 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTam Le
Universal Generalization Guarantees for Wasserstein Distributionally Robust Models
Feb 19, 2024
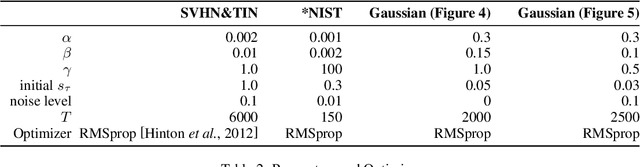
Distributionally robust optimization has emerged as an attractive way to train robust machine learning models, capturing data uncertainty and distribution shifts. Recent statistical analyses have proved that robust models built from Wasserstein ambiguity sets have nice generalization guarantees, breaking the curse of dimensionality. However, these results are obtained in specific cases, at the cost of approximations, or under assumptions difficult to verify in practice. In contrast, we establish, in this article, exact generalization guarantees that cover all practical cases, including any transport cost function and any loss function, potentially non-convex and nonsmooth. For instance, our result applies to deep learning, without requiring restrictive assumptions. We achieve this result through a novel proof technique that combines nonsmooth analysis rationale with classical concentration results. Our approach is general enough to extend to the recent versions of Wasserstein/Sinkhorn distributionally robust problems that involve (double) regularizations.
Generalized Sobolev Transport for Probability Measures on a Graph
Feb 07, 2024We study the optimal transport (OT) problem for measures supported on a graph metric space. Recently, Le et al. (2022) leverage the graph structure and propose a variant of OT, namely Sobolev transport (ST), which yields a closed-form expression for a fast computation. However, ST is essentially coupled with the $L^p$ geometric structure within its definition which makes it nontrivial to utilize ST for other prior structures. In contrast, the classic OT has the flexibility to adapt to various geometric structures by modifying the underlying cost function. An important instance is the Orlicz-Wasserstein (OW) which moves beyond the $L^p$ structure by leveraging the \emph{Orlicz geometric structure}. Comparing to the usage of standard $p$-order Wasserstein, OW remarkably helps to advance certain machine learning approaches. Nevertheless, OW brings up a new challenge on its computation due to its two-level optimization formulation. In this work, we leverage a specific class of convex functions for Orlicz structure to propose the generalized Sobolev transport (GST). GST encompasses the ST as its special case, and can be utilized for prior structures beyond the $L^p$ geometry. In connection with the OW, we show that one only needs to simply solve a univariate optimization problem to compute the GST, unlike the complex two-level optimization problem in OW. We empirically illustrate that GST is several-order faster than the OW. Moreover, we provide preliminary evidences on the advantages of GST for document classification and for several tasks in topological data analysis.
Sliced Wasserstein with Random-Path Projecting Directions
Jan 29, 2024Slicing distribution selection has been used as an effective technique to improve the performance of parameter estimators based on minimizing sliced Wasserstein distance in applications. Previous works either utilize expensive optimization to select the slicing distribution or use slicing distributions that require expensive sampling methods. In this work, we propose an optimization-free slicing distribution that provides a fast sampling for the Monte Carlo estimation of expectation. In particular, we introduce the random-path projecting direction (RPD) which is constructed by leveraging the normalized difference between two random vectors following the two input measures. From the RPD, we derive the random-path slicing distribution (RPSD) and two variants of sliced Wasserstein, i.e., the Random-Path Projection Sliced Wasserstein (RPSW) and the Importance Weighted Random-Path Projection Sliced Wasserstein (IWRPSW). We then discuss the topological, statistical, and computational properties of RPSW and IWRPSW. Finally, we showcase the favorable performance of RPSW and IWRPSW in gradient flow and the training of denoising diffusion generative models on images.
