 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsabela Albuquerque
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024
While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Generative models improve fairness of medical classifiers under distribution shifts
Apr 18, 2023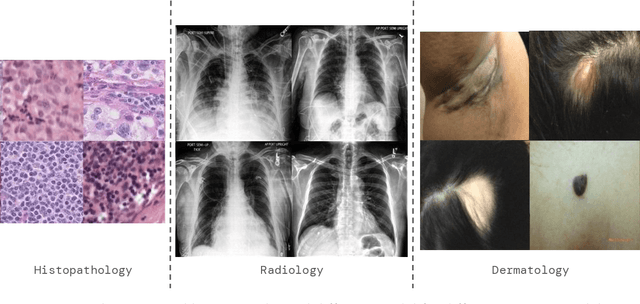
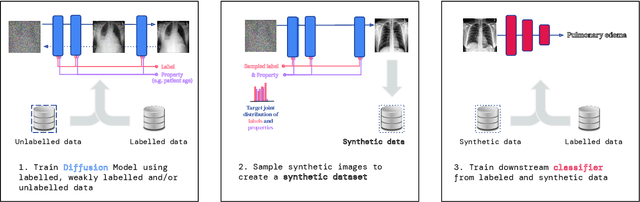
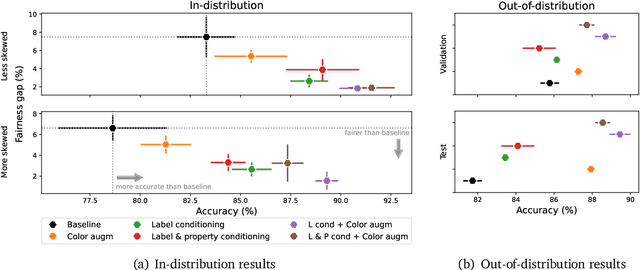
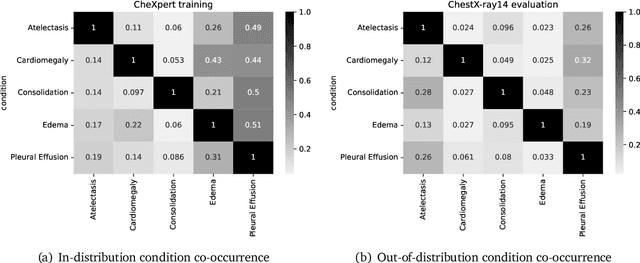
A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
Discovering Bugs in Vision Models using Off-the-shelf Image Generation and Captioning
Aug 18, 2022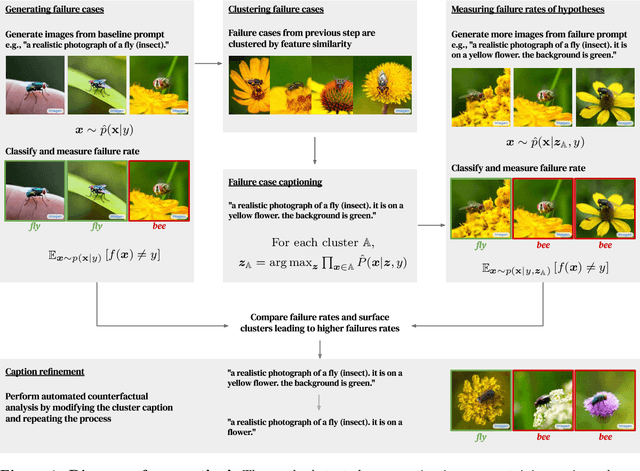



Automatically discovering failures in vision models under real-world settings remains an open challenge. This work demonstrates how off-the-shelf, large-scale, image-to-text and text-to-image models, trained on vast amounts of data, can be leveraged to automatically find such failures. In essence, a conditional text-to-image generative model is used to generate large amounts of synthetic, yet realistic, inputs given a ground-truth label. Misclassified inputs are clustered and a captioning model is used to describe each cluster. Each cluster's description is used in turn to generate more inputs and assess whether specific clusters induce more failures than expected. We use this pipeline to demonstrate that we can effectively interrogate classifiers trained on ImageNet to find specific failure cases and discover spurious correlations. We also show that we can scale the approach to generate adversarial datasets targeting specific classifier architectures. This work serves as a proof-of-concept demonstrating the utility of large-scale generative models to automatically discover bugs in vision models in an open-ended manner. We also describe a number of limitations and pitfalls related to this approach.
Improving out-of-distribution generalization via multi-task self-supervised pretraining
Mar 30, 2020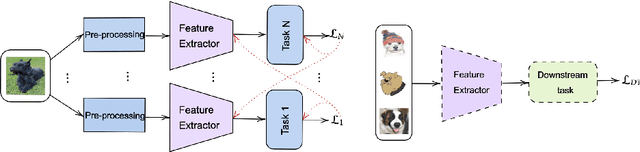


