 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Cheng
Learning Stable and Passive Neural Differential Equations
Apr 19, 2024
In this paper, we introduce a novel class of neural differential equation, which are intrinsically Lyapunov stable, exponentially stable or passive. We take a recently proposed Polyak Lojasiewicz network (PLNet) as an Lyapunov function and then parameterize the vector field as the descent directions of the Lyapunov function. The resulting models have a same structure as the general Hamiltonian dynamics, where the Hamiltonian is lower- and upper-bounded by quadratic functions. Moreover, it is also positive definite w.r.t. either a known or learnable equilibrium. We illustrate the effectiveness of the proposed model on a damped double pendulum system.
Proximal Gradient Descent Unfolding Dense-spatial Spectral-attention Transformer for Compressive Spectral Imaging
Dec 25, 2023The Coded Aperture Snapshot Spectral Compressive Imaging (CASSI) system modulates three-dimensional hyperspectral images into two-dimensional compressed images in a single exposure. Subsequently, three-dimensional hyperspectral images (HSI) can be reconstructed from the two-dimensional compressed measurements using reconstruction algorithms. Among these methods, deep unfolding techniques have demonstrated excellent performance, with RDLUF-MixS^2 achieving the best reconstruction results. However, RDLUF-MixS^2 requires extensive training time, taking approximately 14 days to train RDLUF-MixS^2-9stg on a single RTX 3090 GPU, making it computationally expensive. Furthermore, RDLUF-MixS^2 performs poorly on real data, resulting in significant artifacts in the reconstructed images. In this study, we introduce the Dense-spatial Spectral-attention Transformer (DST) into the Proximal Gradient Descent Unfolding Framework (PGDUF), creating a novel approach called Proximal Gradient Descent Unfolding Dense-spatial Spectral-attention Transformer (PGDUDST). Compared to RDLUF-MixS^2, PGDUDST not only surpasses the network reconstruction performance limit of RDLUF-MixS^2 but also achieves faster convergence. PGDUDST requires only 58% of the training time of RDLUF-MixS^2-9stg to achieve comparable reconstruction results. Additionally, PGDUDST significantly alleviates the artifact issues caused by RDLUF-MixS^2 in real experimental data, demonstrating superior performance and producing clearer reconstructed images.