Scalable Counterfactual Distribution Estimation in Multivariate Causal Models
Nov 02, 2023We consider the problem of estimating the counterfactual joint distribution of multiple quantities of interests (e.g., outcomes) in a multivariate causal model extended from the classical difference-in-difference design. Existing methods for this task either ignore the correlation structures among dimensions of the multivariate outcome by considering univariate causal models on each dimension separately and hence produce incorrect counterfactual distributions, or poorly scale even for moderate-size datasets when directly dealing with such multivariate causal model. We propose a method that alleviates both issues simultaneously by leveraging a robust latent one-dimensional subspace of the original high-dimension space and exploiting the efficient estimation from the univariate causal model on such space. Since the construction of the one-dimensional subspace uses information from all the dimensions, our method can capture the correlation structures and produce good estimates of the counterfactual distribution. We demonstrate the advantages of our approach over existing methods on both synthetic and real-world data.
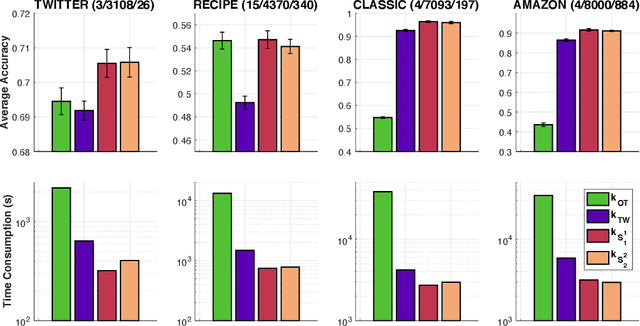
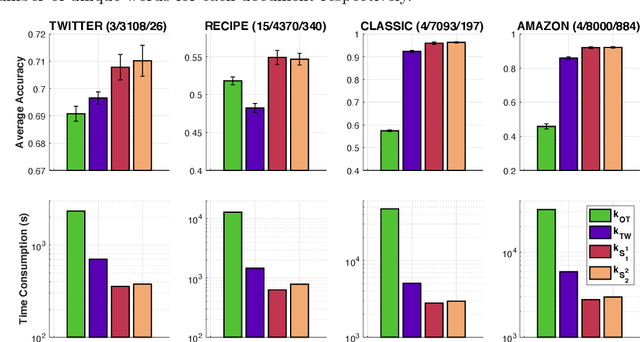
Optimal Transport for Measures with Noisy Tree Metric
Oct 20, 2023We study optimal transport (OT) problem for probability measures supported on a tree metric space. It is known that such OT problem (i.e., tree-Wasserstein (TW)) admits a closed-form expression, but depends fundamentally on the underlying tree structure over supports of input measures. In practice, the given tree structure may be, however, perturbed due to noisy or adversarial measurements. In order to mitigate this issue, we follow the max-min robust OT approach which considers the maximal possible distances between two input measures over an uncertainty set of tree metrics. In general, this approach is hard to compute, even for measures supported in $1$-dimensional space, due to its non-convexity and non-smoothness which hinders its practical applications, especially for large-scale settings. In this work, we propose \emph{novel uncertainty sets of tree metrics} from the lens of edge deletion/addition which covers a diversity of tree structures in an elegant framework. Consequently, by building upon the proposed uncertainty sets, and leveraging the tree structure over supports, we show that the max-min robust OT also admits a closed-form expression for a fast computation as its counterpart standard OT (i.e., TW). Furthermore, we demonstrate that the max-min robust OT satisfies the metric property and is negative definite. We then exploit its negative definiteness to propose \emph{positive definite kernels} and test them in several simulations on various real-world datasets on document classification and topological data analysis for measures with noisy tree metric.
