 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIan R. Manchester
Learning Stable and Passive Neural Differential Equations
Apr 19, 2024
In this paper, we introduce a novel class of neural differential equation, which are intrinsically Lyapunov stable, exponentially stable or passive. We take a recently proposed Polyak Lojasiewicz network (PLNet) as an Lyapunov function and then parameterize the vector field as the descent directions of the Lyapunov function. The resulting models have a same structure as the general Hamiltonian dynamics, where the Hamiltonian is lower- and upper-bounded by quadratic functions. Moreover, it is also positive definite w.r.t. either a known or learnable equilibrium. We illustrate the effectiveness of the proposed model on a damped double pendulum system.
Monotone, Bi-Lipschitz, and Polyak-Lojasiewicz Networks
Feb 08, 2024This paper presents a new \emph{bi-Lipschitz} invertible neural network, the BiLipNet, which has the ability to control both its \emph{Lipschitzness} (output sensitivity to input perturbations) and \emph{inverse Lipschitzness} (input distinguishability from different outputs). The main contribution is a novel invertible residual layer with certified strong monotonicity and Lipschitzness, which we compose with orthogonal layers to build bi-Lipschitz networks. The certification is based on incremental quadratic constraints, which achieves much tighter bounds compared to spectral normalization. Moreover, we formulate the model inverse calculation as a three-operator splitting problem, for which fast algorithms are known. Based on the proposed bi-Lipschitz network, we introduce a new scalar-output network, the PLNet, which satisfies the Polyak-\L{}ojasiewicz condition. It can be applied to learn non-convex surrogate losses with favourable properties, e.g., a unique and efficiently-computable global minimum.
RobustNeuralNetworks.jl: a Package for Machine Learning and Data-Driven Control with Certified Robustness
Jun 22, 2023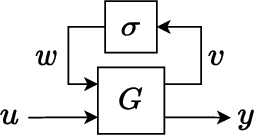
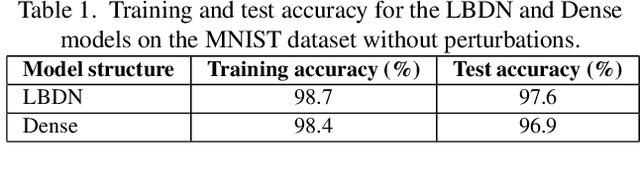
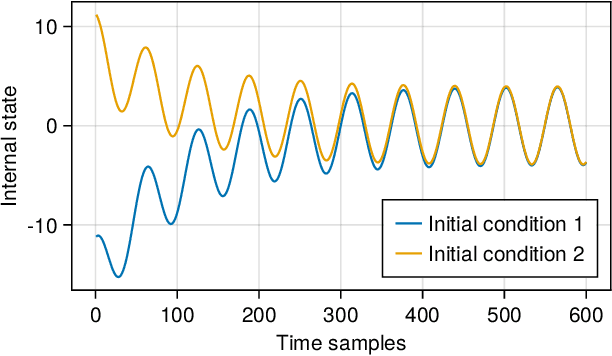
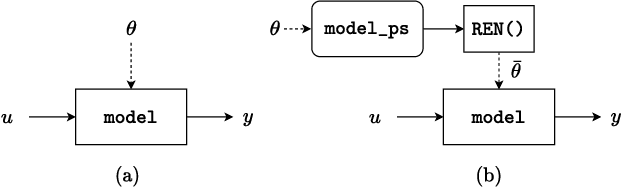
Neural networks are typically sensitive to small input perturbations, leading to unexpected or brittle behaviour. We present RobustNeuralNetworks.jl: a Julia package for neural network models that are constructed to naturally satisfy a set of user-defined robustness constraints. The package is based on the recently proposed Recurrent Equilibrium Network (REN) and Lipschitz-Bounded Deep Network (LBDN) model classes, and is designed to interface directly with Julia's most widely-used machine learning package, Flux.jl. We discuss the theory behind our model parameterization, give an overview of the package, and provide a tutorial demonstrating its use in image classification, reinforcement learning, and nonlinear state-observer design.
Learning Over All Contracting and Lipschitz Closed-Loops for Partially-Observed Nonlinear Systems
Apr 12, 2023



This paper presents a policy parameterization for learning-based control on nonlinear, partially-observed dynamical systems. The parameterization is based on a nonlinear version of the Youla parameterization and the recently proposed Recurrent Equilibrium Network (REN) class of models. We prove that the resulting Youla-REN parameterization automatically satisfies stability (contraction) and user-tunable robustness (Lipschitz) conditions on the closed-loop system. This means it can be used for safe learning-based control with no additional constraints or projections required to enforce stability or robustness. We test the new policy class in simulation on two reinforcement learning tasks: 1) magnetic suspension, and 2) inverting a rotary-arm pendulum. We find that the Youla-REN performs similarly to existing learning-based and optimal control methods while also ensuring stability and exhibiting improved robustness to adversarial disturbances.
Unconstrained Parametrization of Dissipative and Contracting Neural Ordinary Differential Equations
Apr 06, 2023


