 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIrene Li
KG-Rank: Enhancing Large Language Models for Medical QA with Knowledge Graphs and Ranking Techniques
Mar 09, 2024
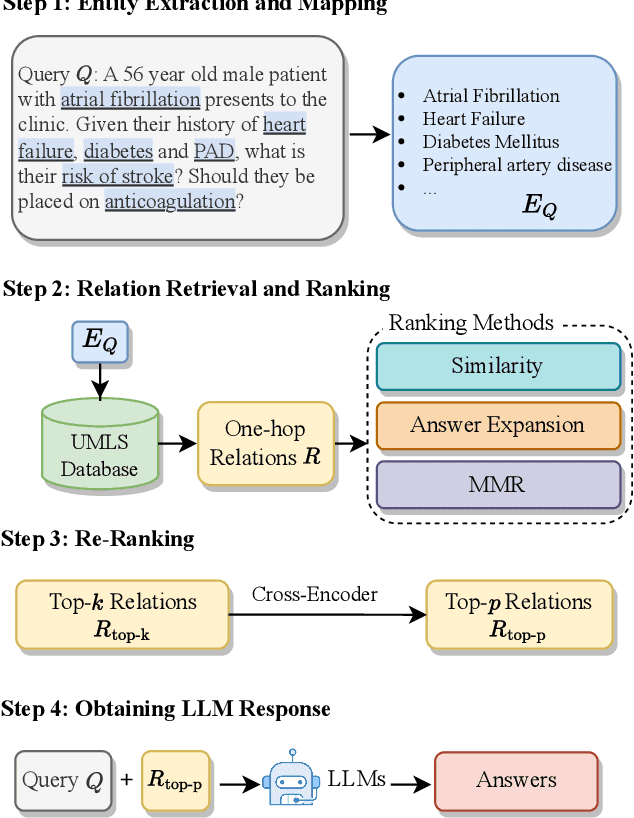
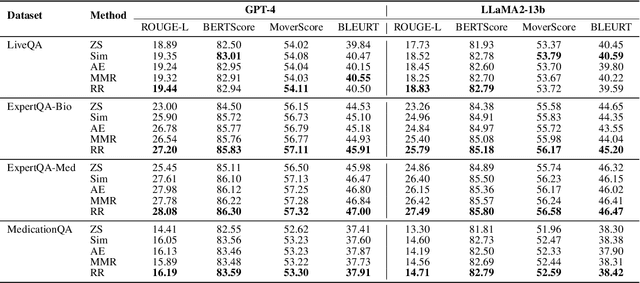
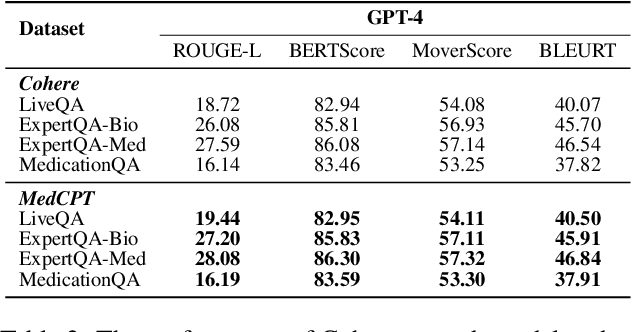
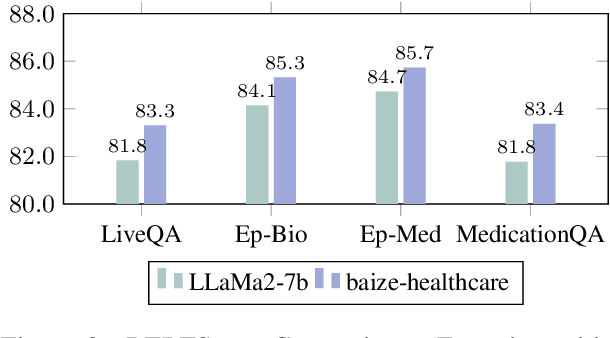
Large Language Models (LLMs) have significantly advanced healthcare innovation on generation capabilities. However, their application in real clinical settings is challenging due to potential deviations from medical facts and inherent biases. In this work, we develop an augmented LLM framework, KG-Rank, which leverages a medical knowledge graph (KG) with ranking and re-ranking techniques, aiming to improve free-text question-answering (QA) in the medical domain. Specifically, upon receiving a question, we initially retrieve triplets from a medical KG to gather factual information. Subsequently, we innovatively apply ranking methods to refine the ordering of these triplets, aiming to yield more precise answers. To the best of our knowledge, KG-Rank is the first application of ranking models combined with KG in medical QA specifically for generating long answers. Evaluation of four selected medical QA datasets shows that KG-Rank achieves an improvement of over 18% in the ROUGE-L score. Moreover, we extend KG-Rank to open domains, where it realizes a 14% improvement in ROUGE-L, showing the effectiveness and potential of KG-Rank.
