 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSen Jia
Knowledge-driven deep learning for fast MR imaging: undersampled MR image reconstruction from supervised to un-supervised learning
Feb 05, 2024
Deep learning (DL) has emerged as a leading approach in accelerating MR imaging. It employs deep neural networks to extract knowledge from available datasets and then applies the trained networks to reconstruct accurate images from limited measurements. Unlike natural image restoration problems, MR imaging involves physics-based imaging processes, unique data properties, and diverse imaging tasks. This domain knowledge needs to be integrated with data-driven approaches. Our review will introduce the significant challenges faced by such knowledge-driven DL approaches in the context of fast MR imaging along with several notable solutions, which include learning neural networks and addressing different imaging application scenarios. The traits and trends of these techniques have also been given which have shifted from supervised learning to semi-supervised learning, and finally, to unsupervised learning methods. In addition, MR vendors' choices of DL reconstruction have been provided along with some discussions on open questions and future directions, which are critical for the reliable imaging systems.
Physics-Informed DeepMRI: Bridging the Gap from Heat Diffusion to k-Space Interpolation
Aug 30, 2023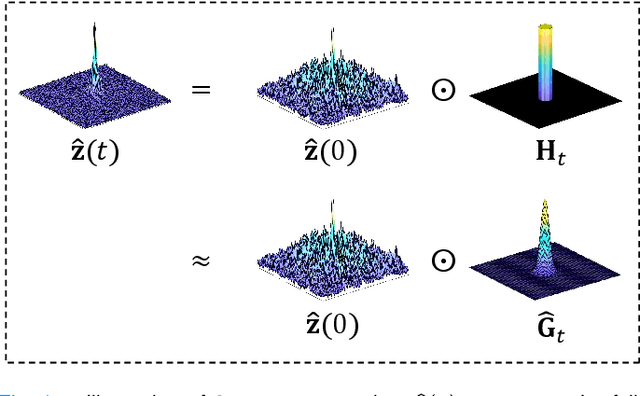
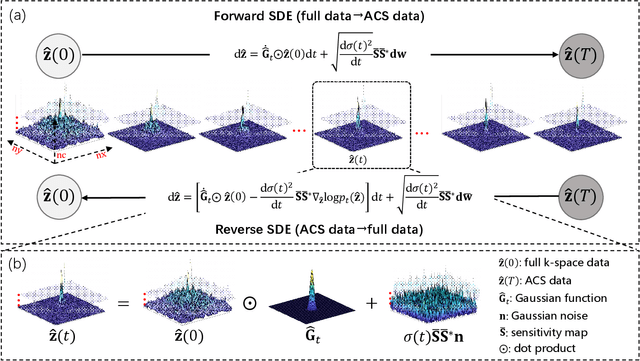
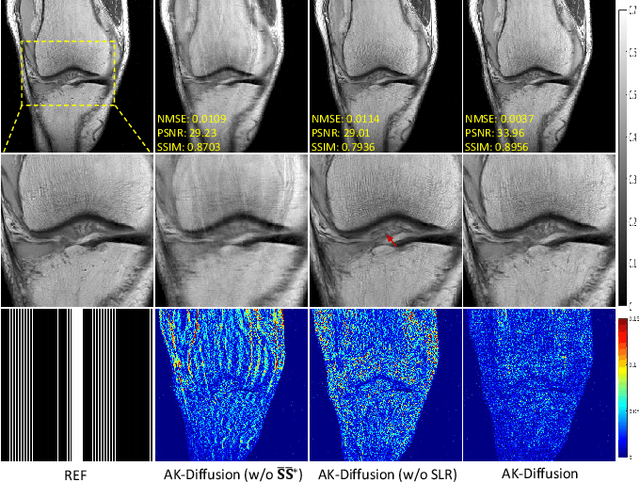
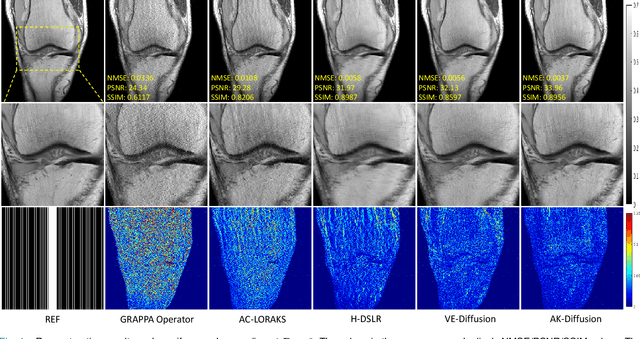
In the field of parallel imaging (PI), alongside image-domain regularization methods, substantial research has been dedicated to exploring $k$-space interpolation. However, the interpretability of these methods remains an unresolved issue. Furthermore, these approaches currently face acceleration limitations that are comparable