 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHwanhee Lee
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
Apr 18, 2024
As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.
FIZZ: Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document
Apr 18, 2024Through the advent of pre-trained language models, there have been notable advancements in abstractive summarization systems. Simultaneously, a considerable number of novel methods for evaluating factual consistency in abstractive summarization systems has been developed. But these evaluation approaches incorporate substantial limitations, especially on refinement and interpretability. In this work, we propose highly effective and interpretable factual inconsistency detection method metric Factual Inconsistency Detection by Zoom-in Summary and Zoom-out Document for abstractive summarization systems that is based on fine-grained atomic facts decomposition. Moreover, we align atomic facts decomposed from the summary with the source document through adaptive granularity expansion. These atomic facts represent a more fine-grained unit of information, facilitating detailed understanding and interpretability of the summary's factual inconsistency. Experimental results demonstrate that our proposed factual consistency checking system significantly outperforms existing systems.
KoCoSa: Korean Context-aware Sarcasm Detection Dataset
Feb 22, 2024



Sarcasm is a way of verbal irony where someone says the opposite of what they mean, often to ridicule a person, situation, or idea. It is often difficult to detect sarcasm in the dialogue since detecting sarcasm should reflect the context (i.e., dialogue history). In this paper, we introduce a new dataset for the Korean dialogue sarcasm detection task, KoCoSa (Korean Context-aware Sarcasm Detection Dataset), which consists of 12.8K daily Korean dialogues and the labels for this task on the last response. To build the dataset, we propose an efficient sarcasm detection dataset generation pipeline: 1) generating new sarcastic dialogues from source dialogues with large language models, 2) automatic and manual filtering of abnormal and toxic dialogues, and 3) human annotation for the sarcasm detection task. We also provide a simple but effective baseline for the Korean sarcasm detection task trained on our dataset. Experimental results on the dataset show that our baseline system outperforms strong baselines like large language models, such as GPT-3.5, in the Korean sarcasm detection task. We show that the sarcasm detection task relies deeply on the existence of sufficient context. We will release the dataset at https://anonymous.4open.science/r/KoCoSa-2372.
IterCQR: Iterative Conversational Query Reformulation without Human Supervision
Nov 16, 2023In conversational search, which aims to retrieve passages containing essential information, queries suffer from high dependency on the preceding dialogue context. Therefore, reformulating conversational queries into standalone forms is essential for the effective utilization of off-the-shelf retrievers. Previous methodologies for conversational query search frequently depend on human-annotated gold labels. However, these manually crafted queries often result in sub-optimal retrieval performance and require high collection costs. In response to these challenges, we propose Iterative Conversational Query Reformulation (IterCQR), a methodology that conducts query reformulation without relying on human oracles. IterCQR iteratively trains the QR model by directly leveraging signal from information retrieval (IR) as a reward. Our proposed IterCQR method shows state-of-the-art performance on two datasets, demonstrating its effectiveness on both sparse and dense retrievers. Notably, IterCQR exhibits robustness in domain-shift, low-resource, and topic-shift scenarios.
LifeTox: Unveiling Implicit Toxicity in Life Advice
Nov 16, 2023As large language models become increasingly integrated into daily life, detecting implicit toxicity across diverse contexts is crucial. To this end, we introduce LifeTox, a dataset designed for identifying implicit toxicity within a broad range of advice-seeking scenarios. Unlike existing safety datasets, LifeTox comprises diverse contexts derived from personal experiences through open-ended questions. Experiments demonstrate that RoBERTa fine-tuned on LifeTox matches or surpasses the zero-shot performance of large language models in toxicity classification tasks. These results underscore the efficacy of LifeTox in addressing the complex challenges inherent in implicit toxicity.
Dialogizer: Context-aware Conversational-QA Dataset Generation from Textual Sources
Nov 09, 2023To address the data scarcity issue in Conversational question answering (ConvQA), a dialog inpainting method, which utilizes documents to generate ConvQA datasets, has been proposed. However, the original dialog inpainting model is trained solely on the dialog reconstruction task, resulting in the generation of questions with low contextual relevance due to insufficient learning of question-answer alignment. To overcome this limitation, we propose a novel framework called Dialogizer, which has the capability to automatically generate ConvQA datasets with high contextual relevance from textual sources. The framework incorporates two training tasks: question-answer matching (QAM) and topic-aware dialog generation (TDG). Moreover, re-ranking is conducted during the inference phase based on the contextual relevance of the generated questions. Using our framework, we produce four ConvQA datasets by utilizing documents from multiple domains as the primary source. Through automatic evaluation using diverse metrics, as well as human evaluation, we validate that our proposed framework exhibits the ability to generate datasets of higher quality compared to the baseline dialog inpainting model.
Asking Clarification Questions to Handle Ambiguity in Open-Domain QA
May 23, 2023