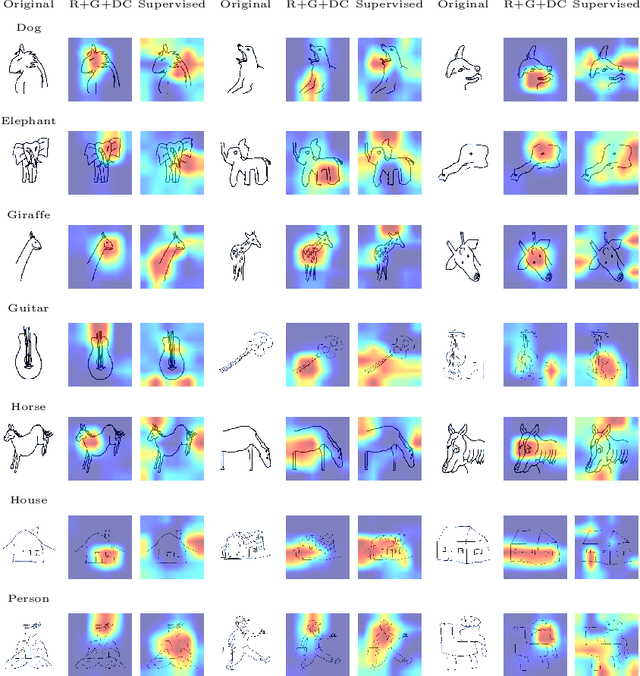
Self-supervised feature representations have been shown to be useful for supervised classification, few-shot learning, and adversarial robustness. We show that features obtained using self-supervised learning are comparable to, or better than, supervised learning for domain generalization in computer vision. We introduce a new self-supervised pretext task of predicting responses to Gabor filter banks and demonstrate that multi-task learning of compatible pretext tasks improves domain generalization performance as compared to training individual tasks alone. Features learnt through self-supervision obtain better generalization to unseen domains when compared to their supervised counterpart when there is a larger domain shift between training and test distributions and even show better localization ability for objects of interest. Self-supervised feature representations can also be combined with other domain generalization methods to further boost performance.
An end-to-end approach for the verification problem: learning the right distance
Feb 21, 2020



In this contribution, we augment the metric learning setting by introducing a parametric pseudo-distance, trained jointly with the encoder. Several interpretations are thus drawn for the learned distance-like model's output. We first show it approximates a likelihood ratio which can be used for hypothesis tests, and that it further induces a large divergence across the joint distributions of pairs of examples from the same and from different classes. Evaluation is performed under the verification setting consisting of determining whether sets of examples belong to the same class, even if such classes are novel and were never presented to the model during training. Empirical evaluation shows such method defines an end-to-end approach for the verification problem, able to attain better performance than simple scorers such as those based on cosine similarity and further outperforming widely used downstream classifiers. We further observe training is much simplified under the proposed approach compared to metric learning with actual distances, requiring no complex scheme to harvest pairs of examples.
Self-supervised representation learning from electroencephalography signals
Nov 13, 2019



The supervised learning paradigm is limited by the cost - and sometimes the impracticality - of data collection and labeling in multiple domains. Self-supervised learning, a paradigm which exploits the structure of unlabeled data to create learning problems that can be solved with standard supervised approaches, has shown great promise as a pretraining or feature learning approach in fields like computer vision and time series processing. In this work, we present self-supervision strategies that can be used to learn informative representations from multivariate time series. One successful approach relies on predicting whether time windows are sampled from the same temporal context or not. As demonstrated on a clinically relevant task (sleep scoring) and with two electroencephalography datasets, our approach outperforms a purely supervised approach in low data regimes, while capturing important physiological information without any access to labels.
Adversarial target-invariant representation learning for domain generalization
Nov 03, 2019