to those experienced by image-domain methods. In order to enhance interpretability and overcome the acceleration limitations, this paper introduces an interpretable framework that unifies both $k$-space interpolation techniques and image-domain methods, grounded in the physical principles of heat diffusion equations. Building upon this foundational framework, a novel $k$-space interpolation method is proposed. Specifically, we model the process of high-frequency information attenuation in $k$-space as a heat diffusion equation, while the effort to reconstruct high-frequency information from low-frequency regions can be conceptualized as a reverse heat equation. However, solving the reverse heat equation poses a challenging inverse problem. To tackle this challenge, we modify the heat equation to align with the principles of magnetic resonance PI physics and employ the score-based generative method to precisely execute the modified reverse heat diffusion. Finally, experimental validation conducted on publicly available datasets demonstrates the superiority of the proposed approach over traditional $k$-space interpolation methods, deep learning-based $k$-space interpolation methods, and conventional diffusion models in terms of reconstruction accuracy, particularly in high-frequency regions.
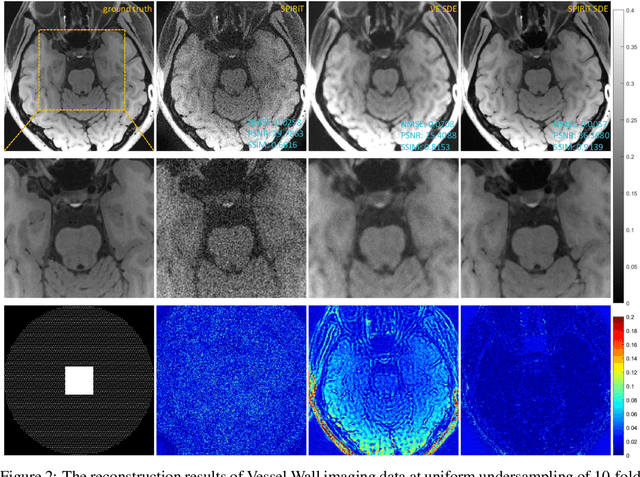
SPIRiT-Diffusion: Self-Consistency Driven Diffusion Model for Accelerated MRI
Apr 11, 2023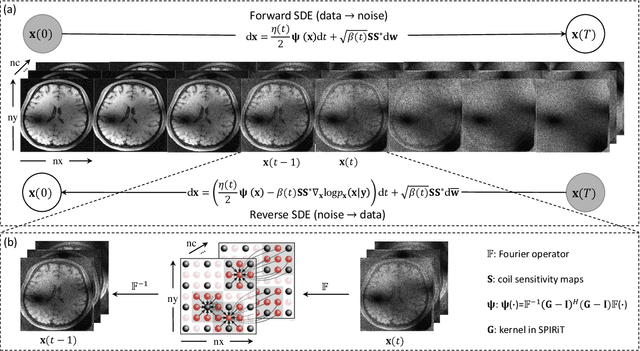
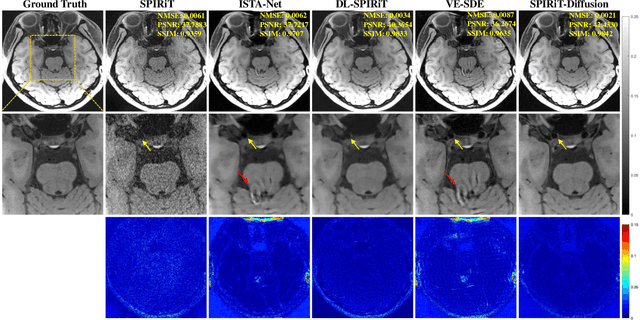
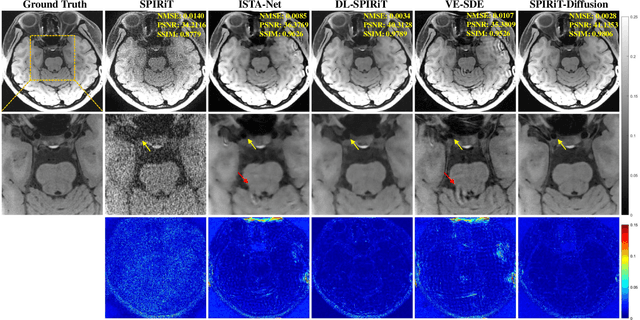
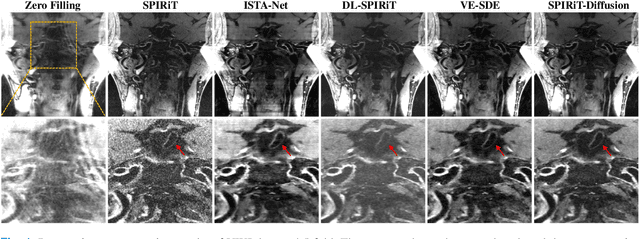
Diffusion models are a leading method for image generation and have been successfully applied in magnetic resonance imaging (MRI) reconstruction. Current diffusion-based reconstruction methods rely on coil sensitivity maps (CSM) to reconstruct multi-coil data. However, it is difficult to accurately estimate CSMs