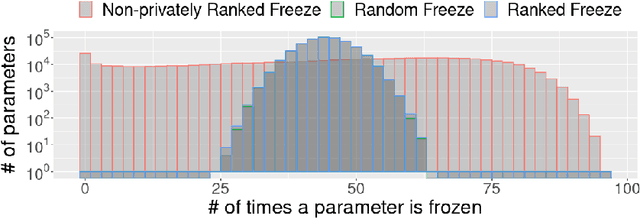
To protect sensitive training data, differentially private stochastic gradient descent (DP-SGD) has been adopted in deep learning to provide rigorously defined privacy. However, DP-SGD requires the injection of an amount of noise that scales with the number of gradient dimensions, resulting in large performance drops compared to non-private training. In this work, we propose random freeze which randomly freezes a progressively increasing subset of parameters and results in sparse gradient updates while maintaining or increasing accuracy. We theoretically prove the convergence of random freeze and find that random freeze exhibits a signal loss and perturbation moderation trade-off in DP-SGD. Applying random freeze across various DP-SGD frameworks, we maintain accuracy within the same number of iterations while achieving up to 70% representation sparsity, which demonstrates that the trade-off exists in a variety of DP-SGD methods. We further note that random freeze significantly improves accuracy, in particular for large networks. Additionally, axis-aligned sparsity induced by random freeze leads to various advantages for projected DP-SGD or federated learning in terms of computational cost, memory footprint and communication overhead.
R-GAP: Recursive Gradient Attack on Privacy
Oct 15, 2020
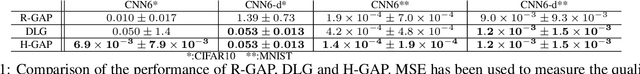


Federated learning frameworks have been regarded as a promising approach to break the dilemma between demands on privacy and the promise of learning from large collections of distributed data. Many such frameworks only ask collaborators to share their local update of a common model, i.e. gradients with respect to locally stored data, instead of exposing their raw data to other collaborators. However, recent optimization-based gradient attacks show that raw data can often be accurately recovered from gradients. It has been shown that minimizing the Euclidean distance between true gradients and those calculated from estimated data is often effective in fully recovering private data. However, there is a fundamental lack of theoretical understanding of how and when gradients can lead to unique recovery of original data. Our