 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyunji Lee
Semiparametric Token-Sequence Co-Supervision
Mar 14, 2024
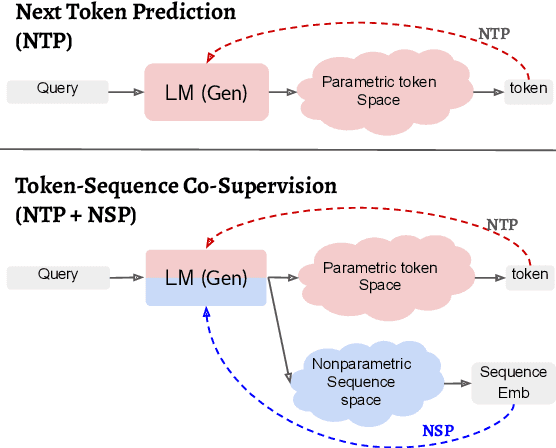
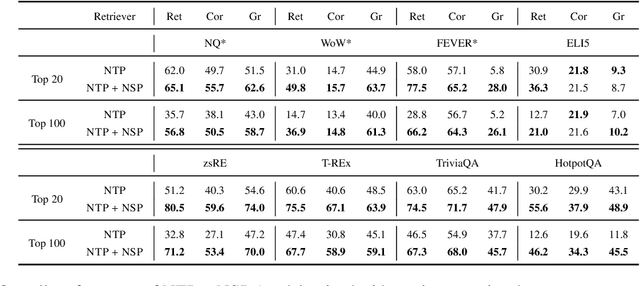
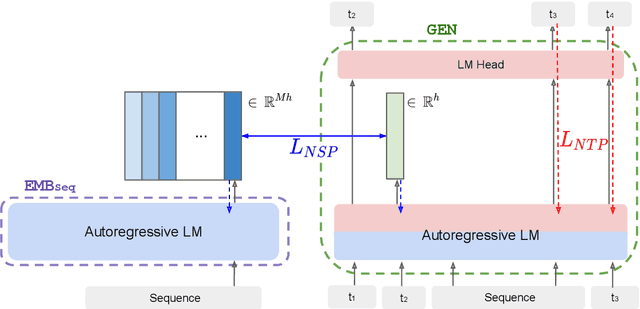
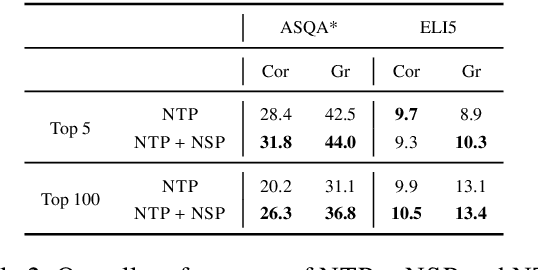
In this work, we introduce a semiparametric token-sequence co-supervision training method. It trains a language model by simultaneously leveraging supervision from the traditional next token prediction loss which is calculated over the parametric token embedding space and the next sequence prediction loss which is calculated over the nonparametric sequence embedding space. The nonparametric sequence embedding space is constructed by a separate language model tasked to condense an input text into a single representative embedding. Our experiments demonstrate that a model trained via both supervisions consistently surpasses models trained via each supervision independently. Analysis suggests that this co-supervision encourages a broader generalization capability across the model. Especially, the robustness of parametric token space which is established during the pretraining step tends to effectively enhance the stability of nonparametric sequence embedding space, a new space established by another language model.
INSTRUCTIR: A Benchmark for Instruction Following of Information Retrieval Models
Feb 22, 2024Despite the critical need to align search targets with users' intention, retrievers often only prioritize query information without delving into the users' intended search context. Enhancing the capability of retrievers to understand intentions and preferences of users, akin to language model instructions, has the potential to yield more aligned search targets. Prior studies restrict the application of instructions in information retrieval to a task description format, neglecting the broader context of diverse and evolving search scenarios. Furthermore, the prevailing benchmarks utilized for evaluation lack explicit tailoring to assess instruction-following ability, thereby hindering progress in this field. In response to these limitations, we propose a novel benchmark,INSTRUCTIR, specifically designed to evaluate instruction-following ability in information retrieval tasks. Our approach focuses on user-aligned instructions tailored to each query instance, reflecting the diverse characteristics inherent in real-world search scenarios. Through experimental analysis, we observe that retrievers fine-tuned to follow task-style instructions, such as INSTRUCTOR, can underperform compared to their non-instruction-tuned counterparts. This underscores potential overfitting issues inherent in constructing retrievers trained on existing instruction-aware retrieval datasets.
