 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuy Nguyen
On Parameter Estimation in Deviated Gaussian Mixture of Experts
Feb 07, 2024
We consider the parameter estimation problem in the deviated Gaussian mixture of experts in which the data are generated from $(1 - \lambda^{\ast}) g_0(Y| X)+ \lambda^{\ast} \sum_{i = 1}^{k_{\ast}} p_{i}^{\ast} f(Y|(a_{i}^{\ast})^{\top}X+b_i^{\ast},\sigma_{i}^{\ast})$, where $X, Y$ are respectively a covariate vector and a response variable, $g_{0}(Y|X)$ is a known function, $\lambda^{\ast} \in [0, 1]$ is true but unknown mixing proportion, and $(p_{i}^{\ast}, a_{i}^{\ast}, b_{i}^{\ast}, \sigma_{i}^{\ast})$ for $1 \leq i \leq k^{\ast}$ are unknown parameters of the Gaussian mixture of experts. This problem arises from the goodness-of-fit test when we would like to test whether the data are generated from $g_{0}(Y|X)$ (null hypothesis) or they are generated from the whole mixture (alternative hypothesis). Based on the algebraic structure of the expert functions and the distinguishability between $g_0$ and the mixture part, we construct novel Voronoi-based loss functions to capture the convergence rates of maximum likelihood estimation (MLE) for our models. We further demonstrate that our proposed loss functions characterize the local convergence rates of parameter estimation more accurately than the generalized Wasserstein, a loss function being commonly used for estimating parameters in the Gaussian mixture of experts.
On Least Squares Estimation in Softmax Gating Mixture of Experts
Feb 05, 2024Mixture of experts (MoE) model is a statistical machine learning design that aggregates multiple expert networks using a softmax gating function in order to form a more intricate and expressive model. Despite being commonly used in several applications owing to their scalability, the mathematical and statistical properties of MoE models are complex and difficult to analyze. As a result, previous theoretical works have primarily focused on probabilistic MoE models by imposing the impractical assumption that the data are generated from a Gaussian MoE model. In this work, we investigate the performance of the least squares estimators (LSE) under a deterministic MoE model where the data are sampled according to a regression model, a setting that has remained largely unexplored. We establish a condition called strong identifiability to characterize the convergence behavior of various types of expert functions. We demonstrate that the rates for estimating strongly identifiable experts, namely the widely used feed forward networks with activation functions $\mathrm{sigmoid}(\cdot)$ and $\tanh(\cdot)$, are substantially faster than those of polynomial experts, which we show to exhibit a surprising slow estimation rate. Our findings have important practical implications for expert selection.
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Feb 05, 2024As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in real world is validated by a challenging set of clinical risk prediction tasks.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024

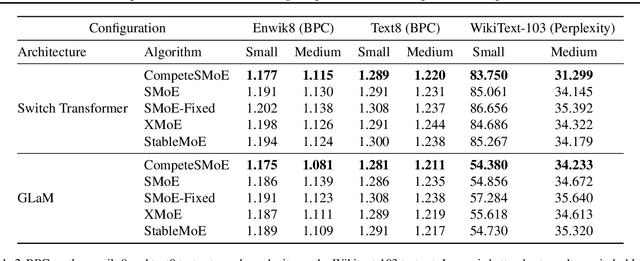

Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
Is Temperature Sample Efficient for Softmax Gaussian Mixture of Experts?
Jan 25, 2024Dense-to-sparse gating mixture of experts (MoE) has recently become an effective alternative to a well-known sparse MoE. Rather than fixing the number of activated experts as in the latter model, which could limit the investigation of potential experts, the former model utilizes the temperature to control the softmax weight distribution and the sparsity of the MoE during training in order to stabilize the expert specialization. Nevertheless, while there are previous attempts to theoretically comprehend the sparse MoE, a comprehensive analysis of the dense-to-sparse gating MoE has remained elusive. Therefore, we aim to explore the impacts of the dense-to-sparse gate on the maximum likelihood estimation under the Gaussian MoE in this paper. We demonstrate that due to interactions between the temperature and other model parameters via some partial differential equations, the convergence rates of parameter estimations are slower than any polynomial rates, and could be as slow as $\mathcal{O}(1/\log(n))$, where $n$ denotes the sample size. To address this issue, we propose using a novel activation dense-to-sparse gate, which routes the output of a linear layer to an activation function before delivering them to the softmax function. By imposing linearly independence conditions on the activation function and its derivatives, we show that the parameter estimation rates are significantly improved to polynomial rates.
