 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToyotaro Suzumura
Beyond Spatio-Temporal Representations: Evolving Fourier Transform for Temporal Graphs
Feb 25, 2024
We present the Evolving Graph Fourier Transform (EFT), the first invertible spectral transform that captures evolving representations on temporal graphs. We motivate our work by the inadequacy of existing methods for capturing the evolving graph spectra, which are also computationally expensive due to the temporal aspect along with the graph vertex domain. We view the problem as an optimization over the Laplacian of the continuous time dynamic graph. Additionally, we propose pseudo-spectrum relaxations that decompose the transformation process, making it highly computationally efficient. The EFT method adeptly captures the evolving graph's structural and positional properties, making it effective for downstream tasks on evolving graphs. Hence, as a reference implementation, we develop a simple neural model induced with EFT for capturing evolving graph spectra. We empirically validate our theoretical findings on a number of large-scale and standard temporal graph benchmarks and demonstrate that our model achieves state-of-the-art performance.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023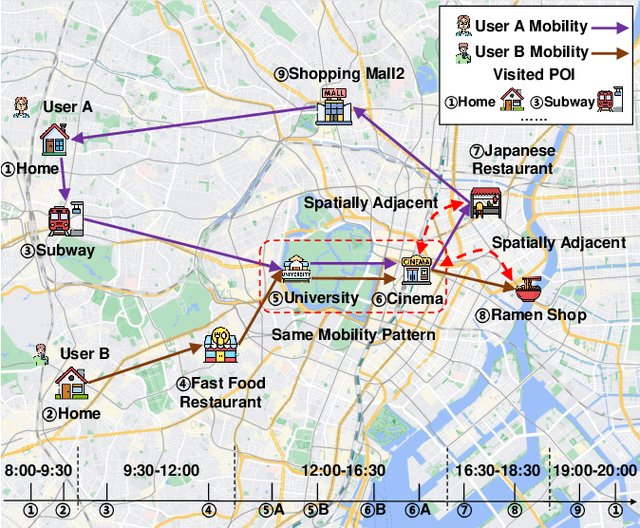