Few-Shot Object Detection via Synthetic Features with Optimal Transport
Aug 30, 2023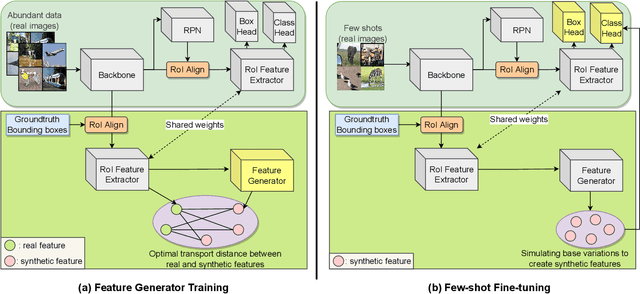
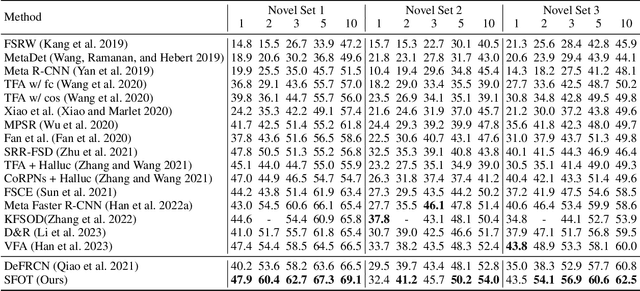
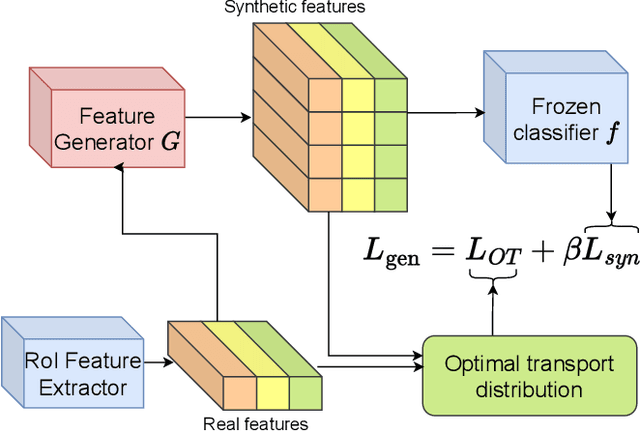
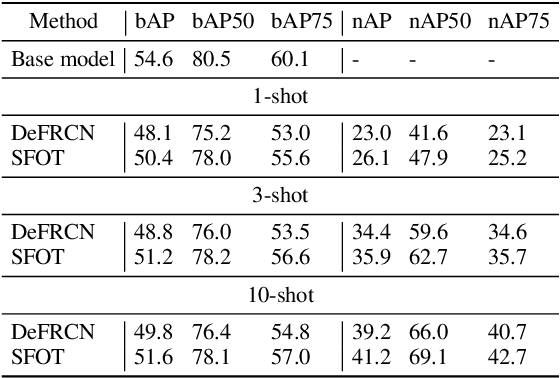
Few-shot object detection aims to simultaneously localize and classify the objects in an image with limited training samples. However, most existing few-shot object detection methods focus on extracting the features of a few samples of novel classes that lack diversity. Hence, they may not be sufficient to capture the data distribution. To address that limitation, in this paper, we propose a novel approach in which we train a generator to generate synthetic data for novel classes. Still, directly training a generator on the novel class is not effective due to the lack of novel data. To overcome that issue, we leverage the large-scale dataset of base classes. Our overarching goal is to train a generator that captures the data variations of the base dataset. We then transform the captured variations into novel classes by generating synthetic data with the trained generator. To encourage the generator to capture data variations on base classes, we propose to train the generator with an optimal transport loss that minimizes the optimal transport distance between the distributions of real and synthetic data. Extensive experiments on two benchmark datasets demonstrate that the proposed method outperforms the state of the art. Source code will be available.