in practice use, resulting in degradation of the reconstruction quality. To address this issue, we propose a self-consistency-driven diffusion model inspired by the iterative self-consistent parallel imaging (SPIRiT), namely SPIRiT-Diffusion. Specifically, the iterative solver of the self-consistent term in SPIRiT is utilized to design a novel stochastic differential equation (SDE) for diffusion process. Then $\textit{k}$-space data can be interpolated directly during the reverse diffusion process, instead of using CSM to separate and combine individual coil images. This method indicates that the optimization model can be used to design SDE in diffusion models, driving the diffusion process strongly conforming with the physics involved in the optimization model, dubbed model-driven diffusion. The proposed SPIRiT-Diffusion method was evaluated on a 3D joint Intracranial and Carotid Vessel Wall imaging dataset. The results demonstrate that it outperforms the CSM-based reconstruction methods, and achieves high reconstruction quality at a high acceleration rate of 10.
SPIRiT-Diffusion: SPIRiT-driven Score-Based Generative Modeling for Vessel Wall imaging
Dec 14, 2022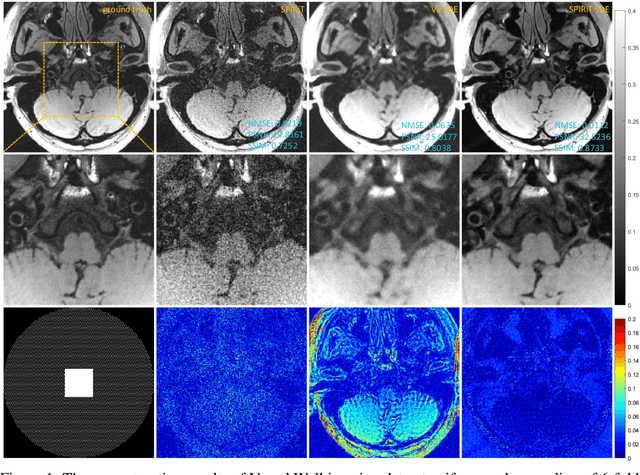
Diffusion model is the most advanced method in image generation and has been successfully applied to MRI reconstruction. However, the existing methods do not consider the characteristics of multi-coil acquisition of MRI data. Therefore, we give a new diffusion model, called SPIRiT-Diffusion, based on the SPIRiT iterative reconstruction algorithm. Specifically, SPIRiT-Diffusion characterizes the prior distribution of coil-by-coil images by score matching and characterizes the k-space redundant prior between coils based on self-consistency. With sufficient prior constraint utilized, we achieve superior reconstruction results on the joint Intracranial and Carotid Vessel Wall imaging dataset.