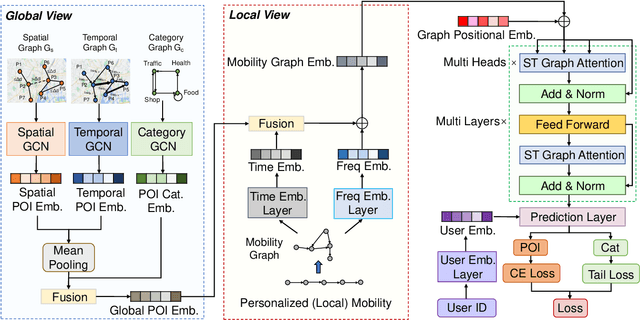
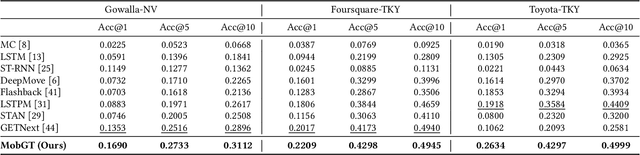
Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.
On Data Imbalance in Molecular Property Prediction with Pre-training
Aug 17, 2023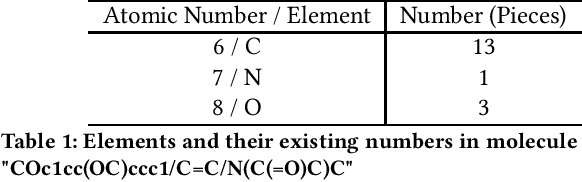
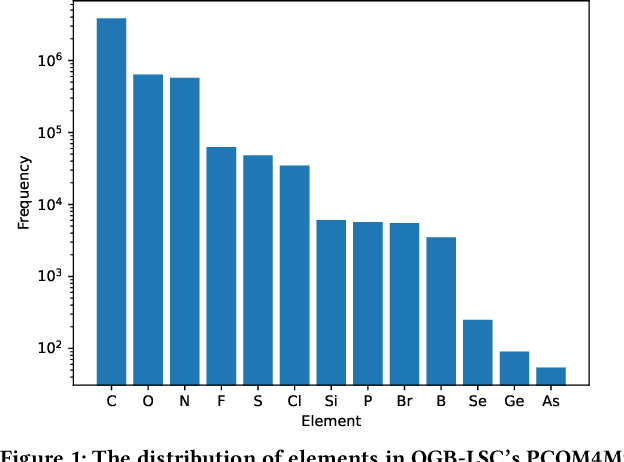
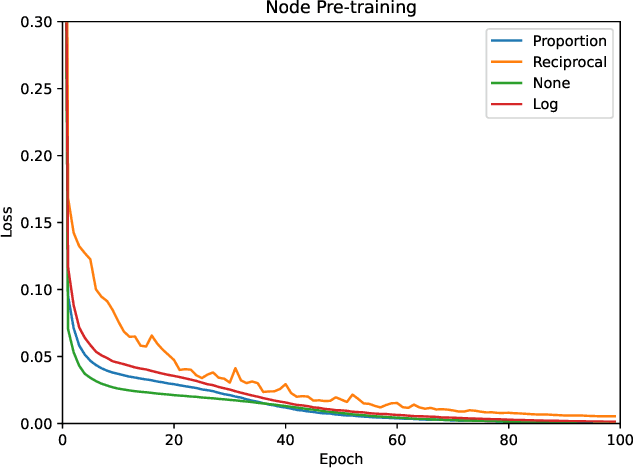
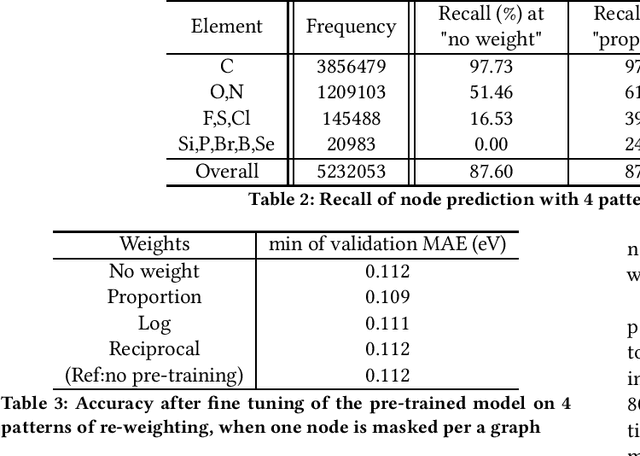
Revealing and analyzing the various properties of materials is an essential and critical issue in the development of materials, including batteries, semiconductors, catalysts, and pharmaceuticals. Traditionally, these properties have been determined through theoretical calculations and simulations. However, it is not practical to perform such calculations on every single candidate material. Recently, a combination method of the theoretical calculation and machine learning has emerged, that involves training machine learning models on a subset of theoretical calculation results to construct a surrogate model that can be applied to the remaining materials. On the other hand, a technique called pre-training is used to improve the accuracy of machine learning models. Pre-training involves training the model on pretext task, which is different from the target task, before training the model on the target task. This process aims to extract the input data features, stabilizing the learning process and improving its accuracy. However, in the case of molecular property prediction, there is a strong imbalance in the distribution of input data and features, which may lead to biased learning towards frequently occurring data during pre-training. In this study, we propose an effective pre-training method that addresses the imbalance in input data. We aim to improve the final accuracy by modifying the loss function of the existing representative pre-training method, node masking, to compensate the imbalance. We have investigated and assessed the impact of our proposed imbalance compensation on pre-training and the final prediction accuracy through experiments and evaluations using benchmark of molecular property prediction models.
Is Self-Supervised Pretraining Good for Extrapolation in Molecular Property Prediction?
Aug 16, 2023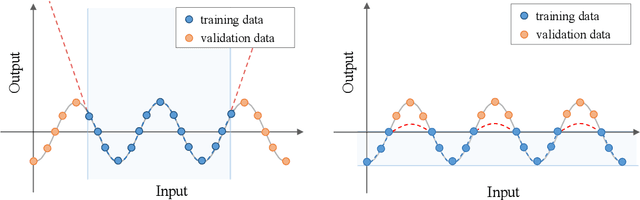
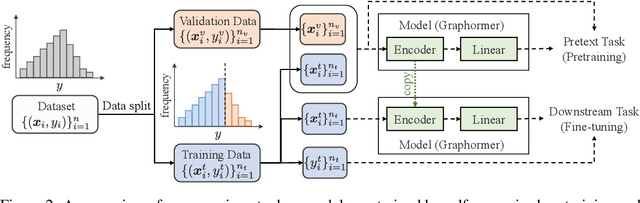

