 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinjoon Seo
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models
May 02, 2024
Proprietary LMs such as GPT-4 are often employed to assess the quality of responses from various LMs. However, concerns including transparency, controllability, and affordability strongly motivate the development of open-source LMs specialized in evaluations. On the other hand, existing open evaluator LMs exhibit critical shortcomings: 1) they issue scores that significantly diverge from those assigned by humans, and 2) they lack the flexibility to perform both direct assessment and pairwise ranking, the two most prevalent forms of assessment. Additionally, they do not possess the ability to evaluate based on custom evaluation criteria, focusing instead on general attributes like helpfulness and harmlessness. To address these issues, we introduce Prometheus 2, a more powerful evaluator LM than its predecessor that closely mirrors human and GPT-4 judgements. Moreover, it is capable of processing both direct assessment and pair-wise ranking formats grouped with a user-defined evaluation criteria. On four direct assessment benchmarks and four pairwise ranking benchmarks, Prometheus 2 scores the highest correlation and agreement with humans and proprietary LM judges among all tested open evaluator LMs. Our models, code, and data are all publicly available at https://github.com/prometheus-eval/prometheus-eval.
Pegasus-v1 Technical Report
Apr 23, 2024This technical report introduces Pegasus-1, a multimodal language model specialized in video content understanding and interaction through natural language. Pegasus-1 is designed to address the unique challenges posed by video data, such as interpreting spatiotemporal information, to offer nuanced video content comprehension across various lengths. This technical report overviews Pegasus-1's architecture, training strategies, and its performance in benchmarks on video conversation, zero-shot video question answering, and video summarization. We also explore qualitative characteristics of Pegasus-1 , demonstrating its capabilities as well as its limitations, in order to provide readers a balanced view of its current state and its future direction.
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Apr 17, 2024Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Apr 16, 2024Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
Semiparametric Token-Sequence Co-Supervision
Mar 14, 2024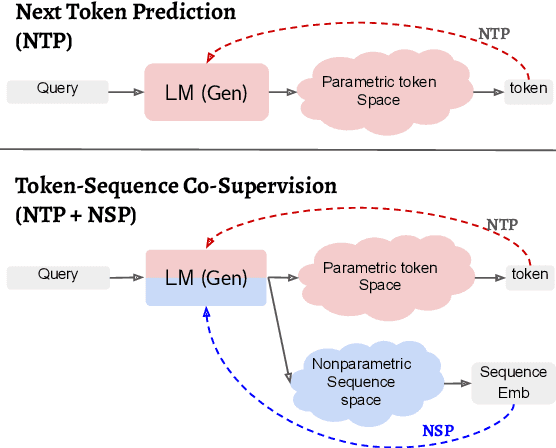
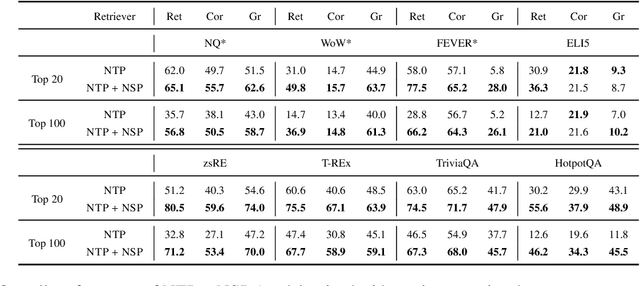
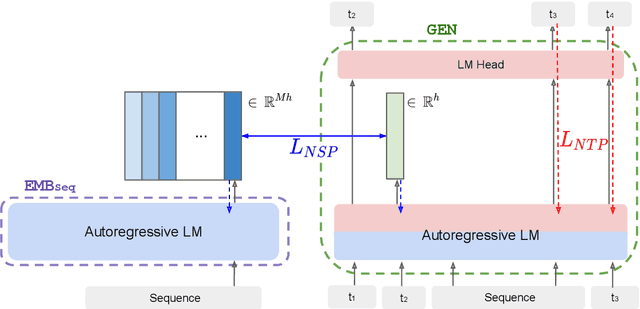
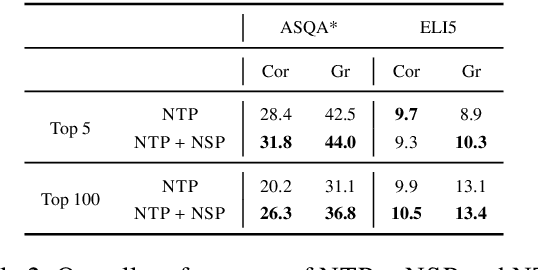
In this work, we introduce a semiparametric token-sequence co-supervision training method. It trains a language model by simultaneously leveraging supervision from the traditional next token prediction loss which is calculated over the parametric token embedding space and the next sequence prediction loss which is calculated over the nonparametric sequence embedding space. The nonparametric sequence embedding space is constructed by a separate language model tasked to condense an input text into a single representative embedding. Our experiments demonstrate that a model trained via both supervisions consistently surpasses models trained via each supervision independently. Analysis suggests that this co-supervision encourages a broader generalization capability across the model. Especially, the robustness of parametric token space which is established during the pretraining step tends to effectively enhance the stability of nonparametric sequence embedding space, a new space established by another language model.
