 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNhat Ho
Hierarchical Hybrid Sliced Wasserstein: A Scalable Metric for Heterogeneous Joint Distributions
Apr 30, 2024
Sliced Wasserstein (SW) and Generalized Sliced Wasserstein (GSW) have been widely used in applications due to their computational and statistical scalability. However, the SW and the GSW are only defined between distributions supported on a homogeneous domain. This limitation prevents their usage in applications with heterogeneous joint distributions with marginal distributions supported on multiple different domains. Using SW and GSW directly on the joint domains cannot make a meaningful comparison since their homogeneous slicing operator i.e., Radon Transform (RT) and Generalized Radon Transform (GRT) are not expressive enough to capture the structure of the joint supports set. To address the issue, we propose two new slicing operators i.e., Partial Generalized Radon Transform (PGRT) and Hierarchical Hybrid Radon Transform (HHRT). In greater detail, PGRT is the generalization of Partial Radon Transform (PRT), which transforms a subset of function arguments non-linearly while HHRT is the composition of PRT and multiple domain-specific PGRT on marginal domain arguments. By using HHRT, we extend the SW into Hierarchical Hybrid Sliced Wasserstein (H2SW) distance which is designed specifically for comparing heterogeneous joint distributions. We then discuss the topological, statistical, and computational properties of H2SW. Finally, we demonstrate the favorable performance of H2SW in 3D mesh deformation, deep 3D mesh autoencoders, and datasets comparison.
Integrating Efficient Optimal Transport and Functional Maps For Unsupervised Shape Correspondence Learning
Mar 04, 2024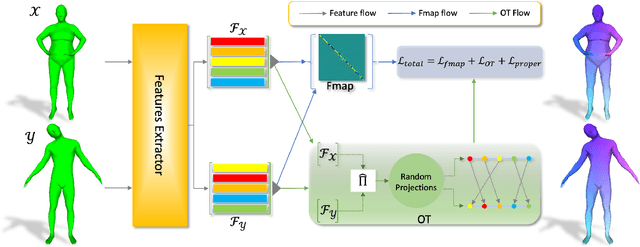
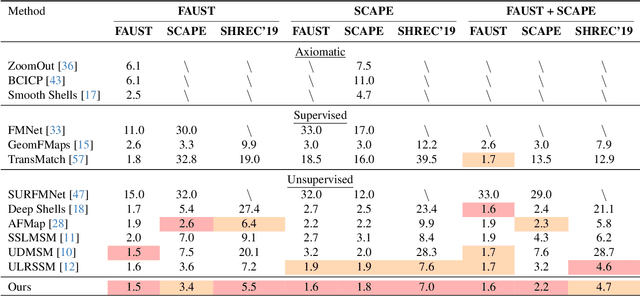
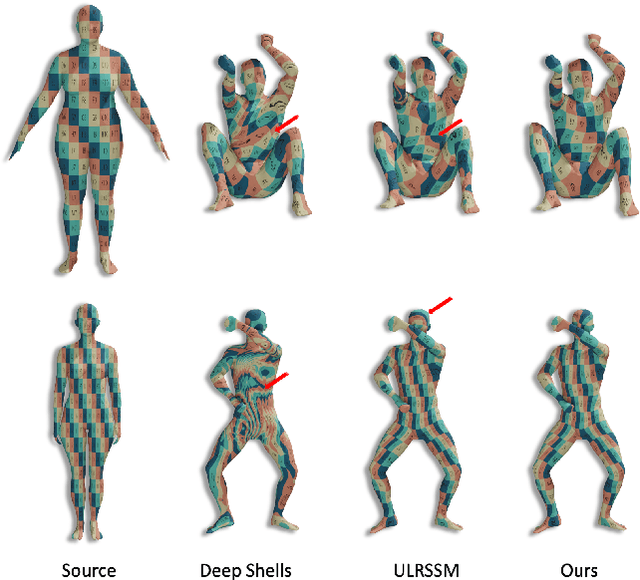
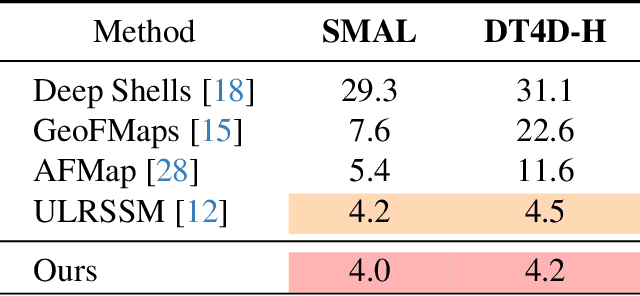
In the realm of computer vision and graphics, accurately establishing correspondences between geometric 3D shapes is pivotal for applications like object tracking, registration, texture transfer, and statistical shape analysis. Moving beyond traditional hand-crafted and data-driven feature learning methods, we incorporate spectral methods with deep learning, focusing on functional maps (FMs) and optimal transport (OT). Traditional OT-based approaches, often reliant on entropy regularization OT in learning-based framework, face computational challenges due to their quadratic cost. Our key contribution is to employ the sliced Wasserstein distance (SWD) for OT, which is a valid fast optimal transport metric in an unsupervised shape matching framework. This unsupervised framework integrates functional map regularizers with a novel OT-based loss derived from SWD, enhancing feature alignment between shapes treated as discrete probability measures. We also introduce an adaptive refinement process utilizing entropy regularized OT, further refining feature alignments for accurate point-to-point correspondences. Our method demonstrates superior performance in non-rigid shape matching, including near-isometric and non-isometric scenarios, and excels in downstream tasks like segmentation transfer. The empirical results on diverse datasets highlight our framework's effectiveness and generalization capabilities, setting new standards in non-rigid shape matching with efficient OT metrics and an adaptive refinement module.