K-UNN: k-Space Interpolation With Untrained Neural Network
Aug 11, 2022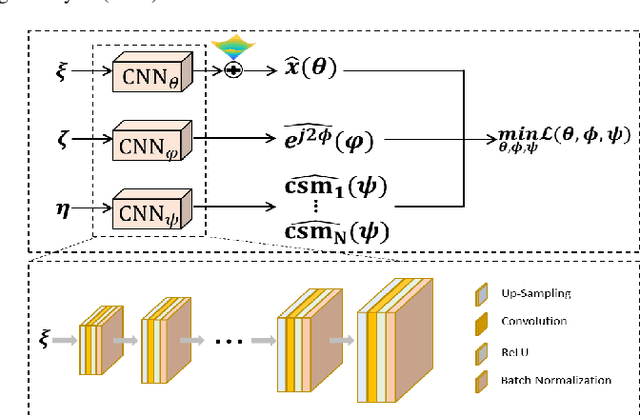
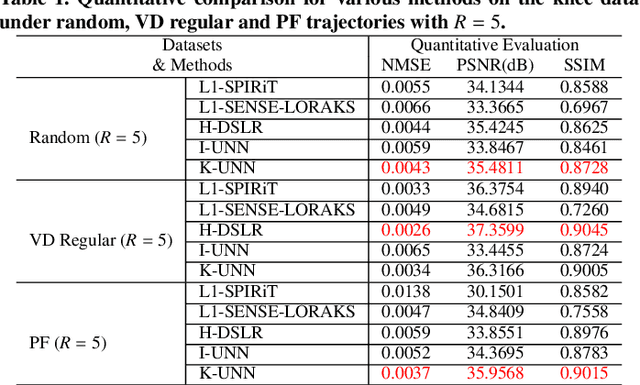


Recently, untrained neural networks (UNNs) have shown satisfactory performances for MR image reconstruction on random sampling trajectories without using additional full-sampled training data. However, the existing UNN-based approach does not fully use the MR image physical priors, resulting in poor performance in some common scenarios (e.g., partial Fourier, regular sampling, etc.) and the lack of theoretical guarantees for reconstruction accuracy. To bridge this gap, we propose a safeguarded k-space interpolation method for MRI using a specially designed UNN with a tripled architecture driven by three physical priors of the MR images (or k-space data), including sparsity, coil sensitivity smoothness, and phase smoothness. We also prove that the proposed method guarantees tight bounds for interpolated k-space data accuracy. Finally, ablation experiments show that the proposed method can more accurately characterize the physical priors of MR images than existing traditional methods. Additionally, under a series of commonly used sampling trajectories, experiments also show that the proposed method consistently outperforms traditional parallel imaging methods and existing UNNs, and even outperforms the state-of-the-art supervised-trained k-space deep learning methods in some cases.