Leveraging Large Language Models for Learning Complex Legal Concepts through Storytelling
Feb 26, 2024Making legal knowledge accessible to non-experts is crucial for enhancing general legal literacy and encouraging civic participation in democracy. However, legal documents are often challenging to understand for people without legal backgrounds. In this paper, we present a novel application of large language models (LLMs) in legal education to help non-experts learn intricate legal concepts through storytelling, an effective pedagogical tool in conveying complex and abstract concepts. We also introduce a new dataset LegalStories, which consists of 295 complex legal doctrines, each accompanied by a story and a set of multiple-choice questions generated by LLMs. To construct the dataset, we experiment with various LLMs to generate legal stories explaining these concepts. Furthermore, we use an expert-in-the-loop method to iteratively design multiple-choice questions. Then, we evaluate the effectiveness of storytelling with LLMs through an RCT experiment with legal novices on 10 samples from the dataset. We find that LLM-generated stories enhance comprehension of legal concepts and interest in law among non-native speakers compared to only definitions. Moreover, stories consistently help participants relate legal concepts to their lives. Finally, we find that learning with stories shows a higher retention rate for non-native speakers in the follow-up assessment. Our work has strong implications for using LLMs in promoting teaching and learning in the legal field and beyond.
Leveraging Large Language Models for Concept Graph Recovery and Question Answering in NLP Education
Feb 22, 2024In the domain of Natural Language Processing (NLP), Large Language Models (LLMs) have demonstrated promise in text-generation tasks. However, their educational applications, particularly for domain-specific queries, remain underexplored. This study investigates LLMs' capabilities in educational scenarios, focusing on concept graph recovery and question-answering (QA). We assess LLMs' zero-shot performance in creating domain-specific concept graphs and introduce TutorQA, a new expert-verified NLP-focused benchmark for scientific graph reasoning and QA. TutorQA consists of five tasks with 500 QA pairs. To tackle TutorQA queries, we present CGLLM, a pipeline integrating concept graphs with LLMs for answering diverse questions. Our results indicate that LLMs' zero-shot concept graph recovery is competitive with supervised methods, showing an average 3% F1 score improvement. In TutorQA tasks, LLMs achieve up to 26% F1 score enhancement. Moreover, human evaluation and analysis show that CGLLM generates answers with more fine-grained concepts.
Better Explain Transformers by Illuminating Important Information
Jan 26, 2024Transformer-based models excel in various natural language processing (NLP) tasks, attracting countless efforts to explain their inner workings. Prior methods explain Transformers by focusing on the raw gradient and attention as token attribution scores, where non-relevant information is often considered during explanation computation, resulting in confusing results. In this work, we propose highlighting the important information and eliminating irrelevant information by a refined information flow on top of the layer-wise relevance propagation (LRP) method. Specifically, we consider identifying syntactic and positional heads as important attention heads and focus on the relevance obtained from these important heads. Experimental results demonstrate that irrelevant information does distort output attribution scores and then should be masked during explanation computation. Compared to eight baselines on both classification and question-answering datasets, our method consistently outperforms with over 3\% to 33\% improvement on explanation metrics, providing superior explanation performance. Our anonymous code repository is available at: https://github.com/LinxinS97/Mask-LRP
RecPrompt: A Prompt Tuning Framework for News Recommendation Using Large Language Models
Dec 16, 2023In the evolving field of personalized news recommendation, understanding the semantics of the underlying data is crucial. Large Language Models (LLMs) like GPT-4 have shown promising performance in understanding natural language. However, the extent of their applicability in news recommendation systems remains to be validated. This paper introduces RecPrompt, the first framework for news recommendation that leverages the capabilities of LLMs through prompt engineering. This system incorporates a prompt optimizer that applies an iterative bootstrapping process, enhancing the LLM-based recommender's ability to align news content with user preferences and interests more effectively. Moreover, this study offers insights into the effective use of LLMs in news recommendation, emphasizing both the advantages and the challenges of incorporating LLMs into recommendation systems.