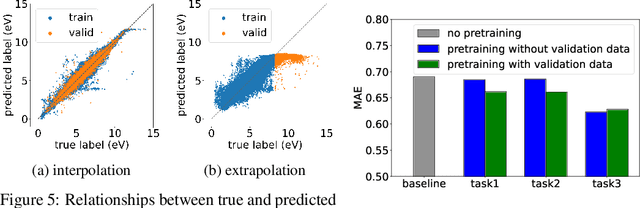
The prediction of material properties plays a crucial role in the development and discovery of materials in diverse applications, such as batteries, semiconductors, catalysts, and pharmaceuticals. Recently, there has been a growing interest in employing data-driven approaches by using machine learning technologies, in combination with conventional theoretical calculations. In material science, the prediction of unobserved values, commonly referred to as extrapolation, is particularly critical for property prediction as it enables researchers to gain insight into materials beyond the limits of available data. However, even with the recent advancements in powerful machine learning models, accurate extrapolation is still widely recognized as a significantly challenging problem. On the other hand, self-supervised pretraining is a machine learning technique where a model is first trained on unlabeled data using relatively simple pretext tasks before being trained on labeled data for target tasks. As self-supervised pretraining can effectively utilize material data without observed property values, it has the potential to improve the model's extrapolation ability. In this paper, we clarify how such self-supervised pretraining can enhance extrapolation performance.We propose an experimental framework for the demonstration and empirically reveal that while models were unable to accurately extrapolate absolute property values, self-supervised pretraining enables them to learn relative tendencies of unobserved property values and improve extrapolation performance.
Going Beyond Local: Global Graph-Enhanced Personalized News Recommendations
Jul 31, 2023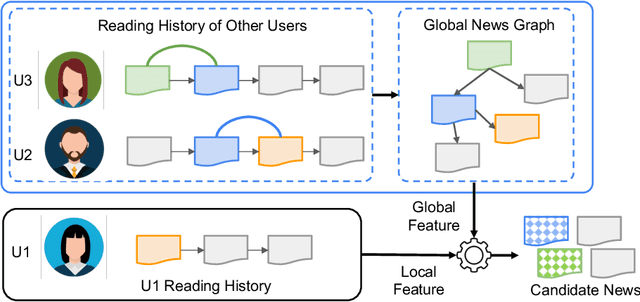


Precisely recommending candidate news articles to users has always been a core challenge for personalized news recommendation systems. Most recent works primarily focus on using advanced natural language processing techniques to extract semantic information from rich textual data, employing content-based methods derived from local historical news. However, this approach lacks a global perspective, failing to account for users' hidden motivations and behaviors beyond semantic information. To address this challenge, we propose a novel model called GLORY (Global-LOcal news Recommendation sYstem), which combines global representations learned from other users with local representations to enhance personalized recommendation systems. We accomplish this by constructing a Global-aware Historical News Encoder, which includes a global news graph and employs gated graph neural networks to enrich news representations, thereby fusing historical news representations by a historical news aggregator. Similarly, we extend this approach to a Global Candidate News Encoder, utilizing a global entity graph and a candidate news aggregator to enhance candidate news representation. Evaluation results on two public news datasets demonstrate that our method outperforms existing approaches. Furthermore, our model offers more diverse recommendations.
Exploring 360-Degree View of Customers for Lookalike Modeling
Apr 17, 2023