AG-ReID.v2: Bridging Aerial and Ground Views for Person Re-identification
Jan 05, 2024Aerial-ground person re-identification (Re-ID) presents unique challenges in computer vision, stemming from the distinct differences in viewpoints, poses, and resolutions between high-altitude aerial and ground-based cameras. Existing research predominantly focuses on ground-to-ground matching, with aerial matching less explored due to a dearth of comprehensive datasets. To address this, we introduce AG-ReID.v2, a dataset specifically designed for person Re-ID in mixed aerial and ground scenarios. This dataset comprises 100,502 images of 1,615 unique individuals, each annotated with matching IDs and 15 soft attribute labels. Data were collected from diverse perspectives using a UAV, stationary CCTV, and smart glasses-integrated camera, providing a rich variety of intra-identity variations. Additionally, we have developed an explainable attention network tailored for this dataset. This network features a three-stream architecture that efficiently processes pairwise image distances, emphasizes key top-down features, and adapts to variations in appearance due to altitude differences. Comparative evaluations demonstrate the superiority of our approach over existing baselines. We plan to release the dataset and algorithm source code publicly, aiming to advance research in this specialized field of computer vision. For access, please visit https://github.com/huynguyen792/AG-ReID.v2.
A General Theory for Softmax Gating Multinomial Logistic Mixture of Experts
Oct 22, 2023Mixture-of-experts (MoE) model incorporates the power of multiple submodels via gating functions to achieve greater performance in numerous regression and classification applications. From a theoretical perspective, while there have been previous attempts to comprehend the behavior of that model under the regression settings through the convergence analysis of maximum likelihood estimation in the Gaussian MoE model, such analysis under the setting of a classification problem has remained missing in the literature. We close this gap by establishing the convergence rates of density estimation and parameter estimation in the softmax gating multinomial logistic MoE model. Notably, when part of the expert parameters vanish, these rates are shown to be slower than polynomial rates owing to an inherent interaction between the softmax gating and expert functions via partial differential equations. To address this issue, we propose using a novel class of modified softmax gating functions which transform the input value before delivering them to the gating functions. As a result, the previous interaction disappears and the parameter estimation rates are significantly improved.
Statistical Perspective of Top-K Sparse Softmax Gating Mixture of Experts
Sep 25, 2023Top-K sparse softmax gating mixture of experts has been widely used for scaling up massive deep-learning architectures without increasing the computational cost. Despite its popularity in real-world applications, the theoretical understanding of that gating function has remained an open problem. The main challenge comes from the structure of the top-K sparse softmax gating function, which partitions the input space into multiple regions with distinct behaviors. By focusing on a Gaussian mixture of experts, we establish theoretical results on the effects of the top-K sparse softmax gating function on both density and parameter estimations. Our results hinge upon defining novel loss functions among parameters to capture different behaviors of the input regions. When the true number of experts $k_{\ast}$ is known, we demonstrate that the convergence rates of density and parameter estimations are both parametric on the sample size. However, when $k_{\ast}$ becomes unknown and the true model is over-specified by a Gaussian mixture of $k$ experts where $k > k_{\ast}$, our findings suggest that the number of experts selected from the top-K sparse softmax gating function must exceed the total cardinality of a certain number of Voronoi cells associated with the true parameters to guarantee the convergence of the density estimation. Moreover, while the density estimation rate remains parametric under this setting, the parameter estimation rates become substantially slow due to an intrinsic interaction between the softmax gating and expert functions.
OpportunityFinder: A Framework for Automated Causal Inference
Sep 22, 2023We introduce OpportunityFinder, a code-less framework for performing a variety of causal inference studies with panel data for non-expert users. In its current state, OpportunityFinder only requires users to provide raw observational data and a configuration file. A pipeline is then triggered that inspects/processes data, chooses the suitable algorithm(s) to execute the causal study. It returns the causal impact of the treatment on the configured outcome, together with sensitivity and robustness results. Causal inference is widely studied and used to estimate the downstream impact of individual's interactions with products and features. It is common that these causal studies are performed by scientists and/or economists periodically. Business stakeholders are often bottle-necked on scientist or economist bandwidth to conduct causal studies. We offer OpportunityFinder as a solution for commonly performed causal studies with four key features: (1) easy to use for both Business Analysts and Scientists, (2) abstraction of multiple algorithms under a single I/O interface, (3) support for causal impact analysis under binary treatment with panel data and (4) dynamic selection of algorithm based on scale of data.
Towards Convergence Rates for Parameter Estimation in Gaussian-gated Mixture of Experts
May 12, 2023
Originally introduced as a neural network for ensemble learning, mixture of experts (MoE) has recently become a fundamental building block of highly successful modern deep neural networks for heterogeneous data analysis in several applications, including those in machine learning, statistics, bioinformatics, economics, and medicine. Despite its popularity in practice, a satisfactory level of understanding of the convergence behavior of Gaussian-gated MoE parameter estimation is far from complete. The underlying reason for this challenge is the inclusion of covariates in the Gaussian gating and expert networks, which leads to their intrinsically complex interactions via partial differential equations with respect to their parameters. We address these issues by designing novel Voronoi loss functions to accurately capture heterogeneity in the maximum likelihood estimator (MLE) for resolving parameter estimation in these models. Our results reveal distinct behaviors of the MLE under two settings: the first setting is when all the location parameters in the Gaussian gating are non-zeros while the second setting is when there exists at least one zero-valued location parameter. Notably, these behaviors can be characterized by the solvability of two different systems of polynomial equations. Finally, we conduct a simulation study to verify our theoretical results.