Physics-Informed DeepMRI: Bridging the Gap from Heat Diffusion to k-Space Interpolation
Aug 30, 2023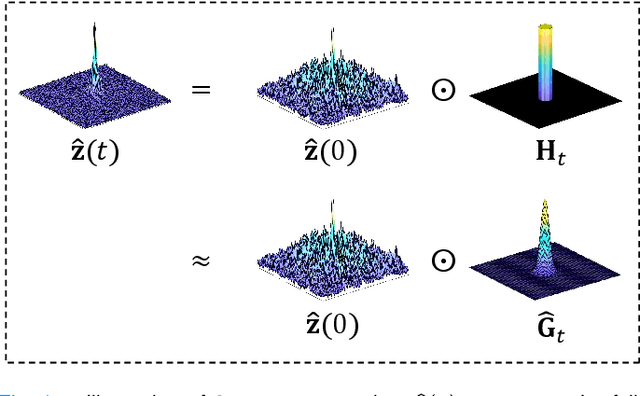
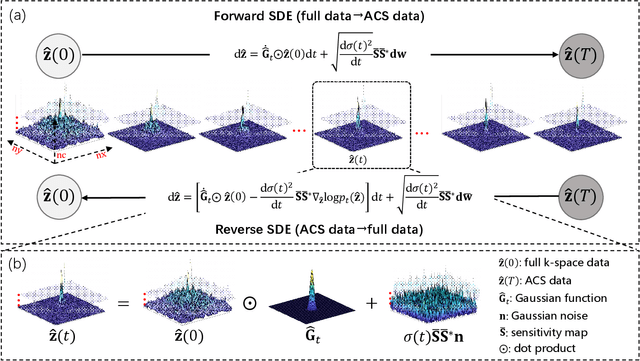
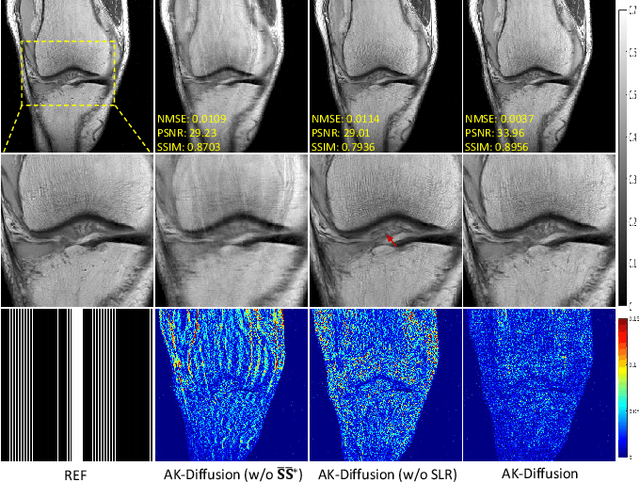
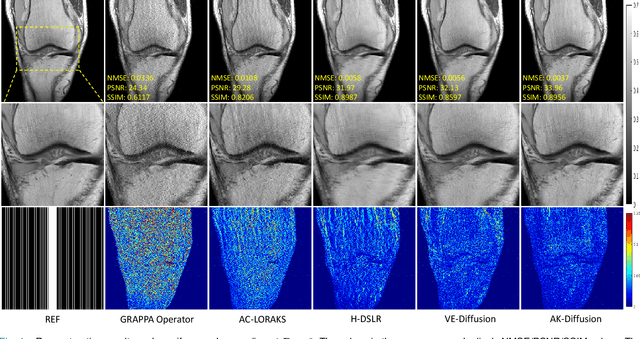
In the field of parallel imaging (PI), alongside image-domain regularization methods, substantial research has been dedicated to exploring $k$-space interpolation. However, the interpretability of these methods remains an unresolved issue. Furthermore, these approaches currently face acceleration limitations that are comparable to those experienced by image-domain methods. In order to enhance interpretability and overcome the acceleration limitations, this paper introduces an interpretable framework that unifies both $k$-space interpolation techniques and image-domain methods, grounded in the physical principles of heat diffusion equations. Building upon this foundational framework, a novel $k$-space interpolation method is proposed. Specifically, we model the process of high-frequency information attenuation in $k$-space as a heat diffusion equation, while the effort to reconstruct high-frequency information from low-frequency regions can be conceptualized as a reverse heat equation. However, solving the reverse heat equation poses a challenging inverse problem. To tackle this challenge, we modify the heat equation to align with the principles of magnetic resonance PI physics and employ the score-based generative method to precisely execute the modified reverse heat diffusion. Finally, experimental validation conducted on publicly available datasets demonstrates the superiority of the proposed approach over traditional $k$-space interpolation methods, deep learning-based $k$-space interpolation methods, and conventional diffusion models in terms of reconstruction accuracy, particularly in high-frequency regions.