MedGen: A Python Natural Language Processing Toolkit for Medical Text Processing
Nov 28, 2023This study introduces MedGen, a comprehensive natural language processing (NLP) toolkit designed for medical text processing. MedGen is tailored for biomedical researchers and healthcare professionals with an easy-to-use, all-in-one solution that requires minimal programming expertise. It includes (1) Generative Functions: For the first time, MedGen includes four advanced generative functions: question answering, text summarization, text simplification, and machine translation; (2) Basic NLP Functions: MedGen integrates 12 essential NLP functions such as word tokenization and sentence segmentation; and (3) Query and Search Capabilities: MedGen provides user-friendly query and search functions on text corpora. We fine-tuned 32 domain-specific language models, evaluated them thoroughly on 24 established benchmarks and conducted manual reviews with clinicians. Additionally, we expanded our toolkit by introducing query and search functions, while also standardizing and integrating functions from third-party libraries. The toolkit, its models, and associated data are publicly available via https://github.com/Yale-LILY/MedGen.
Integrating UMLS Knowledge into Large Language Models for Medical Question Answering
Oct 13, 2023Large language models (LLMs) have demonstrated powerful text generation capabilities, bringing unprecedented innovation to the healthcare field. While LLMs hold immense promise for applications in healthcare, applying them to real clinical scenarios presents significant challenges, as these models may generate content that deviates from established medical facts and even exhibit potential biases. In our research, we develop an augmented LLM framework based on the Unified Medical Language System (UMLS), aiming to better serve the healthcare community. We employ LLaMa2-13b-chat and ChatGPT-3.5 as our benchmark models, and conduct automatic evaluations using the ROUGE Score and BERTScore on 104 questions from the LiveQA test set. Additionally, we establish criteria for physician-evaluation based on four dimensions: Factuality, Completeness, Readability and Relevancy. ChatGPT-3.5 is used for physician evaluation with 20 questions on the LiveQA test set. Multiple resident physicians conducted blind reviews to evaluate the generated content, and the results indicate that this framework effectively enhances the factuality, completeness, and relevance of generated content. Our research demonstrates the effectiveness of using UMLS-augmented LLMs and highlights the potential application value of LLMs in in medical question-answering.
NLPBench: Evaluating Large Language Models on Solving NLP Problems
Oct 08, 2023Recent developments in large language models (LLMs) have shown promise in enhancing the capabilities of natural language processing (NLP). Despite these successes, there remains a dearth of research dedicated to the NLP problem-solving abilities of LLMs. To fill the gap in this area, we present a unique benchmarking dataset, NLPBench, comprising 378 college-level NLP questions spanning various NLP topics sourced from Yale University's prior final exams. NLPBench includes questions with context, in which multiple sub-questions share the same public information, and diverse question types, including multiple choice, short answer, and math. Our evaluation, centered on LLMs such as GPT-3.5/4, PaLM-2, and LLAMA-2, incorporates advanced prompting strategies like the chain-of-thought (CoT) and tree-of-thought (ToT). Our study reveals that the effectiveness of the advanced prompting strategies can be inconsistent, occasionally damaging LLM performance, especially in smaller models like the LLAMA-2 (13b). Furthermore, our manual assessment illuminated specific shortcomings in LLMs' scientific problem-solving skills, with weaknesses in logical decomposition and reasoning notably affecting results.
Large Language Models on Wikipedia-Style Survey Generation: an Evaluation in NLP Concepts
Sep 06, 2023



Large Language Models (LLMs) have achieved significant success across various natural language processing (NLP) tasks, encompassing question-answering, summarization, and machine translation, among others. While LLMs excel in general tasks, their efficacy in domain-specific applications remains under exploration. Additionally, LLM-generated text sometimes exhibits issues like hallucination and disinformation. In this study, we assess LLMs' capability of producing concise survey articles within the computer science-NLP domain, focusing on 20 chosen topics. Automated evaluations indicate that GPT-4 outperforms GPT-3.5 when benchmarked against the ground truth. Furthermore, four human evaluators provide insights from six perspectives across four model configurations. Through case studies, we demonstrate that while GPT often yields commendable results, there are instances of shortcomings, such as incomplete information and the exhibition of lapses in factual accuracy.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 31, 2023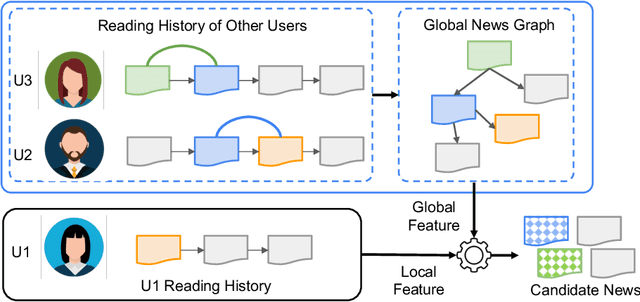


Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.