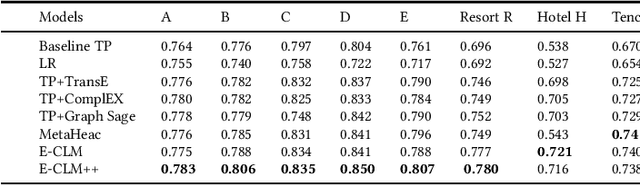
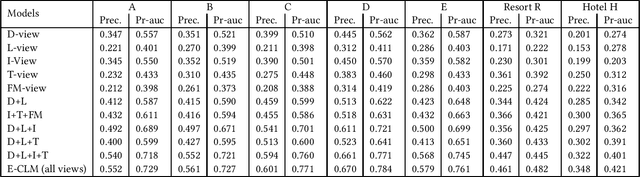
Lookalike models are based on the assumption that user similarity plays an important role towards product selling and enhancing the existing advertising campaigns from a very large user base. Challenges associated to these models reside on the heterogeneity of the user base and its sparsity. In this work, we propose a novel framework that unifies the customers different behaviors or features such as demographics, buying behaviors on different platforms, customer loyalty behaviors and build a lookalike model to improve customer targeting for Rakuten Group, Inc. Extensive experiments on real e-commerce and travel datasets demonstrate the effectiveness of our proposed lookalike model for user targeting task.
NNKGC: Improving Knowledge Graph Completion with Node Neighborhoods
Feb 13, 2023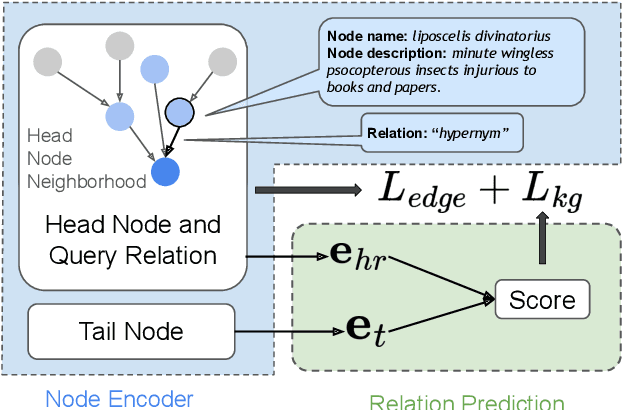

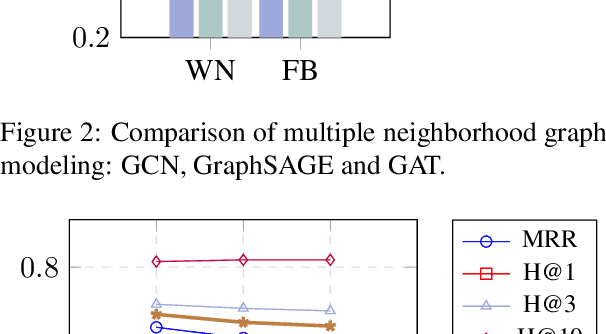
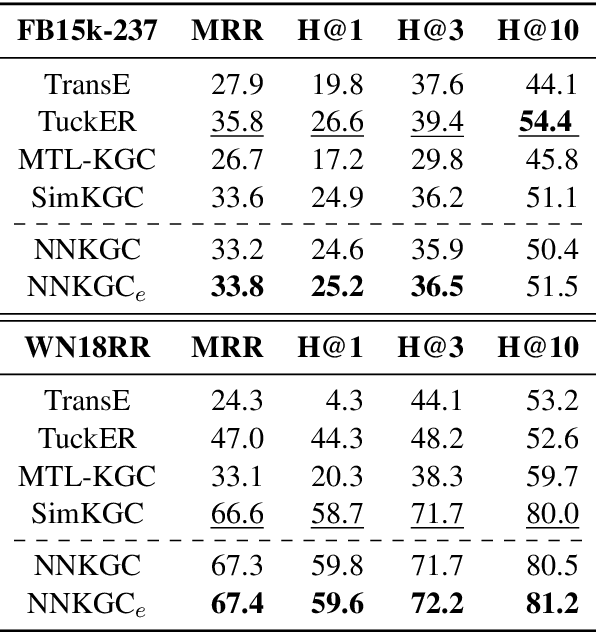
Knowledge graph completion (KGC) aims to discover missing relations of query entities. Current text-based models utilize the entity name and description to infer the tail entity given the head entity and a certain relation. Existing approaches also consider the neighborhood of the head entity. However, these methods tend to model the neighborhood using a flat structure and are only restricted to 1-hop neighbors. In this work, we propose a node neighborhood-enhanced framework for knowledge graph completion. It models the head entity neighborhood from multiple hops using graph neural networks to enrich the head node information. Moreover, we introduce an additional edge link prediction task to improve KGC. Evaluation on two public datasets shows that this framework is simple yet effective. The case study also shows that the model is able to predict explainable predictions.
Can Persistent Homology provide an efficient alternative for Evaluation of Knowledge Graph Completion Methods?
Jan 31, 2023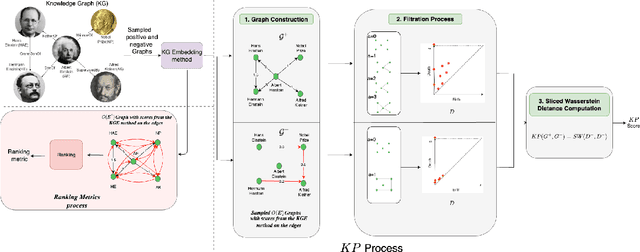