Back to Basics: A Simple Recipe for Improving Out-of-Domain Retrieval in Dense Encoders
Nov 16, 2023Prevailing research practice today often relies on training dense retrievers on existing large datasets such as MSMARCO and then experimenting with ways to improve zero-shot generalization capabilities to unseen domains. While prior work has tackled this challenge through resource-intensive steps such as data augmentation, architectural modifications, increasing model size, or even further base model pretraining, comparatively little investigation has examined whether the training procedures themselves can be improved to yield better generalization capabilities in the resulting models. In this work, we recommend a simple recipe for training dense encoders: Train on MSMARCO with parameter-efficient methods, such as LoRA, and opt for using in-batch negatives unless given well-constructed hard negatives. We validate these recommendations using the BEIR benchmark and find results are persistent across choice of dense encoder and base model size and are complementary to other resource-intensive strategies for out-of-domain generalization such as architectural modifications or additional pretraining. We hope that this thorough and impartial study around various training techniques, which augments other resource-intensive methods, offers practical insights for developing a dense retrieval model that effectively generalizes, even when trained on a single dataset.
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
How Well Do Large Language Models Truly Ground?
Nov 15, 2023Reliance on the inherent knowledge of Large Language Models (LLMs) can cause issues such as hallucinations, lack of control, and difficulties in integrating variable knowledge. To mitigate this, LLMs can be probed to generate responses by grounding on external context, often given as input (knowledge-augmented models). Yet, previous research is often confined to a narrow view of the term "grounding", often only focusing on whether the response contains the correct answer or not, which does not ensure the reliability of the entire response. To address this limitation, we introduce a strict definition of grounding: a model is considered truly grounded when its responses (1) fully utilize necessary knowledge from the provided context, and (2) don't exceed the knowledge within the contexts. We introduce a new dataset and a grounding metric to assess this new definition and perform experiments across 13 LLMs of different sizes and training methods to provide insights into the factors that influence grounding performance. Our findings contribute to a better understanding of how to improve grounding capabilities and suggest an area of improvement toward more reliable and controllable LLM applications.
Zero-Shot Dense Video Captioning by Jointly Optimizing Text and Moment
Jul 11, 2023



Dense video captioning, a task of localizing meaningful moments and generating relevant captions for videos, often requires a large, expensive corpus of annotated video segments paired with text. In an effort to minimize the annotation cost, we propose ZeroTA, a novel method for dense video captioning in a zero-shot manner. Our method does not require any videos or annotations for training; instead, it localizes and describes events within each input video at test time by optimizing solely on the input. This is accomplished by introducing a soft moment mask that represents a temporal segment in the video and jointly optimizing it with the prefix parameters of a language model. This joint optimization aligns a frozen language generation model (i.e., GPT-2) with a frozen vision-language contrastive model (i.e., CLIP) by maximizing the matching score between the generated text and a moment within the video. We also introduce a pairwise temporal IoU loss to let a set of soft moment masks capture multiple distinct events within the video. Our method effectively discovers diverse significant events within the video, with the resulting captions appropriately describing these events. The empirical results demonstrate that ZeroTA surpasses zero-shot baselines and even outperforms the state-of-the-art few-shot method on the widely-used benchmark ActivityNet Captions. Moreover, our method shows greater robustness compared to supervised methods when evaluated in out-of-domain scenarios. This research provides insight into the potential of aligning widely-used models, such as language generation models and vision-language models, to unlock a new capability: understanding temporal aspects of videos.
