 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKyomin Jung
SKIP: Skill-Localized Prompt Tuning for Inference Speed Boost-Up
Apr 18, 2024
Prompt-tuning methods have shown comparable performance as parameter-efficient fine-tuning (PEFT) methods in various natural language understanding tasks. However, existing prompt tuning methods still utilize the entire model architecture; thus, they fail to accelerate inference speed in the application. In this paper, we propose a novel approach called SKIll-localized Prompt tuning (SKIP), which is extremely efficient in inference time. Our method significantly enhances inference efficiency by investigating and utilizing a skill-localized subnetwork in a language model. Surprisingly, our method improves the inference speed up to 160% while pruning 52% of the parameters. Furthermore, we demonstrate that our method is applicable across various transformer-based architectures, thereby confirming its practicality and scalability.
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
Apr 18, 2024As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.
MP2D: An Automated Topic Shift Dialogue Generation Framework Leveraging Knowledge Graphs
Mar 09, 2024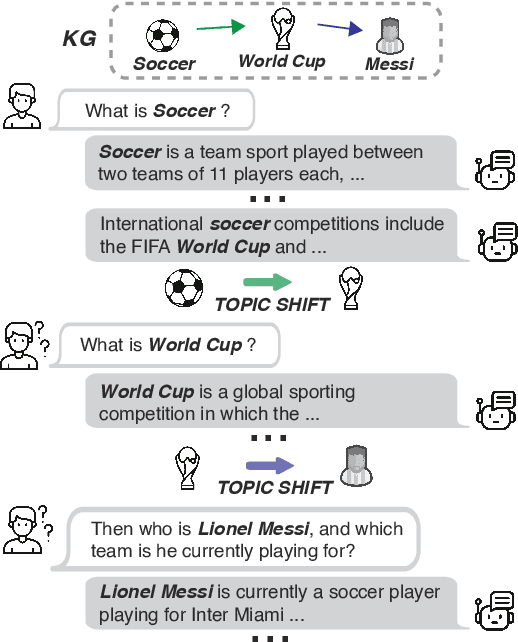
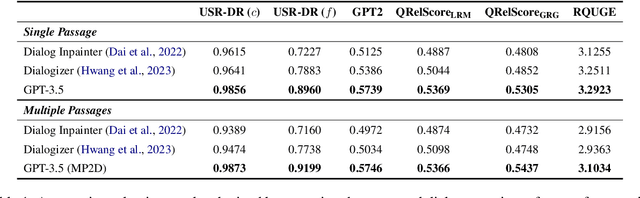
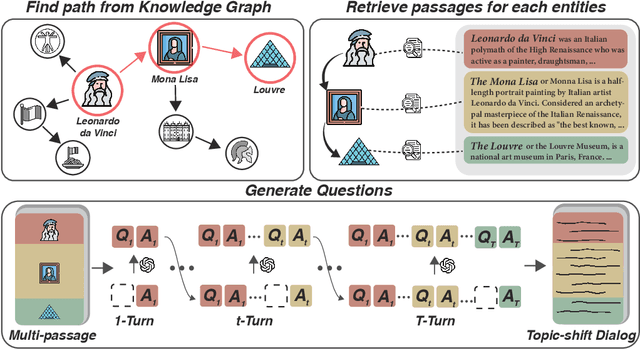

Despite advancements in on-topic dialogue systems, effectively managing topic shifts within dialogues remains a persistent challenge, largely attributed to the limited availability of training datasets. To address this issue, we propose Multi-Passage to Dialogue (MP2D), a data generation framework that automatically creates conversational question-answering datasets with natural topic transitions. By leveraging the relationships between entities in a knowledge graph, MP2D maps the flow of topics within a dialogue, effectively mirroring the dynamics of human conversation. It retrieves relevant passages corresponding to the topics and transforms them into dialogues through the passage-to-dialogue method. Through quantitative and qualitative experiments, we demonstrate MP2D's efficacy in generating dialogue with natural topic shifts. Furthermore, this study introduces a novel benchmark for topic shift dialogues, TS-WikiDialog. Utilizing the dataset, we demonstrate that even Large Language Models (LLMs) struggle to handle topic shifts in dialogue effectively, and we showcase the performance improvements of models trained on datasets generated by MP2D across diverse topic shift dialogue tasks.
Can LLMs Recognize Toxicity? Structured Toxicity Investigation Framework and Semantic-Based Metric
Feb 16, 2024In the pursuit of developing Large Language Models (LLMs) that adhere to societal standards, it is imperative to discern the existence of toxicity in the generated text. The majority of existing toxicity metrics rely on encoder models trained on specific toxicity datasets. However, these encoders are susceptible to out-of-distribution (OOD) problems and depend on the definition of toxicity assumed in a dataset. In this paper, we introduce an automatic robust metric grounded on LLMs to distinguish whether model responses are toxic. We start by analyzing the toxicity factors, followed by examining the intrinsic toxic attributes of LLMs to ascertain their suitability as evaluators. Subsequently, we evaluate our metric, LLMs As ToxiciTy Evaluators (LATTE), on evaluation datasets.The empirical results indicate outstanding performance in measuring toxicity, improving upon state-of-the-art metrics by 12 points in F1 score without training procedure. We also show that upstream toxicity has an influence on downstream metrics.