In this paper we present a novel method, $\textit{Knowledge Persistence}$ ($\mathcal{KP}$), for faster evaluation of Knowledge Graph (KG) completion approaches. Current ranking-based evaluation is quadratic in the size of the KG, leading to long evaluation times and consequently a high carbon footprint. $\mathcal{KP}$ addresses this by representing the topology of the KG completion methods through the lens of topological data analysis, concretely using persistent homology. The characteristics of persistent homology allow $\mathcal{KP}$ to evaluate the quality of the KG completion looking only at a fraction of the data. Experimental results on standard datasets show that the proposed metric is highly correlated with ranking metrics (Hits@N, MR, MRR). Performance evaluation shows that $\mathcal{KP}$ is computationally efficient: In some cases, the evaluation time (validation+test) of a KG completion method has been reduced from 18 hours (using Hits@10) to 27 seconds (using $\mathcal{KP}$), and on average (across methods & data) reduces the evaluation time (validation+test) by $\approx$ $\textbf{99.96}\%$.
MegaCRN: Meta-Graph Convolutional Recurrent Network for Spatio-Temporal Modeling
Dec 12, 2022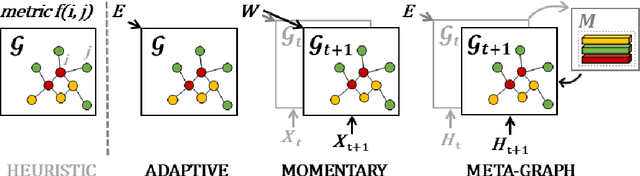

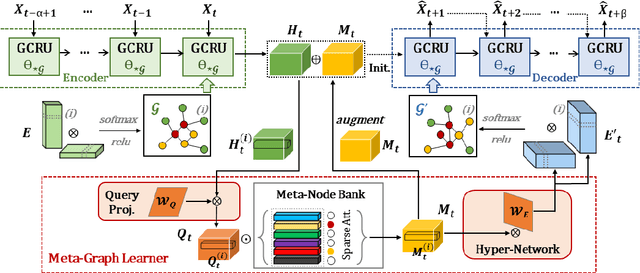

Spatio-temporal modeling as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the underlying heterogeneity and non-stationarity implied in the graph streams, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a large-scale spatio-temporal dataset that contains a variaty of non-stationary phenomena. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle locations and time slots with different patterns and be robustly adaptive to different anomalous situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Dec 08, 2022


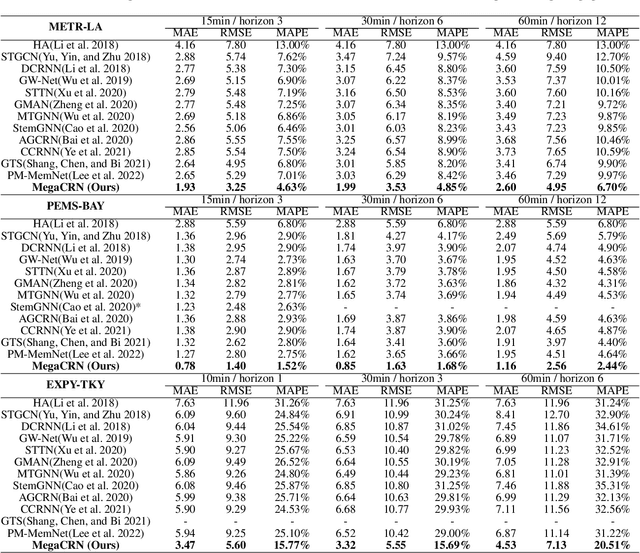
Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.