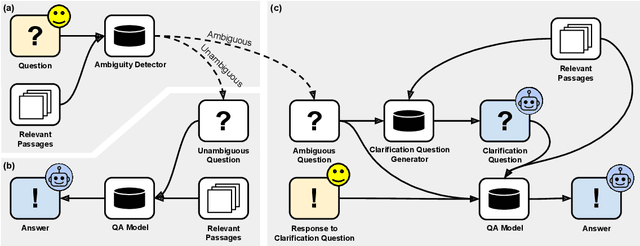

Ambiguous questions persist in open-domain question answering, because formulating a precise question with a unique answer is often challenging. Previously, Min et al. (2020) have tackled this issue by generating disambiguated questions for all possible interpretations of the ambiguous question. This can be effective, but not ideal for providing an answer to the user. Instead, we propose to ask a clarification question, where the user's response will help identify the interpretation that best aligns with the user's intention. We first present CAMBIGNQ, a dataset consisting of 5,654 ambiguous questions, each with relevant passages, possible answers, and a clarification question. The clarification questions were efficiently created by generating them using InstructGPT and manually revising them as necessary. We then define a pipeline of tasks and design appropriate evaluation metrics. Lastly, we achieve 61.3 F1 on ambiguity detection and 40.5 F1 on clarification-based QA, providing strong baselines for future work.
Critic-Guided Decoding for Controlled Text Generation
Dec 21, 2022



Steering language generation towards objectives or away from undesired content has been a long-standing goal in utilizing language models (LM). Recent work has demonstrated reinforcement learning and weighted decoding as effective approaches to achieve a higher level of language control and quality with pros and cons. In this work, we propose a novel critic decoding method for controlled language generation (CriticControl) that combines the strengths of reinforcement learning and weighted decoding. Specifically, we adopt the actor-critic framework to train an LM-steering critic from non-differentiable reward models. And similar to weighted decoding, our method freezes the language model and manipulates the output token distribution using called critic, improving training efficiency and stability. Evaluation of our method on three controlled generation tasks, namely topic control, sentiment control, and detoxification, shows that our approach generates more coherent and well-controlled texts than previous methods. In addition, CriticControl demonstrates superior generalization ability in zero-shot settings. Human evaluation studies also corroborate our findings.
Attribution-based Task-specific Pruning for Multi-task Language Models
May 09, 2022



Multi-task language models show outstanding performance for various natural language understanding tasks with only a single model. However, these language models inevitably utilize unnecessary large-scale model parameters, even when they are used for only a specific task. In this paper, we propose a novel training-free task-specific pruning method for multi-task language models. Specifically, we utilize an attribution method to compute the importance of each neuron for performing a specific task. Then, we prune task-specifically unimportant neurons using this computed importance. Experimental results on the six widely-used datasets show that our proposed pruning method significantly outperforms baseline compression methods. Also, we extend our method to be applicable in a low-resource setting, where the number of labeled datasets is insufficient.
Masked Summarization to Generate Factually Inconsistent Summaries for Improved Factual Consistency Checking
May 04, 2022



Despite the recent advances in abstractive summarization systems, it is still difficult to determine whether a generated summary is factual consistent with the source text. To this end, the latest approach is to train a factual consistency classifier on factually consistent and inconsistent summaries. Luckily, the former is readily available as reference summaries in existing summarization datasets. However, generating the latter remains a challenge, as they need to be factually inconsistent, yet closely relevant to the source text to be effective. In this paper, we propose to generate factually inconsistent summaries using source texts and reference summaries with key information masked. Experiments on seven benchmark datasets demonstrate that factual consistency classifiers trained on summaries generated using our method generally outperform existing models and show a competitive correlation with human judgments. We also analyze the characteristics of the summaries generated using our method. We will release the pre-trained model and the code at https://github.com/hwanheelee1993/MFMA.