RobustNeuralNetworks.jl: a Package for Machine Learning and Data-Driven Control with Certified Robustness
Jun 22, 2023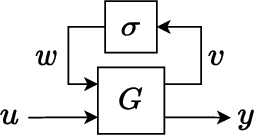
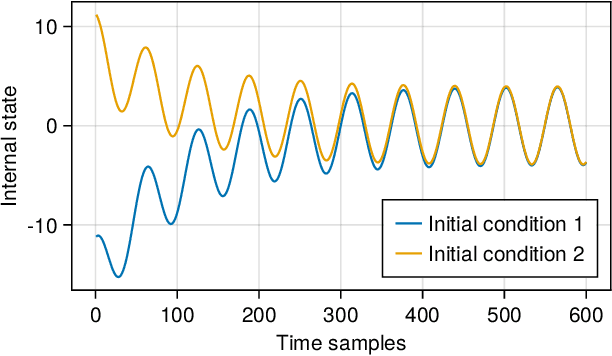
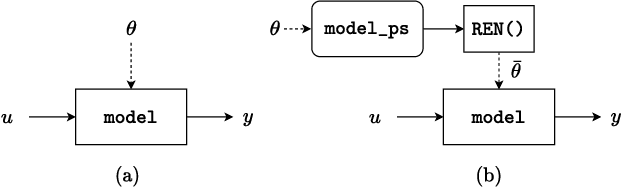
Neural networks are typically sensitive to small input perturbations, leading to unexpected or brittle behaviour. We present RobustNeuralNetworks.jl: a Julia package for neural network models that are constructed to naturally satisfy a set of user-defined robustness constraints. The package is based on the recently proposed Recurrent Equilibrium Network (REN) and Lipschitz-Bounded Deep Network (LBDN) model classes, and is designed to interface directly with Julia's most widely-used machine learning package, Flux.jl. We discuss the theory behind our model parameterization, give an overview of the package, and provide a tutorial demonstrating its use in image classification, reinforcement learning, and nonlinear state-observer design.
Meta-Learning Enabled Score-Based Generative Model for 1.5T-Like Image Reconstruction from 0.5T MRI
May 04, 2023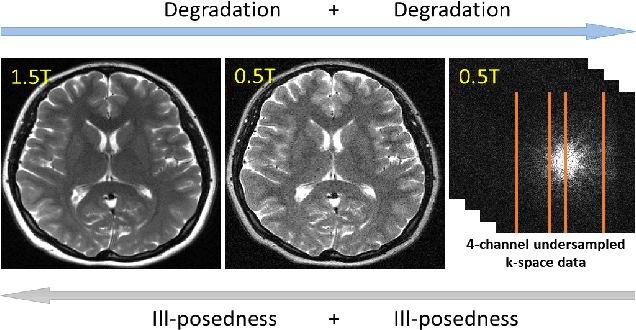
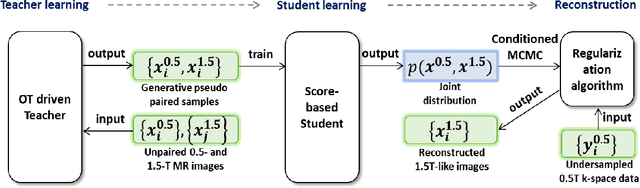
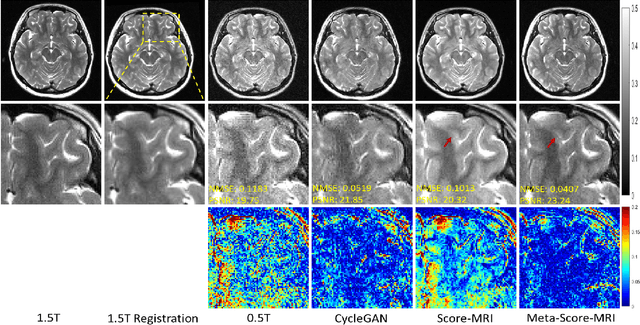
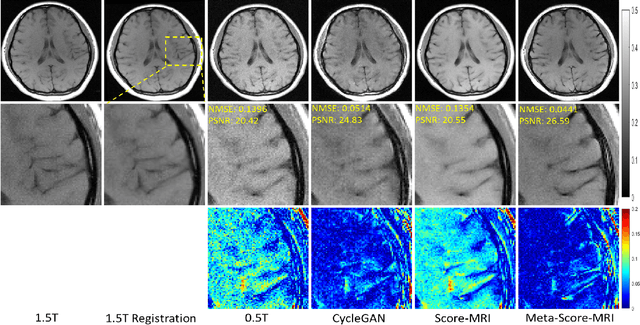
Magnetic resonance imaging (MRI) is known to have reduced signal-to-noise ratios (SNR) at lower field strengths, leading to signal degradation when producing a low-field MRI image from a high-field one. Therefore, reconstructing a high-field-like image from a low-field MRI is a complex problem due to the ill-posed nature of the task. Additionally, obtaining paired low-field and high-field MR images is often not practical. We theoretically uncovered that the combination of these challenges renders conventional deep learning methods that directly learn the mapping from a low-field MR image to a high-field MR image unsuitable. To overcome these challenges, we introduce a novel meta-learning approach that employs a teacher-student mechanism. Firstly, an optimal-transport-driven teacher learns the degradation process from high-field to low-field MR images and generates pseudo-paired high-field and low-field MRI images. Then, a score-based student solves the inverse problem of reconstructing a high-field-like MR image from a low-field MRI within the framework of iterative regularization, by learning the joint distribution of pseudo-paired images to act as a regularizer. Experimental results on real low-field MRI data demonstrate that our proposed method outperforms state-of-the-art unpaired learning methods.