SelfCoLearn: Self-supervised collaborative learning for accelerating dynamic MR imaging
Aug 08, 2022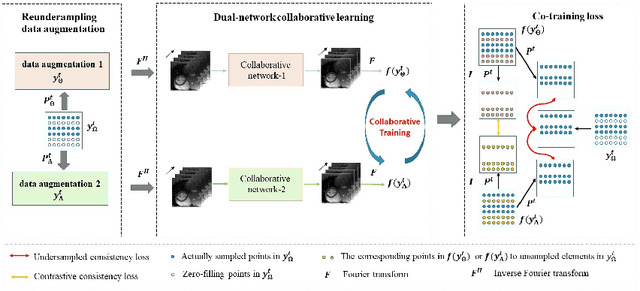
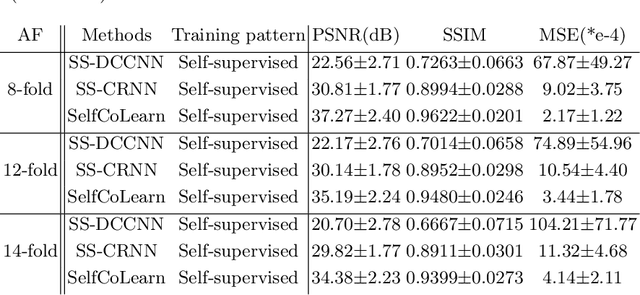
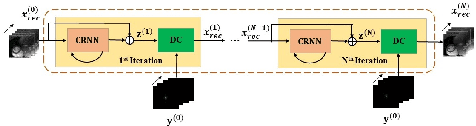
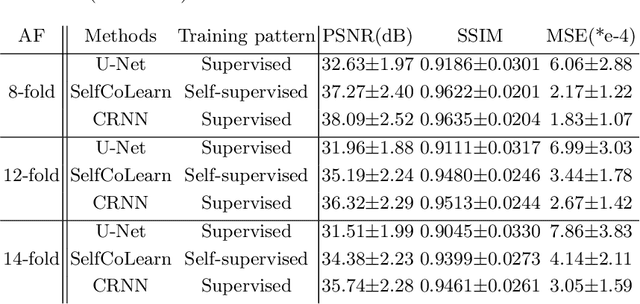
Lately, deep learning has been extensively investigated for accelerating dynamic magnetic resonance (MR) imaging, with encouraging progresses achieved. However, without fully sampled reference data for training, current approaches may have limited abilities in recovering fine details or structures. To address this challenge, this paper proposes a self-supervised collaborative learning framework (SelfCoLearn) for accurate dynamic MR image reconstruction from undersampled k-space data. The proposed framework is equipped with three important components, namely, dual-network collaborative learning, reunderampling data augmentation and a specially designed co-training loss. The framework is flexible to be integrated with both data-driven networks and model-based iterative un-rolled networks. Our method has been evaluated on in-vivo dataset and compared it to four state-of-the-art methods. Results show that our method possesses strong capabilities in capturing essential and inherent representations for direct reconstructions from the undersampled k-space data and thus enables high-quality and fast dynamic MR imaging.
Multiscale Convolutional Transformer with Center Mask Pretraining for Hyperspectral Image Classification
Mar 21, 2022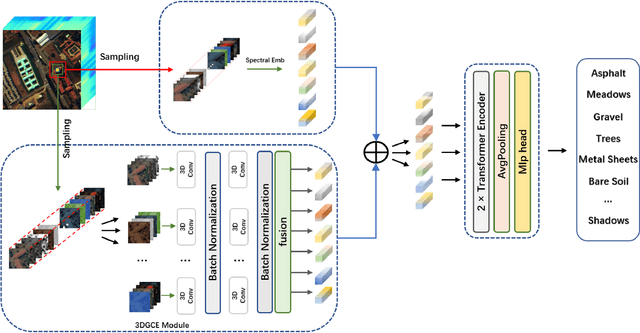
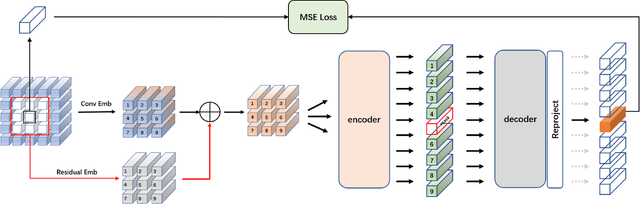
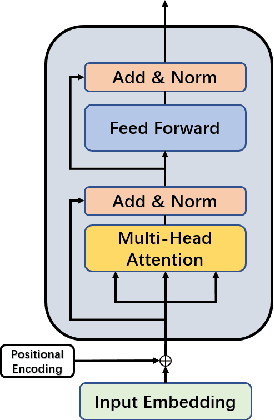
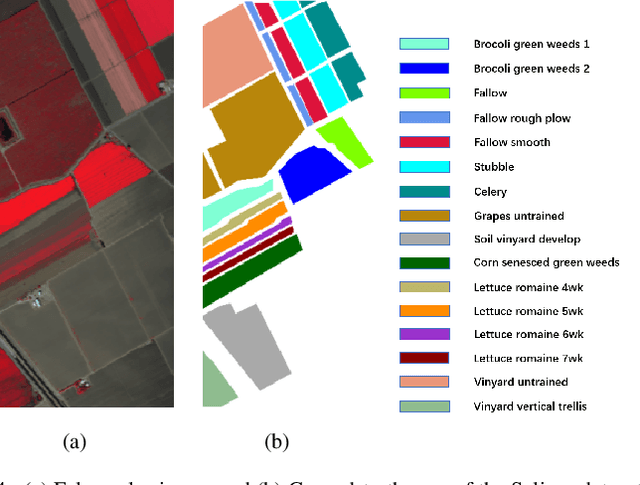
Hyperspectral images (HSI) not only have a broad macroscopic field of view but also contain rich spectral information, and the types of surface objects can be identified through spectral information, which is one of the main applications in hyperspectral image related research.In recent years, more and more deep learning methods have been proposed, among which convolutional neural networks (CNN) are the most influential. However, CNN-based methods are difficult to capture long-range dependencies, and also require a large amount of labeled data for model training.Besides, most