Local 3D Editing via 3D Distillation of CLIP Knowledge
Jun 21, 2023



3D content manipulation is an important computer vision task with many real-world applications (e.g., product design, cartoon generation, and 3D Avatar editing). Recently proposed 3D GANs can generate diverse photorealistic 3D-aware contents using Neural Radiance fields (NeRF). However, manipulation of NeRF still remains a challenging problem since the visual quality tends to degrade after manipulation and suboptimal control handles such as 2D semantic maps are used for manipulations. While text-guided manipulations have shown potential in 3D editing, such approaches often lack locality. To overcome these problems, we propose Local Editing NeRF (LENeRF), which only requires text inputs for fine-grained and localized manipulation. Specifically, we present three add-on modules of LENeRF, the Latent Residual Mapper, the Attention Field Network, and the Deformation Network, which are jointly used for local manipulations of 3D features by estimating a 3D attention field. The 3D attention field is learned in an unsupervised way, by distilling the zero-shot mask generation capability of CLIP to the 3D space with multi-view guidance. We conduct diverse experiments and thorough evaluations both quantitatively and qualitatively.
* conference: CVPR 2023
Continually Updating Generative Retrieval on Dynamic Corpora
May 27, 2023


Generative retrieval has recently been gaining a lot of attention from the research community for its simplicity, high performance, and the ability to fully leverage the power of deep autoregressive models. However, prior work on generative retrieval has mostly investigated on static benchmarks, while realistic retrieval applications often involve dynamic environments where knowledge is temporal and accumulated over time. In this paper, we introduce a new benchmark called STREAMINGIR, dedicated to quantifying the generalizability of retrieval methods to dynamically changing corpora derived from StreamingQA, that simulates realistic retrieval use cases. On this benchmark, we conduct an in-depth comparative evaluation of bi-encoder and generative retrieval in terms of performance as well as efficiency under varying degree of supervision. Our results suggest that generative retrieval shows (1) detrimental performance when only supervised data is used for fine-tuning, (2) superior performance over bi-encoders when only unsupervised data is available, and (3) lower performance to bi-encoders when both unsupervised and supervised data is used due to catastrophic forgetting; nevertheless, we show that parameter-efficient measures can effectively mitigate the issue and result in competitive performance and efficiency with respect to the bi-encoder baseline. Our results open up a new potential for generative retrieval in practical dynamic environments. Our work will be open-sourced.
Improving Probability-based Prompt Selection Through Unified Evaluation and Analysis
May 24, 2023
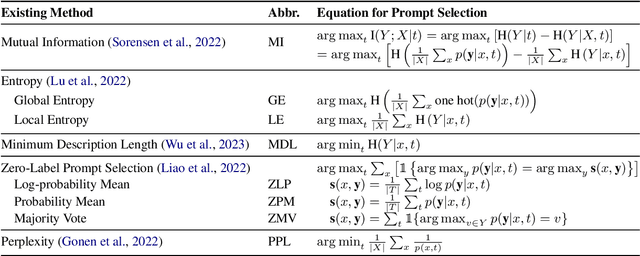
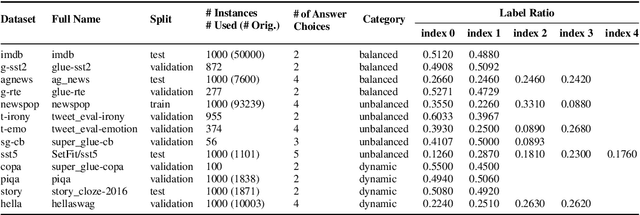
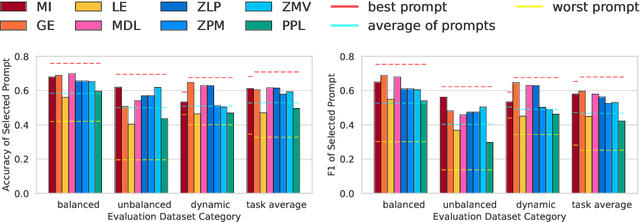
Large Language Models (LLMs) have demonstrated great capabilities in solving a wide range of tasks in a resource-efficient manner through prompting, which does not require task-specific training, but suffers from performance fluctuation when there are multiple prompt candidates. Previous works have introduced gradient-free probability-based prompt selection methods that aim to choose the optimal prompt among the candidates for a given task but fail to provide a comprehensive and fair comparison between each other. In this paper, we propose a unified framework to interpret and evaluate the existing probability-based prompt selection methods by performing extensive experiments on 13 common NLP tasks. We find that all existing methods can be unified into some variant of the method that maximizes the mutual information between the input and the corresponding model output (denoted as MI). Using the finding, we develop several variants of MI and increases the effectiveness of the best prompt selection method from 87.79% to 94.98%, measured as the ratio of the performance of the selected prompt to that of the optimal oracle prompt. Furthermore, we propose a novel calibration method called Calibration by Marginalization (CBM) that is orthogonal to existing methods and helps increase the prompt selection effectiveness of the best method by 99.44%. The code and datasets used in our work will be released at https://github.com/soheeyang/unified-prompt-selection.