research fills this gap by providing a closed-form recursive procedure to recover data from gradients in deep neural networks. We demonstrate that gradient attacks consist of recursively solving a sequence of systems of linear equations. Furthermore, our closed-form approach works as well as or even better than optimization-based approaches at a fraction of the computation, we name it Recursive Gradient Attack on Privacy (R-GAP). Additionally, we propose a rank analysis method, which can be used to estimate a network architecture's risk of a gradient attack. Experimental results demonstrate the validity of the closed-form attack and rank analysis, while demonstrating its superior computational properties and lack of susceptibility to local optima vis a vis optimization-based attacks. Source code is available for download from https://github.com/JunyiZhu-AI/R-GAP.
Localization in Aerial Imagery with Grid Maps using LocGAN
Jun 04, 2019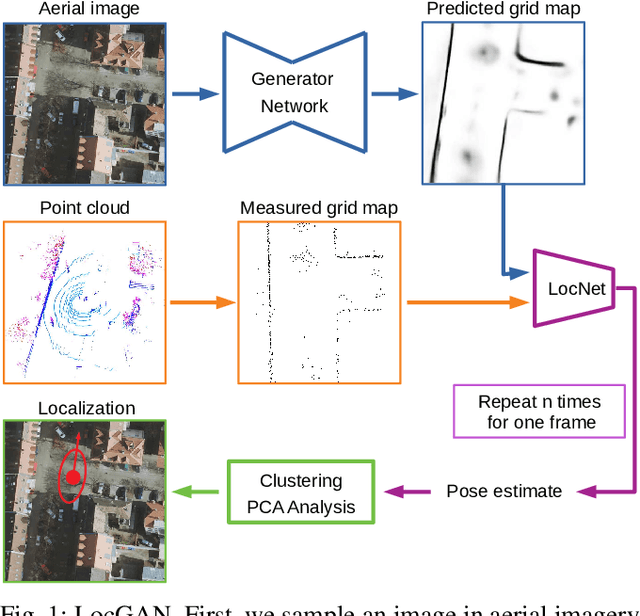
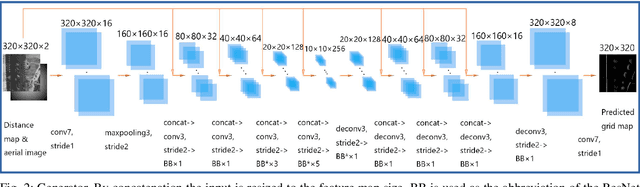
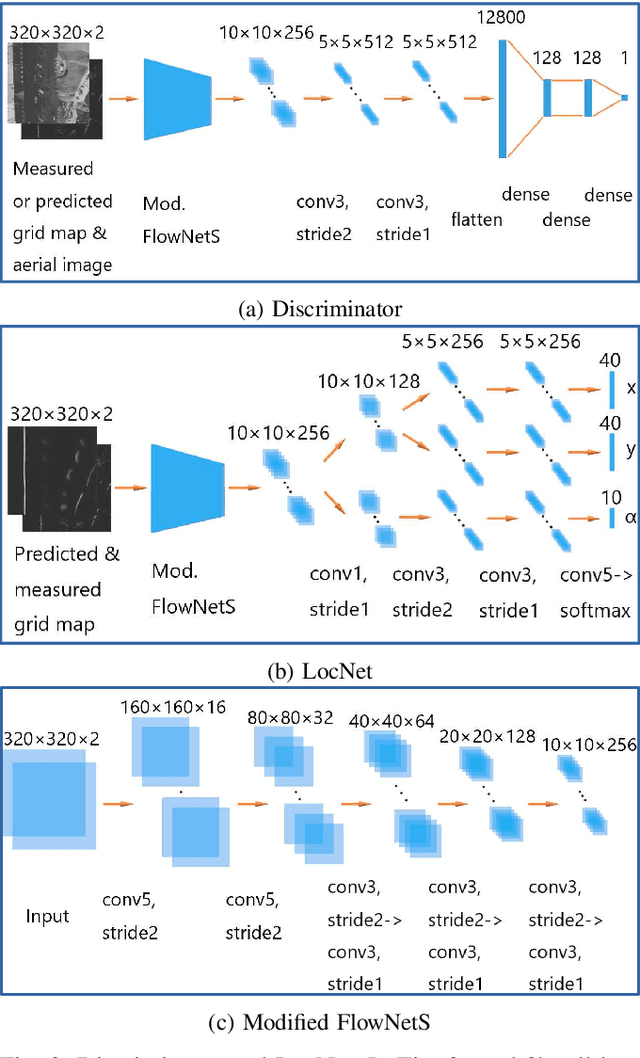
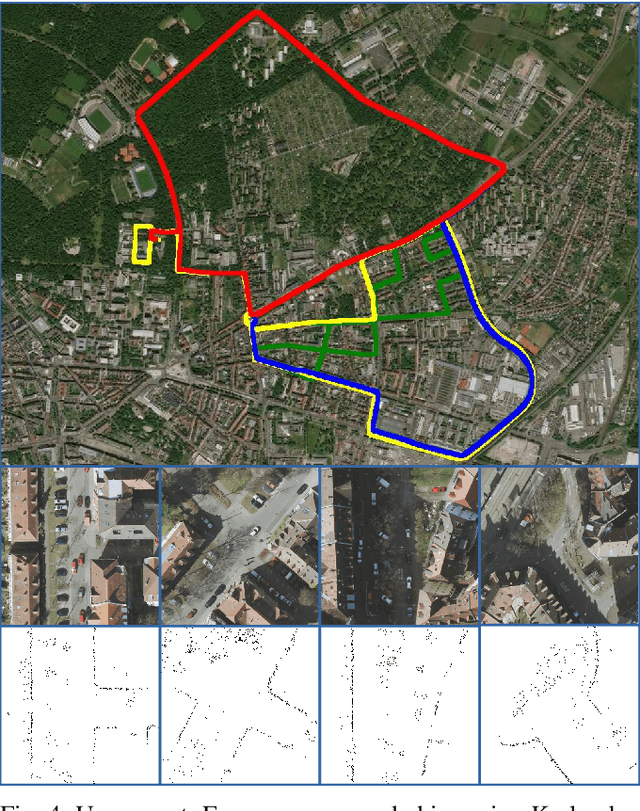
In this work, we present LocGAN, our localization approach based on a geo-referenced aerial imagery and LiDAR grid maps. Currently, most self-localization approaches relate the current sensor observations to a map generated from previously acquired data. Unfortunately, this data is not always available and the generated maps are usually sensor setup specific. Global Navigation Satellite Systems (GNSS) can overcome this problem. However, they are not always reliable especially in urban areas due to multi-path and shadowing effects. Since aerial imagery is usually available, we can use it as prior information. To match aerial images with grid maps, we use conditional Generative Adversarial Networks (cGANs) which transform aerial images to the grid map domain. The transformation between the predicted and measured grid map is estimated using a localization network (LocNet). Given the geo-referenced aerial image transformation the vehicle pose can be estimated. Evaluations performed on the data recorded in region Karlsruhe, Germany show that our LocGAN approach provides reliable global localization results.