SPIRiT-Diffusion: Self-Consistency Driven Diffusion Model for Accelerated MRI
Apr 11, 2023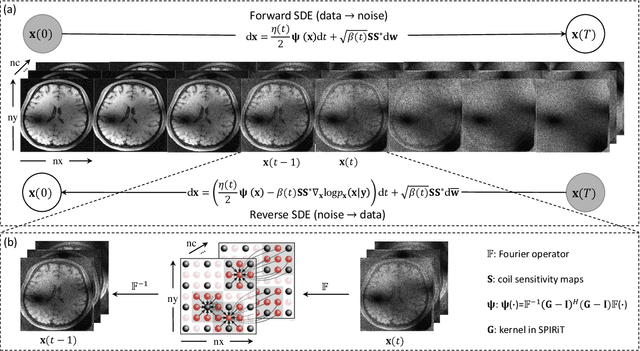
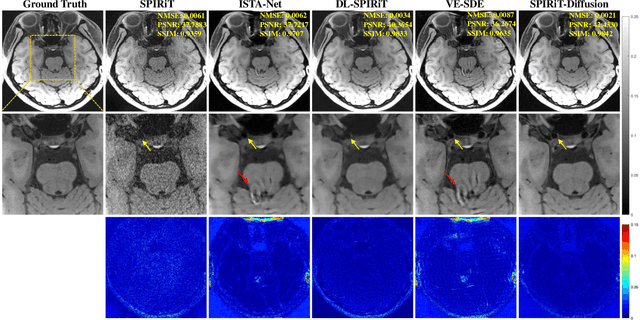
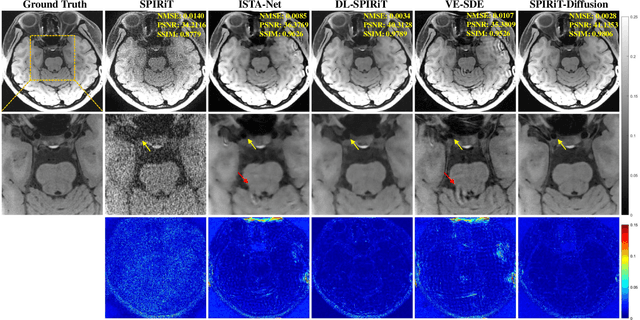
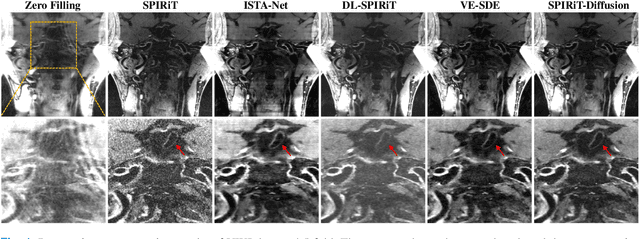
Diffusion models are a leading method for image generation and have been successfully applied in magnetic resonance imaging (MRI) reconstruction. Current diffusion-based reconstruction methods rely on coil sensitivity maps (CSM) to reconstruct multi-coil data. However, it is difficult to accurately estimate CSMs in practice use, resulting in degradation of the reconstruction quality. To address this issue, we propose a self-consistency-driven diffusion model inspired by the iterative self-consistent parallel imaging (SPIRiT), namely SPIRiT-Diffusion. Specifically, the iterative solver of the self-consistent term in SPIRiT is utilized to design a novel stochastic differential equation (SDE) for diffusion process. Then $\textit{k}$-space data can be interpolated directly during the reverse diffusion process, instead of using CSM to separate and combine individual coil images. This method indicates that the optimization model can be used to design SDE in diffusion models, driving the diffusion process strongly conforming with the physics involved in the optimization model, dubbed model-driven diffusion. The proposed SPIRiT-Diffusion method was evaluated on a 3D joint Intracranial and Carotid Vessel Wall imaging dataset. The results demonstrate that it outperforms the CSM-based reconstruction methods, and achieves high reconstruction quality at a high acceleration rate of 10.