INSTRUCTIR: A Benchmark for Instruction Following of Information Retrieval Models
Feb 22, 2024Despite the critical need to align search targets with users' intention, retrievers often only prioritize query information without delving into the users' intended search context. Enhancing the capability of retrievers to understand intentions and preferences of users, akin to language model instructions, has the potential to yield more aligned search targets. Prior studies restrict the application of instructions in information retrieval to a task description format, neglecting the broader context of diverse and evolving search scenarios. Furthermore, the prevailing benchmarks utilized for evaluation lack explicit tailoring to assess instruction-following ability, thereby hindering progress in this field. In response to these limitations, we propose a novel benchmark,INSTRUCTIR, specifically designed to evaluate instruction-following ability in information retrieval tasks. Our approach focuses on user-aligned instructions tailored to each query instance, reflecting the diverse characteristics inherent in real-world search scenarios. Through experimental analysis, we observe that retrievers fine-tuned to follow task-style instructions, such as INSTRUCTOR, can underperform compared to their non-instruction-tuned counterparts. This underscores potential overfitting issues inherent in constructing retrievers trained on existing instruction-aware retrieval datasets.
Aligning Large Language Models by On-Policy Self-Judgment
Feb 17, 2024To align large language models with human preferences, existing research either utilizes a separate reward model (RM) to perform on-policy learning or simplifies the training procedure by discarding the on-policy learning and the need for a separate RM. In this paper, we present a novel alignment framework, SELF-JUDGE that is (1) on-policy learning and 2) parameter efficient, as it does not require an additional RM for evaluating the samples for on-policy learning. To this end, we propose Judge-augmented Supervised Fine-Tuning (JSFT) to train a single model acting as both a policy and a judge. Specifically, we view the pairwise judgment task as a special case of the instruction-following task, choosing the better response from a response pair. Thus, the resulting model can judge preferences of on-the-fly responses from current policy initialized from itself. Experimental results show the efficacy of SELF-JUDGE, outperforming baselines in preference benchmarks. We also show that self-rejection with oversampling can improve further without an additional evaluator. Our code is available at https://github.com/oddqueue/self-judge.
Preference-free Alignment Learning with Regularized Relevance Reward
Feb 02, 2024Learning from human preference has been considered key to aligning Large Language Models (LLMs) with human values. However, contrary to popular belief, our preliminary study reveals that reward models trained on human preference datasets tend to give higher scores to long off-topic responses than short on-topic ones. Motivated by this observation, we explore a preference-free approach utilizing `relevance' as a key objective for alignment. On our first attempt, we find that the relevance score obtained by a retriever alone is vulnerable to reward hacking, i.e., overoptimizing to undesired shortcuts, when we utilize the score as a reward for reinforcement learning. To mitigate it, we integrate effective inductive biases into the vanilla relevance to regularize each other, resulting in a mixture of reward functions: Regularized Relevance Reward ($R^3$). $R^3$ significantly improves performance on preference benchmarks by providing a robust reward signal. Notably, $R^3$ does not require any human preference datasets (i.e., preference-free), outperforming open-source reward models in improving human preference. Our analysis demonstrates that $R^3$ has advantages in elevating human preference while minimizing its side effects. Finally, we show the generalizability of $R^3$, consistently improving instruction-tuned models in various backbones and sizes without additional dataset cost. Our code is available at https://github.com/naver-ai/RRR.
LangBridge: Multilingual Reasoning Without Multilingual Supervision
Jan 19, 2024We introduce LangBridge, a zero-shot approach to adapt language models for multilingual reasoning tasks without multilingual supervision. LangBridge operates by bridging two models, each specialized in different aspects: (1) one specialized in understanding multiple languages (e.g., mT5 encoder) and (2) one specialized in reasoning (e.g., Orca 2). LangBridge connects the two models by introducing minimal trainable parameters between them. Despite utilizing only English data for training, LangBridge considerably enhances the performance of language models on low-resource languages across mathematical reasoning, coding, and logical reasoning. Our analysis suggests that the efficacy of LangBridge stems from the language-agnostic characteristics of multilingual representations. We publicly release our code and models.
Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation
Jan 12, 2024Assessing long-form responses generated by Vision-Language Models (VLMs) is challenging. It not only requires checking whether the VLM follows the given instruction but also verifying whether the text output is properly grounded on the given image. Inspired by the recent approach of evaluating LMs with LMs, in this work, we propose to evaluate VLMs with VLMs. For this purpose, we present a new feedback dataset called the Perception Collection, encompassing 15K customized score rubrics that users might care about during assessment. Using the Perception Collection, we train Prometheus-Vision, the first open-source VLM evaluator model that can understand the user-defined score criteria during evaluation. Prometheus-Vision shows the highest Pearson correlation with human evaluators and GPT-4V among open-source models, showing its effectiveness for transparent and accessible evaluation of VLMs. We open-source our code, dataset, and model at https://github.com/kaistAI/prometheus-vision