Scalable Unbalanced Sobolev Transport for Measures on a Graph
Feb 24, 2023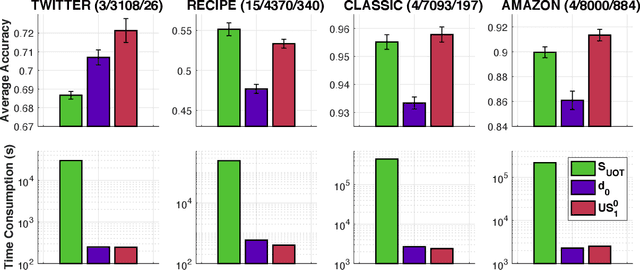
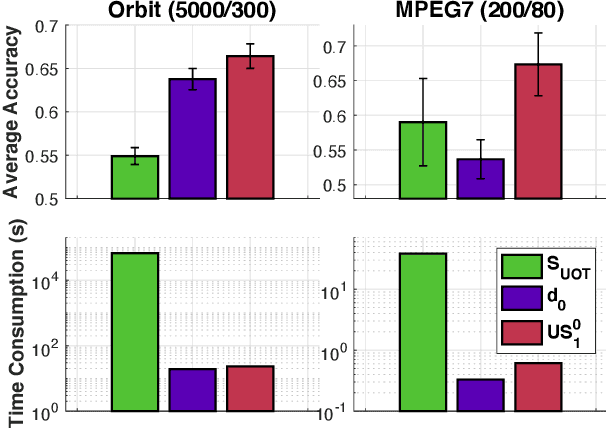
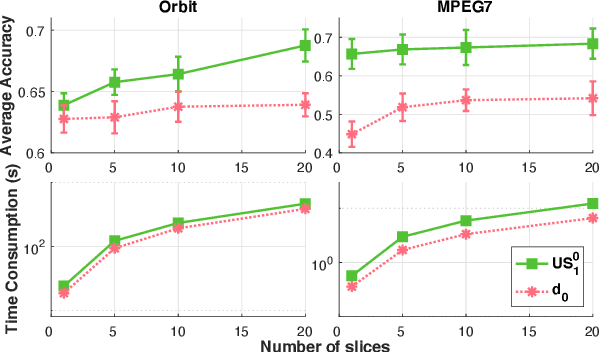
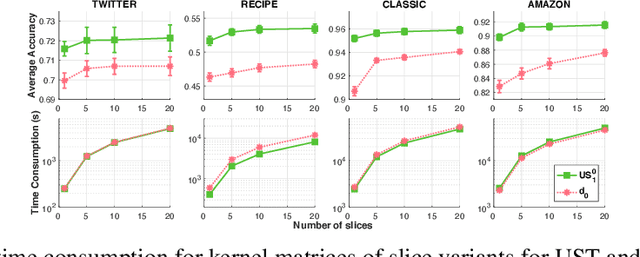
Optimal transport (OT) is a popular and powerful tool for comparing probability measures. However, OT suffers a few drawbacks: (i) input measures required to have the same mass, (ii) a high computational complexity, and (iii) indefiniteness which limits its applications on kernel-dependent algorithmic approaches. To tackle issues (ii)--(iii), Le et al. (2022) recently proposed Sobolev transport for measures on a graph having the same total mass by leveraging the graph structure over supports. In this work, we consider measures that may have different total mass and are supported on a graph metric space. To alleviate the disadvantages (i)--(iii) of OT, we propose a novel and scalable approach to extend Sobolev transport for this unbalanced setting where measures may have different total mass. We show that the proposed unbalanced Sobolev transport (UST) admits a closed-form formula for fast computation, and it is also negative definite. Additionally, we derive geometric structures for the UST and establish relations between our UST and other transport distances. We further exploit the negative definiteness to design positive definite kernels and evaluate them on various simulations to illustrate their fast computation and comparable performances against other transport baselines for unbalanced measures on a graph.
Dynamic Flows on Curved Space Generated by Labeled Data
Jan 31, 2023


The scarcity of labeled data is a long-standing challenge for many machine learning tasks. We propose our gradient flow method to leverage the existing dataset (i.e., source) to generate new samples that are close to the dataset of interest (i.e., target). We lift both datasets to the space of probability distributions on the feature-Gaussian manifold, and then develop a gradient flow method that minimizes the maximum mean discrepancy loss. To perform the gradient flow of distributions on the curved feature-Gaussian space, we unravel the Riemannian structure of the space and compute explicitly the Riemannian gradient of the loss function induced by the optimal transport metric. For practical applications, we also propose a discretized flow, and provide conditional results guaranteeing the global convergence of the flow to the optimum. We illustrate the results of our proposed gradient flow method on several real-world datasets and show our method can improve the accuracy of classification models in transfer learning settings.