Energetic Analysis on the Optimal Bounding Gaits of Quadrupedal Robots
Mar 08, 2023
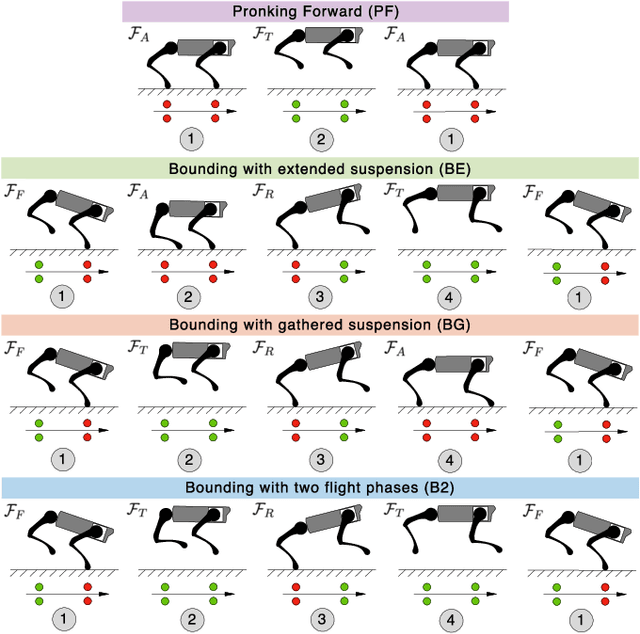
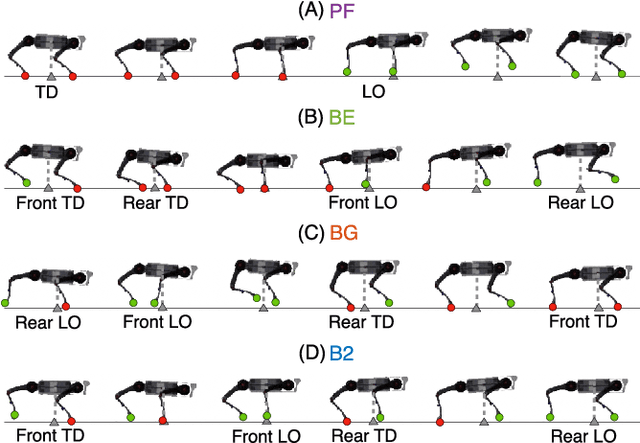
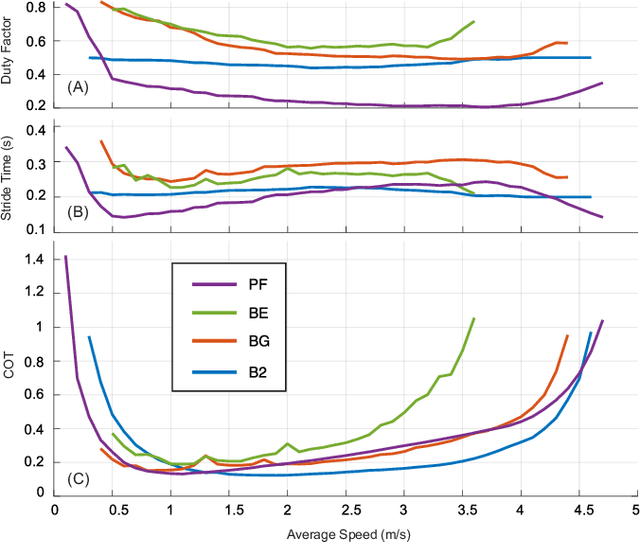
It is often overlooked by roboticists when designing locomotion controllers for their legged machines, that energy consumption plays an important role in selecting the best gaits for locomotion at high speeds or over long distances. The purpose of this study is to examine four similar asymmetrical quadrupedal gaits that are frequently observed in legged animals in nature. To understand how a specific footfall pattern will change the energetics of a legged system, we first developed a full body model of a quadrupedal robot called A1. And for each gait we created a hybrid system with desired footfall sequence and rigid impacts. In order to find the most energy efficient gait, we used optimal control methods to formulate the problem as a trajectory optimization problem with proper constraints and objective function. This problem was implemented and solved in a nonlinear programming framework called FROST. Based on the optimized trajectories for each gait, we investigated the values of