of the self-supervised training methods in the field of HSI classification are based on the reconstruction of input samples, and it is difficult to achieve effective use of unlabeled samples. To address the shortcomings of CNN networks, we propose a noval multi-scale convolutional embedding module for HSI to realize effective extraction of spatial-spectral information, which can be better combined with Transformer network.In order to make more efficient use of unlabeled data, we propose a new self-supervised pretask. Similar to Mask autoencoder, but our pre-training method only masks the corresponding token of the central pixel in the encoder, and inputs the remaining token into the decoder to reconstruct the spectral information of the central pixel.Such a pretask can better model the relationship between the central feature and the domain feature, and obtain more stable training results.
Equilibrated Zeroth-Order Unrolled Deep Networks for Accelerated MRI
Dec 23, 2021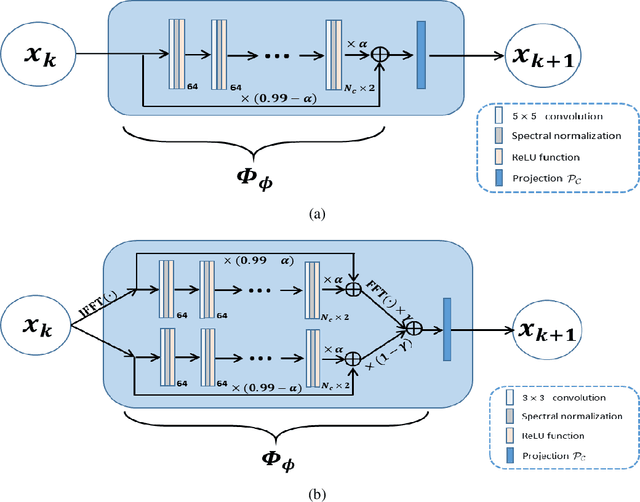
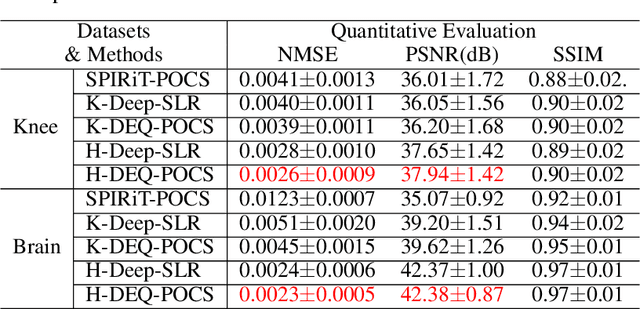

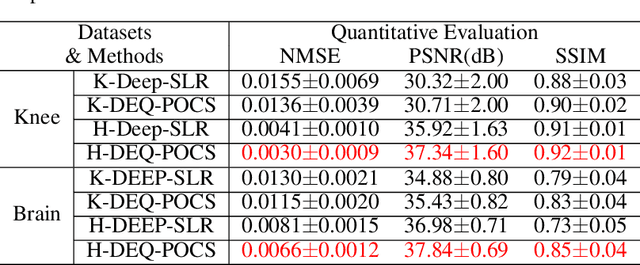
Recently, model-driven deep learning unrolls a certain iterative algorithm of a regularization model into a cascade network by replacing the first-order information (i.e., (sub)gradient or proximal operator) of the regularizer with a network module, which appears more explainable and predictable compared to common data-driven networks. Conversely, in theory, there is not necessarily such a functional regularizer whose first-order information matches the replaced network module, which means the network output may not be covered by the original regularization model. Moreover, up to now, there is also no theory to guarantee the global convergence and robustness (regularity) of unrolled networks under realistic assumptions. To bridge this gap, this paper propose to present a safeguarded methodology on network unrolling. Specifically, focusing on accelerated MRI, we unroll a zeroth-order algorithm, of which the network module represents the regularizer itself, so that the network output can be still covered by the regularization model. Furthermore, inspired by the ideal of deep equilibrium models, before backpropagating, we