On Parameter Estimation in Deviated Gaussian Mixture of Experts
Feb 07, 2024We consider the parameter estimation problem in the deviated Gaussian mixture of experts in which the data are generated from $(1 - \lambda^{\ast}) g_0(Y| X)+ \lambda^{\ast} \sum_{i = 1}^{k_{\ast}} p_{i}^{\ast} f(Y|(a_{i}^{\ast})^{\top}X+b_i^{\ast},\sigma_{i}^{\ast})$, where $X, Y$ are respectively a covariate vector and a response variable, $g_{0}(Y|X)$ is a known function, $\lambda^{\ast} \in [0, 1]$ is true but unknown mixing proportion, and $(p_{i}^{\ast}, a_{i}^{\ast}, b_{i}^{\ast}, \sigma_{i}^{\ast})$ for $1 \leq i \leq k^{\ast}$ are unknown parameters of the Gaussian mixture of experts. This problem arises from the goodness-of-fit test when we would like to test whether the data are generated from $g_{0}(Y|X)$ (null hypothesis) or they are generated from the whole mixture (alternative hypothesis). Based on the algebraic structure of the expert functions and the distinguishability between $g_0$ and the mixture part, we construct novel Voronoi-based loss functions to capture the convergence rates of maximum likelihood estimation (MLE) for our models. We further demonstrate that our proposed loss functions characterize the local convergence rates of parameter estimation more accurately than the generalized Wasserstein, a loss function being commonly used for estimating parameters in the Gaussian mixture of experts.
On Least Squares Estimation in Softmax Gating Mixture of Experts
Feb 05, 2024Mixture of experts (MoE) model is a statistical machine learning design that aggregates multiple expert networks using a softmax gating function in order to form a more intricate and expressive model. Despite being commonly used in several applications owing to their scalability, the mathematical and statistical properties of MoE models are complex and difficult to analyze. As a result, previous theoretical works have primarily focused on probabilistic MoE models by imposing the impractical assumption that the data are generated from a Gaussian MoE model. In this work, we investigate the performance of the least squares estimators (LSE) under a deterministic MoE model where the data are sampled according to a regression model, a setting that has remained largely unexplored. We establish a condition called strong identifiability to characterize the convergence behavior of various types of expert functions. We demonstrate that the rates for estimating strongly identifiable experts, namely the widely used feed forward networks with activation functions $\mathrm{sigmoid}(\cdot)$ and $\tanh(\cdot)$, are substantially faster than those of polynomial experts, which we show to exhibit a surprising slow estimation rate. Our findings have important practical implications for expert selection.
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Feb 05, 2024As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in real world is validated by a challenging set of clinical risk prediction tasks.
CompeteSMoE -- Effective Training of Sparse Mixture of Experts via Competition
Feb 04, 2024

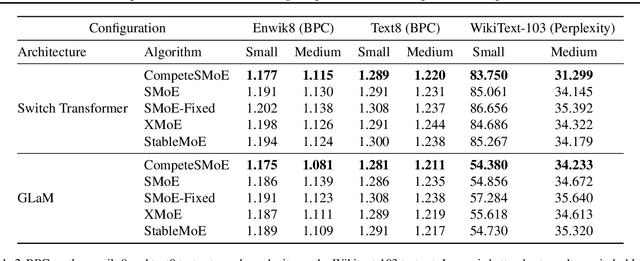

Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, effective training of SMoE has proven to be challenging due to the representation collapse issue, which causes parameter redundancy and limited representation potentials. In this work, we propose a competition mechanism to address this fundamental challenge of representation collapse. By routing inputs only to experts with the highest neural response, we show that, under mild assumptions, competition enjoys the same convergence rate as the optimal estimator. We further propose CompeteSMoE, an effective and efficient algorithm to train large language models by deploying a simple router that predicts the competition outcomes. Consequently, CompeteSMoE enjoys strong performance gains from the competition routing policy while having low computation overheads. Our extensive empirical evaluations on two transformer architectures and a wide range of tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies.