cost of transport and the work done by all joints. Moreover, we analyzed the exchange of angular momentum in different components of the system during the whole stride cycle. According to the simulation results, bounding with two flight phases is likely to be the most energy efficient gait for A1 across a wide range of speed.
SPIRiT-Diffusion: SPIRiT-driven Score-Based Generative Modeling for Vessel Wall imaging
Dec 14, 2022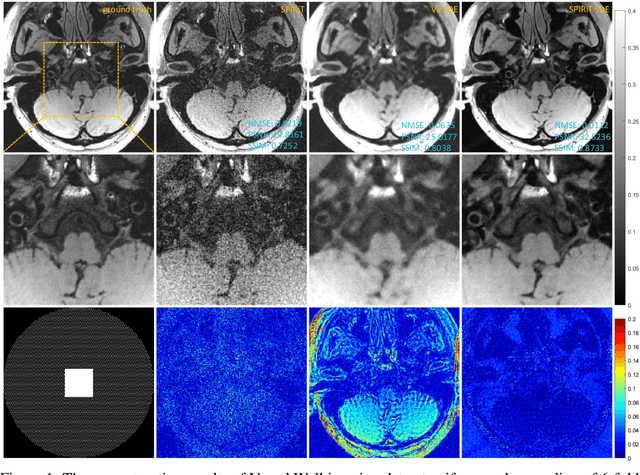
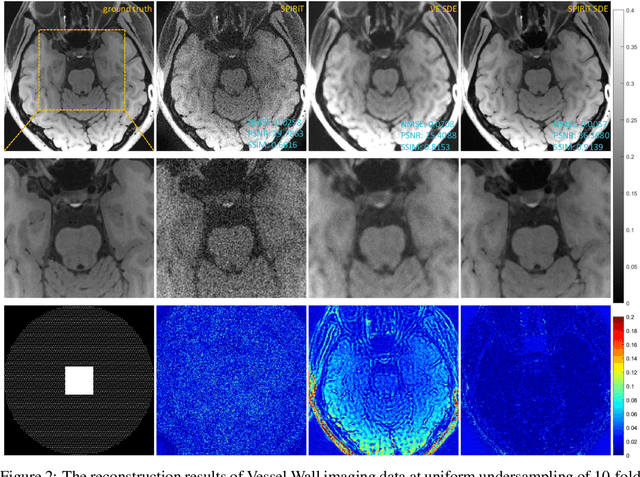
Diffusion model is the most advanced method in image generation and has been successfully applied to MRI reconstruction. However, the existing methods do not consider the characteristics of multi-coil acquisition of MRI data. Therefore, we give a new diffusion model, called SPIRiT-Diffusion, based on the SPIRiT iterative reconstruction algorithm. Specifically, SPIRiT-Diffusion characterizes the prior distribution of coil-by-coil images by score matching and characterizes the k-space redundant prior between coils based on self-consistency. With sufficient prior constraint utilized, we achieve superior reconstruction results on the joint Intracranial and Carotid Vessel Wall imaging dataset.
