 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgnacio Alzugaray
Distributed Simultaneous Localisation and Auto-Calibration using Gaussian Belief Propagation
Jan 26, 2024
We present a novel scalable, fully distributed, and online method for simultaneous localisation and extrinsic calibration for multi-robot setups. Individual a priori unknown robot poses are probabilistically inferred as robots sense each other while simultaneously calibrating their sensors and markers extrinsic using Gaussian Belief Propagation. In the presented experiments, we show how our method not only yields accurate robot localisation and auto-calibration but also is able to perform under challenging circumstances such as highly noisy measurements, significant communication failures or limited communication range.
* Published in IEEE Robotics and Automation Letters (RA-L) 2024
Fit-NGP: Fitting Object Models to Neural Graphics Primitives
Jan 04, 2024Accurate 3D object pose estimation is key to enabling many robotic applications that involve challenging object interactions. In this work, we show that the density field created by a state-of-the-art efficient radiance field reconstruction method is suitable for highly accurate and robust pose estimation for objects with known 3D models, even when they are very small and with challenging reflective surfaces. We present a fully automatic object pose estimation system based on a robot arm with a single wrist-mounted camera, which can scan a scene from scratch, detect and estimate the 6-Degrees of Freedom (DoF) poses of multiple objects within a couple of minutes of operation. Small objects such as bolts and nuts are estimated with accuracy on order of 1mm.
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Dec 07, 2023We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Continuous-Time Gaussian Process Motion-Compensation for Event-vision Pattern Tracking with Distance Fields
Mar 05, 2023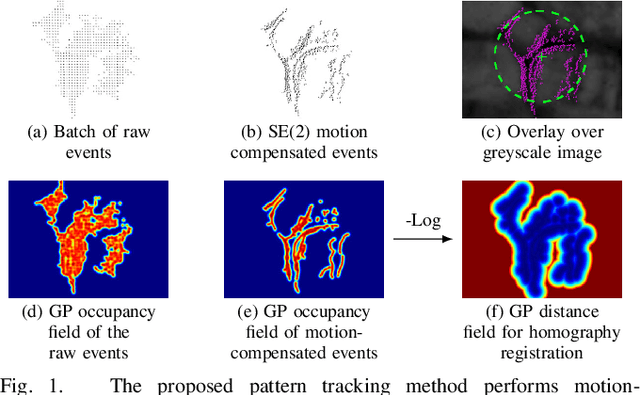
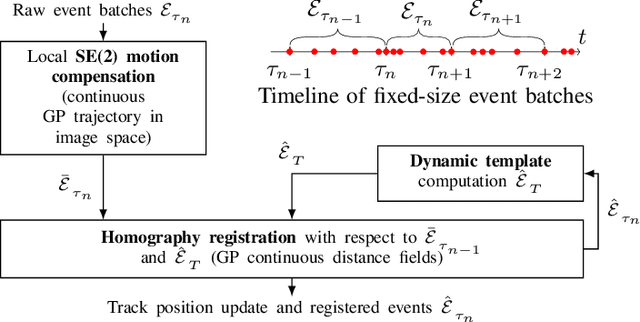

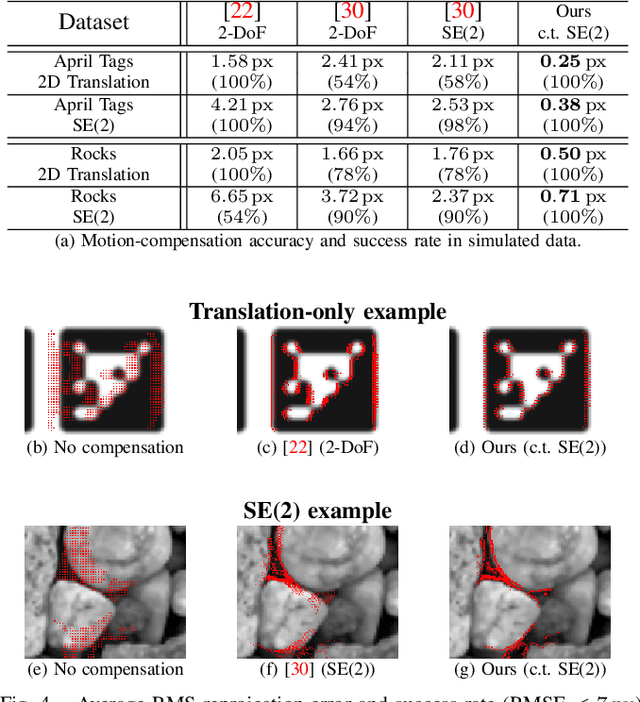
This work addresses the issue of motion compensation and pattern tracking in event camera data. An event camera generates asynchronous streams of events triggered independently by each of the pixels upon changes in the observed intensity. Providing great advantages in low-light and rapid-motion scenarios, such unconventional data present significant research challenges as traditional vision algorithms are not directly applicable to this sensing modality. The proposed method decomposes the tracking problem into a local SE(2) motion-compensation step followed by a homography registration of small motion-compensated event batches. The first component relies on Gaussian Process (GP) theory to model the continuous occupancy field of the events in the image plane and embed the camera trajectory in the covariance kernel function. In doing so, estimating the trajectory is done similarly to GP hyperparameter learning by maximising the log marginal likelihood of the data. The continuous occupancy fields are turned into distance fields and used as templates for homography-based registration. By benchmarking the proposed method against other state-of-the-art techniques, we show that our open-source implementation performs high-accuracy motion compensation and produces high-quality tracks in real-world scenarios.
IDOL: A Framework for IMU-DVS Odometry using Lines
Aug 13, 2020



In this paper, we introduce IDOL, an optimization-based framework for IMU-DVS Odometry using Lines. Event cameras, also called Dynamic Vision Sensors (DVSs), generate highly asynchronous streams of events triggered upon illumination changes for each individual pixel. This novel paradigm presents advantages in low illumination conditions and high-speed motions. Nonetheless, this unconventional sensing modality brings new challenges to perform scene reconstruction or motion estimation. The proposed method offers to leverage a continuous-time representation of the inertial readings to associate each event with timely accurate inertial data. The method's front-end extracts event clusters that belong to line segments in the environment whereas the back-end estimates the system's trajectory alongside the lines' 3D position by minimizing point-to-line distances between individual events and the lines' projection in the image space. A novel attraction/repulsion mechanism is presented to accurately estimate the lines' extremities, avoiding their explicit detection in the event data. The proposed method is benchmarked against a state-of-the-art frame-based visual-inertial odometry framework using public datasets. The results show that IDOL performs at the same order of magnitude on most datasets and even shows better orientation estimates. These findings can have a great impact on new algorithms for DVS.