carry out the unrolled iterative network to converge to a fixed point to ensure the convergence. In case the measurement data contains noise, we prove that the proposed network is robust against noisy interference. Finally, numerical experiments show that the proposed network consistently outperforms the state-of-the-art MRI reconstruction methods including traditional regularization methods and other deep learning methods.
A Survey: Deep Learning for Hyperspectral Image Classification with Few Labeled Samples
Dec 03, 2021

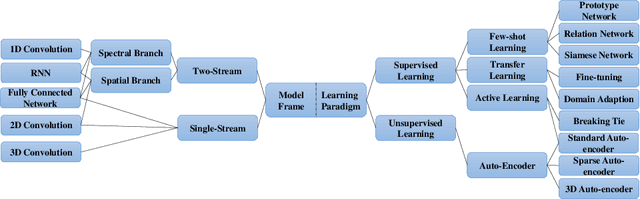
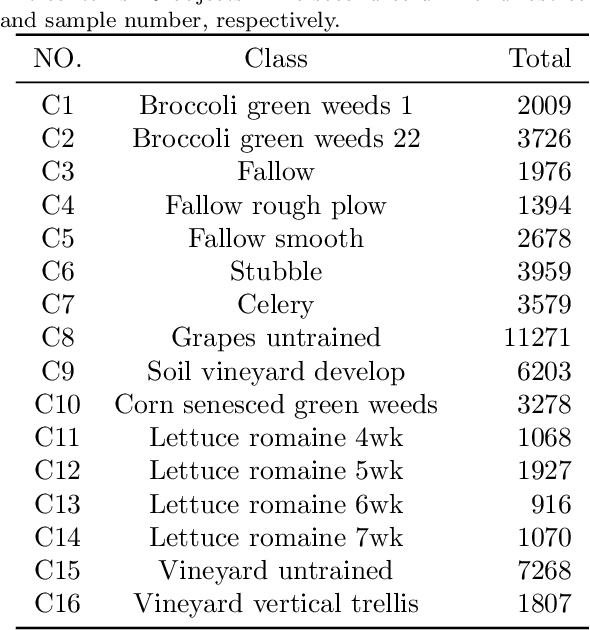
With the rapid development of deep learning technology and improvement in computing capability, deep learning has been widely used in the field of hyperspectral image (HSI) classification. In general, deep learning models often contain many trainable parameters and require a massive number of labeled samples to achieve optimal performance. However, in regard to HSI classification, a large number of labeled samples is generally difficult to acquire due to the difficulty and time-consuming nature of manual labeling. Therefore, many research works focus on building a deep learning model for HSI classification with few labeled samples. In this article, we concentrate on this topic and provide a systematic review of the relevant literature. Specifically, the contributions of this paper are twofold. First, the research progress of related methods is categorized according to the learning paradigm, including transfer learning, active learning and few-shot learning. Second, a number of experiments with various state-of-the-art approaches has been carried out, and the results are summarized to reveal the potential research directions. More importantly, it is notable that although there is a vast gap between deep learning models (that usually need sufficient labeled samples) and the HSI scenario with few labeled samples, the issues of small-sample sets can be well characterized by fusion of deep learning methods and related techniques, such as transfer learning and a lightweight model. For reproducibility, the source codes of the methods assessed in the paper can be found at https://github.com/ShuGuoJ/HSI-Classification.git.