Sobolev Transport: A Scalable Metric for Probability Measures with Graph Metrics
Feb 22, 2022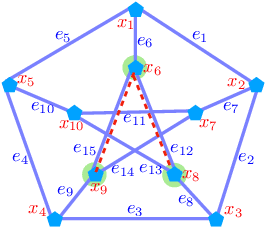
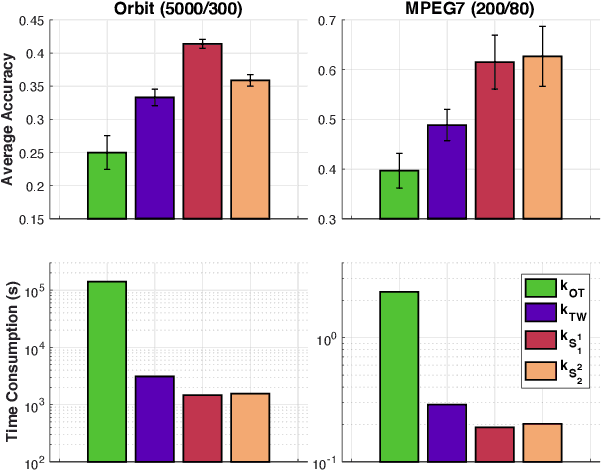
Optimal transport (OT) is a popular measure to compare probability distributions. However, OT suffers a few drawbacks such as (i) a high complexity for computation, (ii) indefiniteness which limits its applicability to kernel machines. In this work, we consider probability measures supported on a graph metric space and propose a novel Sobolev transport metric. We show that the Sobolev transport metric yields a closed-form formula for fast computation and it is negative definite. We show that the space of probability measures endowed with this transport distance is isometric to a bounded convex set in a Euclidean space with a weighted $\ell_p$ distance. We further exploit the negative definiteness of the Sobolev transport to design positive-definite kernels, and evaluate their performances against other baselines in document classification with word embeddings and in topological data analysis.
Adversarial Regression with Doubly Non-negative Weighting Matrices
Sep 30, 2021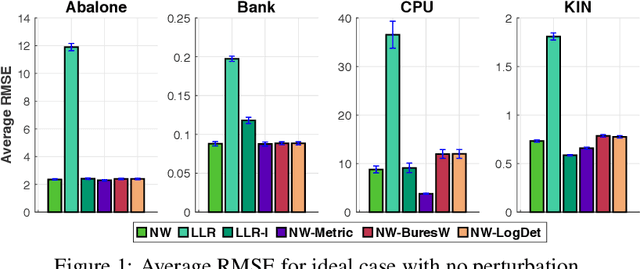

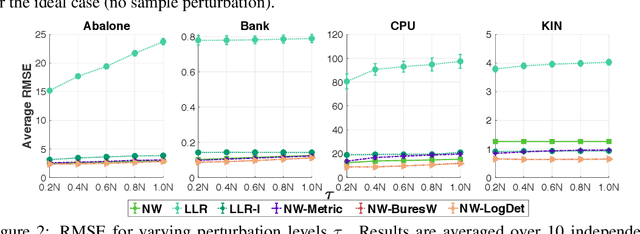
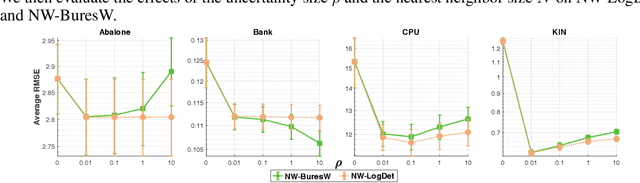
Many machine learning tasks that involve predicting an output response can be solved by training a weighted regression model. Unfortunately, the predictive power of this type of models may severely deteriorate under low sample sizes or under covariate perturbations. Reweighting the training samples has aroused as an effective mitigation strategy to these problems. In this paper, we propose a novel and coherent scheme for kernel-reweighted regression by reparametrizing the sample weights using a doubly non-negative matrix. When the weighting matrix is confined in an uncertainty set using either the log-determinant divergence or the Bures-Wasserstein distance, we show that the adversarially reweighted estimate can be solved efficiently using first-order methods. Numerical experiments show that our reweighting strategy delivers promising results on numerous datasets.