Structure-Aware E(3)-Invariant Molecular Conformer Aggregation Networks
Feb 03, 2024A molecule's 2D representation consists of its atoms, their attributes, and the molecule's covalent bonds. A 3D (geometric) representation of a molecule is called a conformer and consists of its atom types and Cartesian coordinates. Every conformer has a potential energy, and the lower this energy, the more likely it occurs in nature. Most existing machine learning methods for molecular property prediction consider either 2D molecular graphs or 3D conformer structure representations in isolation. Inspired by recent work on using ensembles of conformers in conjunction with 2D graph representations, we propose E(3)-invariant molecular conformer aggregation networks. The method integrates a molecule's 2D representation with that of multiple of its conformers. Contrary to prior work, we propose a novel 2D--3D aggregation mechanism based on a differentiable solver for the \emph{Fused Gromov-Wasserstein Barycenter} problem and the use of an efficient online conformer generation method based on distance geometry. We show that the proposed aggregation mechanism is E(3) invariant and provides an efficient GPU implementation. Moreover, we demonstrate that the aggregation mechanism helps to outperform state-of-the-art property prediction methods on established datasets significantly.
Bayesian Nonparametrics Meets Data-Driven Robust Optimization
Jan 30, 2024Training machine learning and statistical models often involves optimizing a data-driven risk criterion. The risk is usually computed with respect to the empirical data distribution, but this may result in poor and unstable out-of-sample performance due to distributional uncertainty. In the spirit of distributionally robust optimization, we propose a novel robust criterion by combining insights from Bayesian nonparametric (i.e., Dirichlet Process) theory and recent decision-theoretic models of smooth ambiguity-averse preferences. First, we highlight novel connections with standard regularized empirical risk minimization techniques, among which Ridge and LASSO regressions. Then, we theoretically demonstrate the existence of favorable finite-sample and asymptotic statistical guarantees on the performance of the robust optimization procedure. For practical implementation, we propose and study tractable approximations of the criterion based on well-known Dirichlet Process representations. We also show that the smoothness of the criterion naturally leads to standard gradient-based numerical optimization. Finally, we provide insights into the workings of our method by applying it to high-dimensional sparse linear regression and robust location parameter estimation tasks.
Sliced Wasserstein with Random-Path Projecting Directions
Jan 29, 2024Slicing distribution selection has been used as an effective technique to improve the performance of parameter estimators based on minimizing sliced Wasserstein distance in applications. Previous works either utilize expensive optimization to select the slicing distribution or use slicing distributions that require expensive sampling methods. In this work, we propose an optimization-free slicing distribution that provides a fast sampling for the Monte Carlo estimation of expectation. In particular, we introduce the random-path projecting direction (RPD) which is constructed by leveraging the normalized difference between two random vectors following the two input measures. From the RPD, we derive the random-path slicing distribution (RPSD) and two variants of sliced Wasserstein, i.e., the Random-Path Projection Sliced Wasserstein (RPSW) and the Importance Weighted Random-Path Projection Sliced Wasserstein (IWRPSW). We then discuss the topological, statistical, and computational properties of RPSW and IWRPSW. Finally, we showcase the favorable performance of RPSW and IWRPSW in gradient flow and the training of denoising diffusion generative models on images.
Is Temperature Sample Efficient for Softmax Gaussian Mixture of Experts?
Jan 25, 2024Dense-to-sparse gating mixture of experts (MoE) has recently become an effective alternative to a well-known sparse MoE. Rather than fixing the number of activated experts as in the latter model, which could limit the investigation of potential experts, the former model utilizes the temperature to control the softmax weight distribution and the sparsity of the MoE during training in order to stabilize the expert specialization. Nevertheless, while there are previous attempts to theoretically comprehend the sparse MoE, a comprehensive analysis of the dense-to-sparse gating MoE has remained elusive. Therefore, we aim to explore the impacts of the dense-to-sparse gate on the maximum likelihood estimation under the Gaussian MoE in this paper. We demonstrate that due to interactions between the temperature and other model parameters via some partial differential equations, the convergence rates of parameter estimations are slower than any polynomial rates, and could be as slow as $\mathcal{O}(1/\log(n))$, where $n$ denotes the sample size. To address this issue, we propose using a novel activation dense-to-sparse gate, which routes the output of a linear layer to an activation function before delivering them to the softmax function. By imposing linearly independence conditions on the activation function and its derivatives, we show that the parameter estimation rates are significantly improved to polynomial rates.