Simpler Does It: Generating Semantic Labels with Objectness Guidance
Oct 20, 2021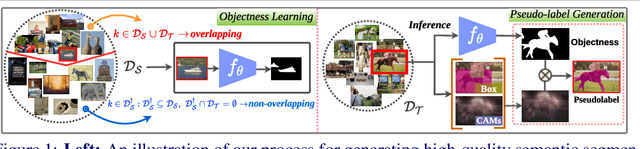
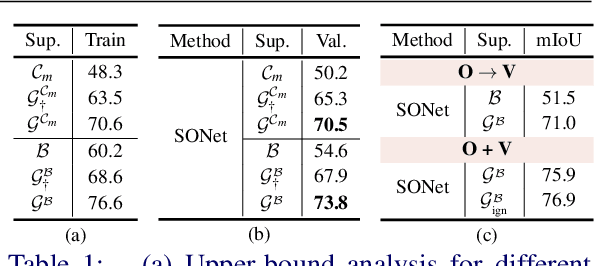
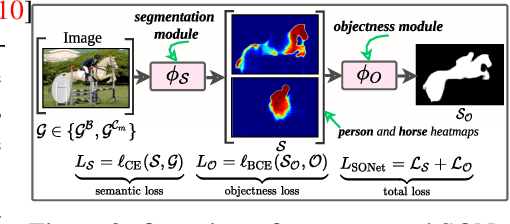
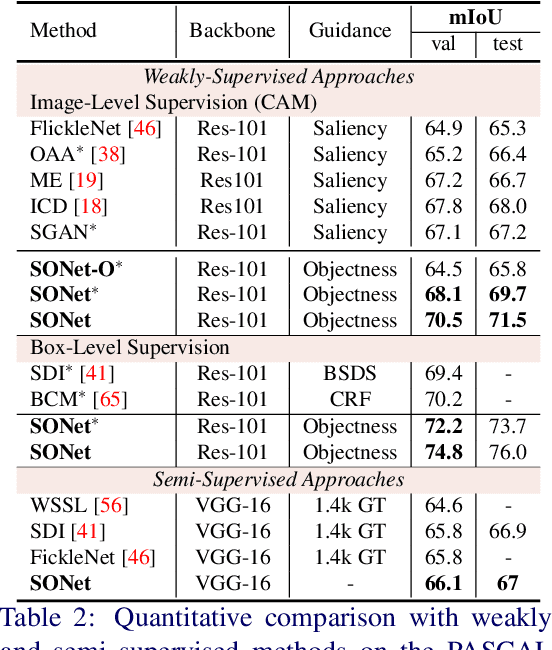
Existing weakly or semi-supervised semantic segmentation methods utilize image or box-level supervision to generate pseudo-labels for weakly labeled images. However, due to the lack of strong supervision, the generated pseudo-labels are often noisy near the object boundaries, which severely impacts the network's ability to learn strong representations. To address this problem, we present a novel framework that generates pseudo-labels for training images, which are then used to train a segmentation model. To generate pseudo-labels, we combine information from: (i) a class agnostic objectness network that learns to recognize object-like regions, and (ii) either image-level or bounding box annotations. We show the efficacy of our approach by demonstrating how the objectness network can naturally be leveraged to generate object-like regions for unseen categories. We then propose an end-to-end multi-task learning strategy, that jointly learns to segment semantics and objectness using the generated pseudo-labels. Extensive experiments demonstrate the high quality of our generated pseudo-labels and effectiveness of the proposed framework in a variety of domains. Our approach achieves better or competitive performance compared to existing weakly-supervised and semi-supervised methods.