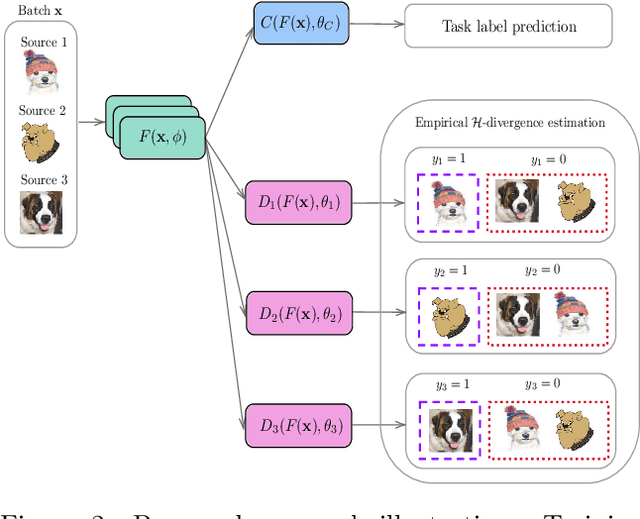

In many applications of machine learning, the training and test set data come from different distributions, or domains. A number of domain generalization strategies have been introduced with the goal of achieving good performance on out-of-distribution data. In this paper, we propose an adversarial approach to the problem. We propose a process that enforces pair-wise domain invariance while training a feature extractor over a diverse set of domains. We show that this process ensures invariance to any distribution that can be expressed as a mixture of the training domains. Following this insight, we then introduce an adversarial approach in which pair-wise divergences are estimated and minimized. Experiments on two domain generalization benchmarks for object recognition (i.e., PACS and VLCS) show that the proposed method yields higher average accuracy on the target domains in comparison to previously introduced adversarial strategies, as well as recently proposed methods based on learning invariant representations.
Cross-Subject Statistical Shift Estimation for Generalized Electroencephalography-based Mental Workload Assessment
Jun 20, 2019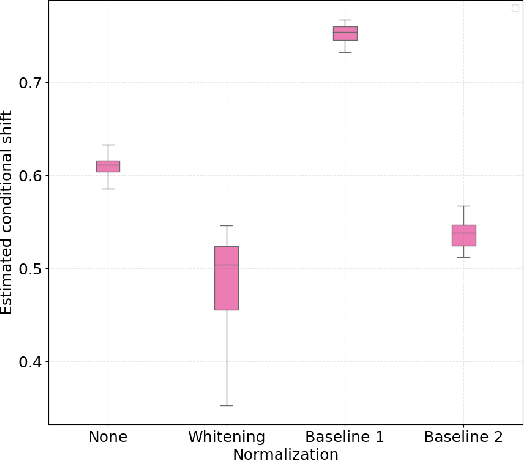
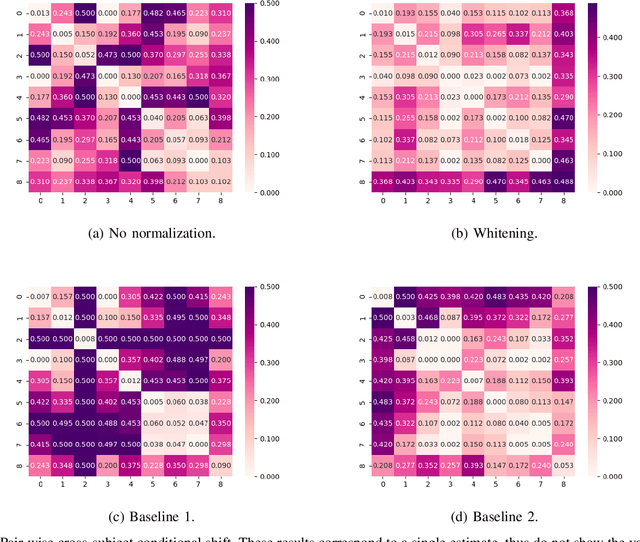
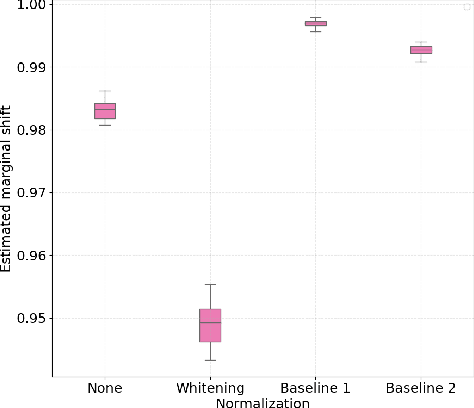
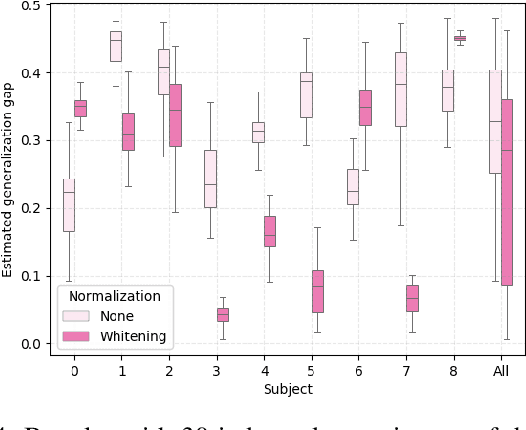
Assessment of mental workload in real world conditions is key to ensure the performance of workers executing tasks which demand sustained attention. Previous literature has employed electroencephalography (EEG) to this end. However, EEG correlates of mental workload vary across subjects and physical strain, thus making it difficult to devise models capable of simultaneously presenting reliable performance across users. The field of domain adaptation (DA) aims at developing methods that allow for generalization across different domains by learning domain-invariant representations. Such DA methods, however, rely on the so-called covariate shift assumption, which typically does not hold for EEG-based applications. As such, in this paper we propose a way to measure the statistical (marginal and conditional) shift observed on data obtained from different users and use this measure to quantitatively assess the effectiveness of different adaptation strategies. In particular, we use EEG data collected from individuals performing a mental task while running in a treadmill and explore the effects of different normalization strategies commonly used to mitigate cross-subject variability. We show the effects that different normalization schemes have on statistical shifts and their relationship with the accuracy of mental workload prediction as assessed on unseen participants at train time.
Multi-objective training of Generative Adversarial Networks with multiple discriminators
Jan 24, 2019