Deep unfolding as iterative regularization for imaging inverse problems
Nov 24, 2022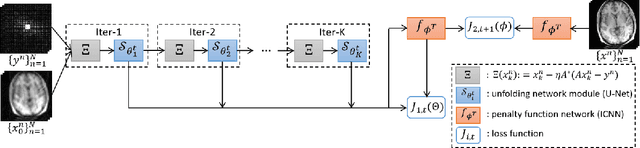
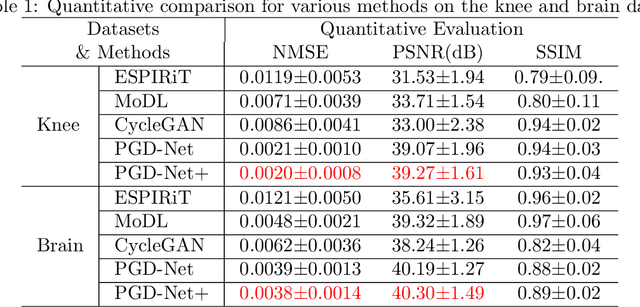

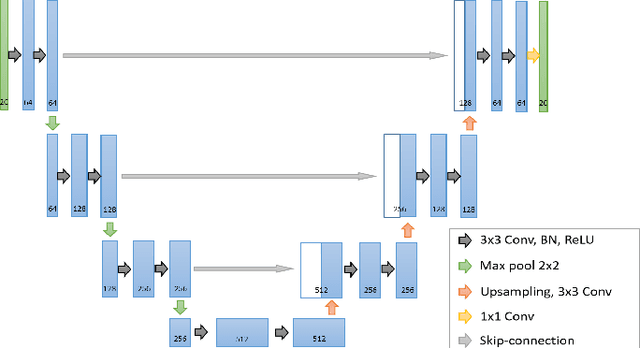
Recently, deep unfolding methods that guide the design of deep neural networks (DNNs) through iterative algorithms have received increasing attention in the field of inverse problems. Unlike general end-to-end DNNs, unfolding methods have better interpretability and performance. However, to our knowledge, their accuracy and stability in solving inverse problems cannot be fully guaranteed. To bridge this gap, we modified the training procedure and proved that the unfolding method is an iterative regularization method. More precisely, we jointly learn a convex penalty function adversarially by an input-convex neural network (ICNN) to characterize the distance to a real data manifold and train a DNN unfolded from the proximal gradient descent algorithm with this learned penalty. Suppose the real data manifold intersects the inverse problem solutions with only the unique real solution. We prove that the unfolded DNN will converge to it stably. Furthermore, we demonstrate with an example of MRI reconstruction that the proposed method outperforms conventional unfolding methods and traditional regularization methods in terms of reconstruction quality, stability and convergence speed.