In this work, we introduce and study a class of Deep Neural Networks (DNNs) in continuous-time. The proposed architecture stems from the combination of Neural Ordinary Differential Equations (Neural ODEs) with the model structure of recently introduced Recurrent Equilibrium Networks (RENs). We show how to endow our proposed NodeRENs with contractivity and dissipativity -- crucial properties for robust learning and control. Most importantly, as for RENs, we derive parametrizations of contractive and dissipative NodeRENs which are unconstrained, hence enabling their learning for a large number of parameters. We validate the properties of NodeRENs, including the possibility of handling irregularly sampled data, in a case study in nonlinear system identification.
Lipschitz-bounded 1D convolutional neural networks using the Cayley transform and the controllability Gramian
Mar 20, 2023



We establish a layer-wise parameterization for 1D convolutional neural networks (CNNs) with built-in end-to-end robustness guarantees. Herein, we use the Lipschitz constant of the input-output mapping characterized by a CNN as a robustness measure. We base our parameterization on the Cayley transform that parameterizes orthogonal matrices and the controllability Gramian for the state space representation of the convolutional layers. The proposed parameterization by design fulfills linear matrix inequalities that are sufficient for Lipschitz continuity of the CNN, which further enables unconstrained training of Lipschitz-bounded 1D CNNs. Finally, we train Lipschitz-bounded 1D CNNs for the classification of heart arrythmia data and show their improved robustness.
Direct Parameterization of Lipschitz-Bounded Deep Networks
Jan 27, 2023



This paper introduces a new parameterization of deep neural networks (both fully-connected and convolutional) with guaranteed Lipschitz bounds, i.e. limited sensitivity to perturbations. The Lipschitz guarantees are equivalent to the tightest-known bounds based on certification via a semidefinite program (SDP), which does not scale to large models. In contrast to the SDP approach, we provide a ``direct'' parameterization, i.e. a smooth mapping from $\mathbb R^N$ onto the set of weights of Lipschitz-bounded networks. This enables training via standard gradient methods, without any computationally intensive projections or barrier terms. The new parameterization can equivalently be thought of as either a new layer type (the \textit{sandwich layer}), or a novel parameterization of standard feedforward networks with parameter sharing between neighbouring layers. We illustrate the method with some applications in image classification (MNIST and CIFAR-10).
Globally convergent visual-feature range estimation with biased inertial measurements
Dec 23, 2021



The design of a globally convergent position observer for feature points from visual information is a challenging problem, especially for the case with only inertial measurements and without assumptions of uniform observability, which remained open for a long time. We give a solution to the problem in this paper assuming that only the bearing of a feature point, and biased linear acceleration and rotational velocity of a robot -- all in the body-fixed frame -- are available. Further, in contrast to existing related results, we do not need the value of the gravitational constant either. The proposed approach builds upon the parameter estimation-based observer recently developed in (Ortega et al., Syst. Control. Lett., vol.85, 2015) and its extension to matrix Lie groups in our previous work. Conditions on the robot trajectory under which the observer converges are given, and these are strictly weaker than the standard persistency of excitation and uniform complete observability conditions. Finally, we apply the proposed design to the visual inertial navigation problem. Simulation results are also presented to illustrate our observer design.
Learning over All Stabilizing Nonlinear Controllers for a Partially-Observed Linear System
Dec 08, 2021



We propose a parameterization of nonlinear output feedback controllers for linear dynamical systems based on a recently developed class of neural network called the recurrent equilibrium network (REN), and a nonlinear version of the Youla parameterization. Our approach guarantees the closed-loop stability of partially observable linear dynamical systems without requiring any constraints to be satisfied. This significantly simplifies model fitting as any unconstrained optimization procedure can be applied whilst still maintaining stability. We demonstrate our method on reinforcement learning tasks with both exact and approximate gradient methods. Simulation studies show that our method is significantly more scalable and significantly outperforms other approaches in the same problem setting.
Youla-REN: Learning Nonlinear Feedback Policies with Robust Stability Guarantees
Dec 02, 2021



This paper presents a parameterization of nonlinear controllers for uncertain systems building on a recently developed neural network architecture, called the recurrent equilibrium network (REN), and a nonlinear version of the Youla parameterization. The proposed framework has "built-in" guarantees of stability, i.e., all policies in the search space result in a contracting (globally exponentially stable) closed-loop system. Thus, it requires very mild assumptions on the choice of cost function and the stability property can be generalized to unseen data. Another useful feature of this approach is that policies are parameterized directly without any constraints, which simplifies learning by a broad range of policy-learning methods based on unconstrained optimization (e.g. stochastic gradient descent). We illustrate the proposed approach with a variety of simulation examples.