Contextualized Generative Retrieval
Oct 07, 2022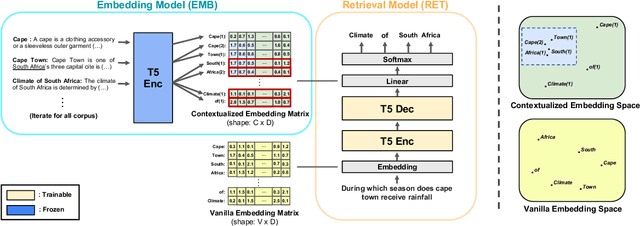
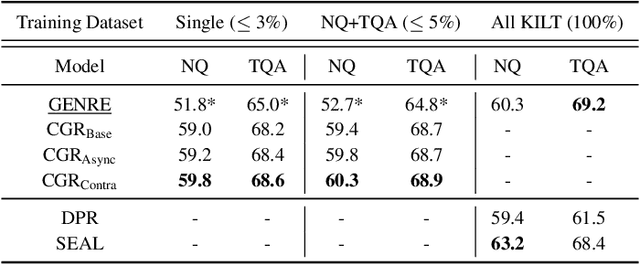
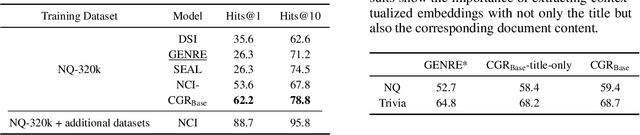
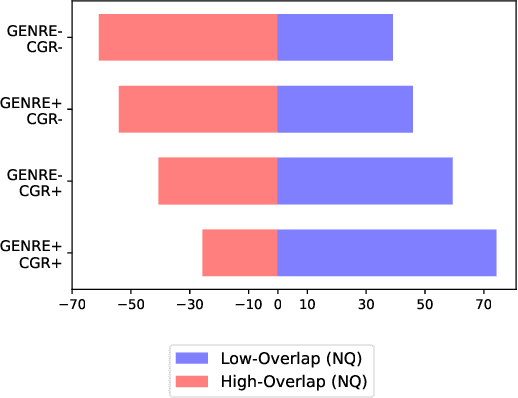
The text retrieval task is mainly performed in two ways: the bi-encoder approach and the generative approach. The bi-encoder approach maps the document and query embeddings to common vector space and performs a nearest neighbor search. It stably shows high performance and efficiency across different domains but has an embedding space bottleneck as it interacts in L2 or inner product space. The generative retrieval model retrieves by generating a target sequence and overcomes the embedding space bottleneck by interacting in the parametric space. However, it fails to retrieve the information it has not seen during the training process as it depends solely on the information encoded in its own model parameters. To leverage the advantages of both approaches, we propose Contextualized Generative Retrieval model, which uses contextualized embeddings (output embeddings of a language model encoder) as vocab embeddings at the decoding step of generative retrieval. The model uses information encoded in both the non-parametric space of contextualized token embeddings and the parametric space of the generative retrieval model. Our approach of generative retrieval with contextualized vocab embeddings shows higher performance than generative retrieval with only vanilla vocab embeddings in the document retrieval task, an average of 6% higher performance in KILT (NQ, TQA) and 2X higher in NQ-320k, suggesting the benefits of using contextualized embedding in generative retrieval models.