LongStory: Coherent, Complete and Length Controlled Long story Generation
Nov 26, 2023A human author can write any length of story without losing coherence. Also, they always bring the story to a proper ending, an ability that current language models lack. In this work, we present the LongStory for coherent, complete, and length-controlled long story generation. LongStory introduces two novel methodologies: (1) the long and short-term contexts weight calibrator (CWC) and (2) long story structural positions (LSP). The CWC adjusts weights for long-term context Memory and short-term context Cheating, acknowledging their distinct roles. The LSP employs discourse tokens to convey the structural positions of a long story. Trained on three datasets with varied average story lengths, LongStory outperforms other baselines, including the strong story generator Plotmachine, in coherence, completeness, relevance, and repetitiveness. We also perform zero-shot tests on each dataset to assess the model's ability to predict outcomes beyond its training data and validate our methodology by comparing its performance with variants of our model.
IterCQR: Iterative Conversational Query Reformulation without Human Supervision
Nov 16, 2023In conversational search, which aims to retrieve passages containing essential information, queries suffer from high dependency on the preceding dialogue context. Therefore, reformulating conversational queries into standalone forms is essential for the effective utilization of off-the-shelf retrievers. Previous methodologies for conversational query search frequently depend on human-annotated gold labels. However, these manually crafted queries often result in sub-optimal retrieval performance and require high collection costs. In response to these challenges, we propose Iterative Conversational Query Reformulation (IterCQR), a methodology that conducts query reformulation without relying on human oracles. IterCQR iteratively trains the QR model by directly leveraging signal from information retrieval (IR) as a reward. Our proposed IterCQR method shows state-of-the-art performance on two datasets, demonstrating its effectiveness on both sparse and dense retrievers. Notably, IterCQR exhibits robustness in domain-shift, low-resource, and topic-shift scenarios.
CRISPR: Eliminating Bias Neurons from an Instruction-following Language Model
Nov 16, 2023Large language models (LLMs) executing tasks through instruction-based prompts often face challenges stemming from distribution differences between user instructions and training instructions. This leads to distractions and biases, especially when dealing with inconsistent dynamic labels. In this paper, we introduces a novel bias mitigation method, CRISPR, designed to alleviate instruction-label biases in LLMs. CRISPR utilizes attribution methods to identify bias neurons influencing biased outputs and employs pruning to eliminate the bias neurons. Experimental results demonstrate the method's effectiveness in mitigating biases in instruction-based prompting, enhancing language model performance on social bias benchmarks without compromising pre-existing knowledge. CRISPR proves highly practical, model-agnostic, offering flexibility in adapting to evolving social biases.
LifeTox: Unveiling Implicit Toxicity in Life Advice
Nov 16, 2023As large language models become increasingly integrated into daily life, detecting implicit toxicity across diverse contexts is crucial. To this end, we introduce LifeTox, a dataset designed for identifying implicit toxicity within a broad range of advice-seeking scenarios. Unlike existing safety datasets, LifeTox comprises diverse contexts derived from personal experiences through open-ended questions. Experiments demonstrate that RoBERTa fine-tuned on LifeTox matches or surpasses the zero-shot performance of large language models in toxicity classification tasks. These results underscore the efficacy of LifeTox in addressing the complex challenges inherent in implicit toxicity.
Dialogizer: Context-aware Conversational-QA Dataset Generation from Textual Sources
Nov 09, 2023To address the data scarcity issue in Conversational question answering (ConvQA), a dialog inpainting method, which utilizes documents to generate ConvQA datasets, has been proposed. However, the original dialog inpainting model is trained solely on the dialog reconstruction task, resulting in the generation of questions with low contextual relevance due to insufficient learning of question-answer alignment. To overcome this limitation, we propose a novel framework called Dialogizer, which has the capability to automatically generate ConvQA datasets with high contextual relevance from textual sources. The framework incorporates two training tasks: question-answer matching (QAM) and topic-aware dialog generation (TDG). Moreover, re-ranking is conducted during the inference phase based on the contextual relevance of the generated questions. Using our framework, we produce four ConvQA datasets by utilizing documents from multiple domains as the primary source. Through automatic evaluation using diverse metrics, as well as human evaluation, we validate that our proposed framework exhibits the ability to generate datasets of higher quality compared to the baseline dialog inpainting model.