Practice Makes Perfect: an iterative approach to achieve precise tracking for legged robots
Nov 22, 2022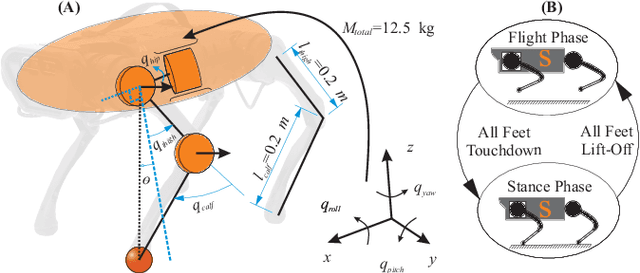
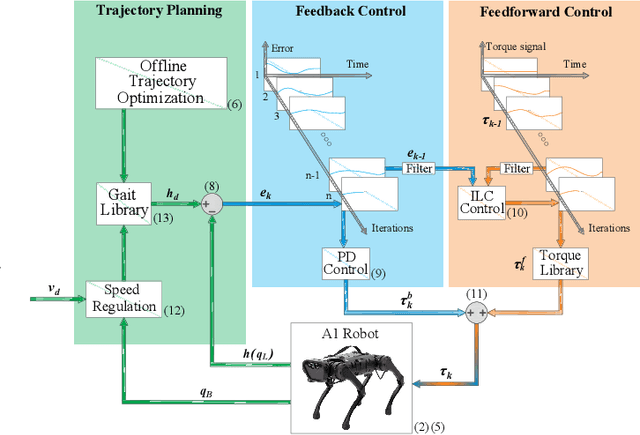
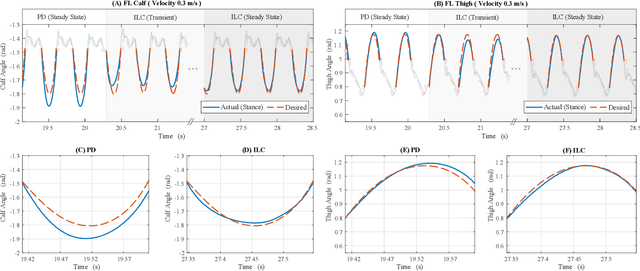
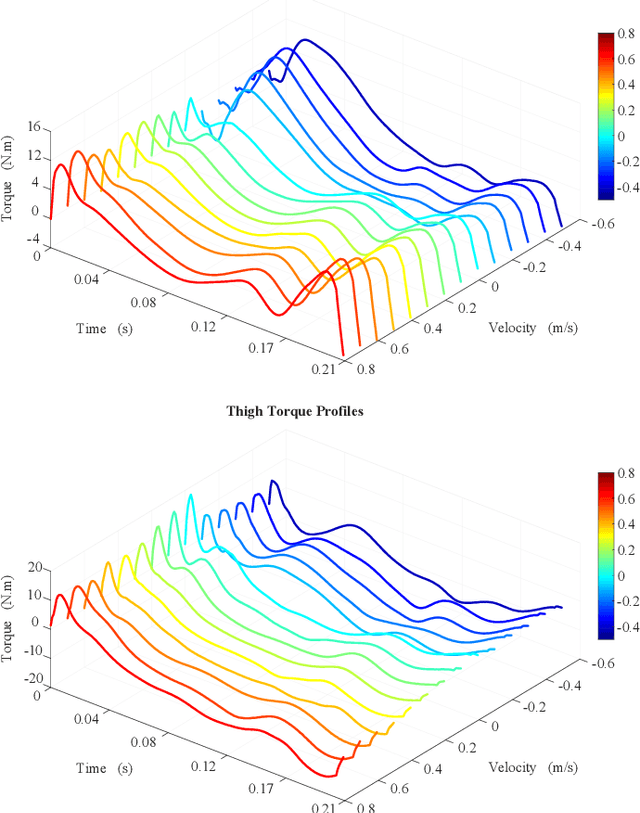
Precise trajectory tracking for legged robots can be challenging due to their high degrees of freedom, unmodeled nonlinear dynamics, or random disturbances from the environment. A commonly adopted solution to overcome these challenges is to use optimization-based algorithms and approximate the system with a simplified, reduced-order model. Additionally, deep neural networks are becoming a more promising option for achieving agile and robust legged locomotion. These approaches, however, either require large amounts of onboard calculations or the collection of millions of data points from a single robot. To address these problems and improve tracking performance, this paper proposes a method based on iterative learning control. This method lets a robot learn from its own mistakes by exploiting the repetitive nature of legged locomotion within only a few trials. Then, a torque library is created as a lookup table so that the robot does not need to repeat calculations or learn the same skill over and over again. This process resembles how animals learn their muscle memories in nature. The proposed method is tested on the A1 robot in a simulated environment, and it allows the robot to pronk at different speeds while precisely following the reference trajectories without heavy calculations.