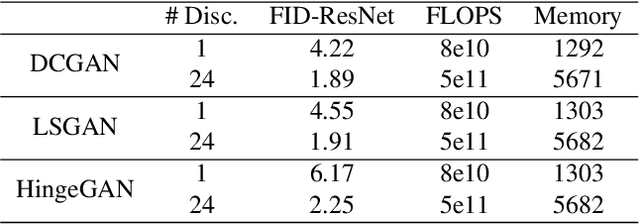
Recent literature has demonstrated promising results for training Generative Adversarial Networks by employing a set of discriminators, in contrast to the traditional game involving one generator against a single adversary. Such methods perform single-objective optimization on some simple consolidation of the losses, e.g. an arithmetic average. In this work, we revisit the multiple-discriminator setting by framing the simultaneous minimization of losses provided by different models as a multi-objective optimization problem. Specifically, we evaluate the performance of multiple gradient descent and the hypervolume maximization algorithm on a number of different datasets. Moreover, we argue that the previously proposed methods and hypervolume maximization can all be seen as variations of multiple gradient descent in which the update direction can be computed efficiently. Our results indicate that hypervolume maximization presents a better compromise between sample quality and computational cost than previous methods.
Learning to navigate image manifolds induced by generative adversarial networks for unsupervised video generation
Jan 23, 2019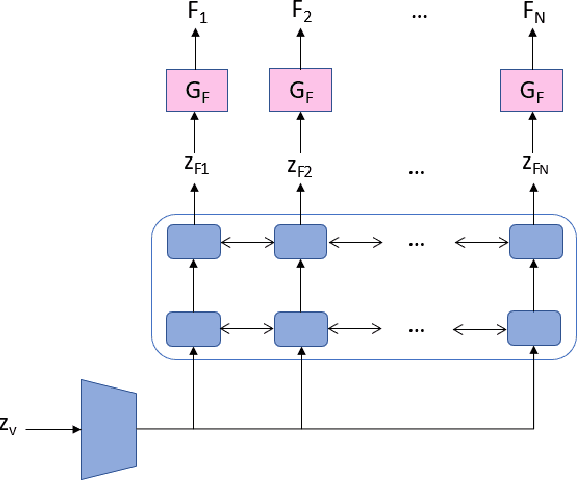
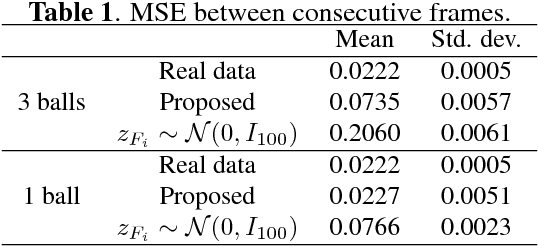


In this work, we introduce a two-step framework for generative modeling of temporal data. Specifically, the generative adversarial networks (GANs) setting is employed to generate synthetic scenes of moving objects. To do so, we propose a two-step training scheme within which: a generator of static frames is trained first. Afterwards, a recurrent model is trained with the goal of providing a sequence of inputs to the previously trained frames generator, thus yielding scenes which look natural. The adversarial setting is employed in both training steps. However, with the aim of avoiding known training instabilities in GANs, a multiple discriminator approach is used to train both models. Results in the studied video dataset indicate that, by employing such an approach, the recurrent part is able to learn how to coherently navigate the image manifold induced by the frames generator, thus yielding more natural-looking scenes.