 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyutaro Tanno
Towards Conversational Diagnostic AI
Jan 11, 2024
At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
Bad Students Make Great Teachers: Active Learning Accelerates Large-Scale Visual Understanding
Dec 12, 2023We propose a method for accelerating large-scale pre-training with online data selection policies. For the first time, we demonstrate that model-based data selection can reduce the total computation needed to reach the performance of models trained with uniform sampling. The key insight which enables this "compute-positive" regime is that small models provide good proxies for the loss of much larger models, such that computation spent on scoring data can be drastically scaled down but still significantly accelerate training of the learner.. These data selection policies also strongly generalize across datasets and tasks, opening an avenue for further amortizing the overhead of data scoring by re-using off-the-shelf models and training sequences. Our methods, ClassAct and ActiveCLIP, require 46% and 51% fewer training updates and up to 25% less total computation when training visual classifiers on JFT and multimodal models on ALIGN, respectively. Finally, our paradigm seamlessly applies to the curation of large-scale image-text datasets, yielding a new state-of-the-art in several multimodal transfer tasks and pre-training regimes.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.
An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concept Prompt Learning
Oct 18, 2023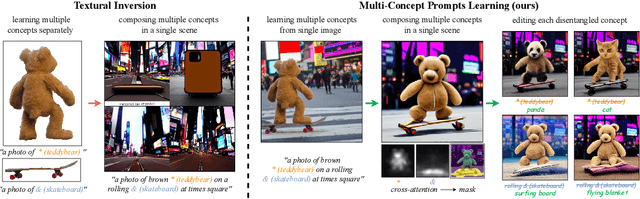
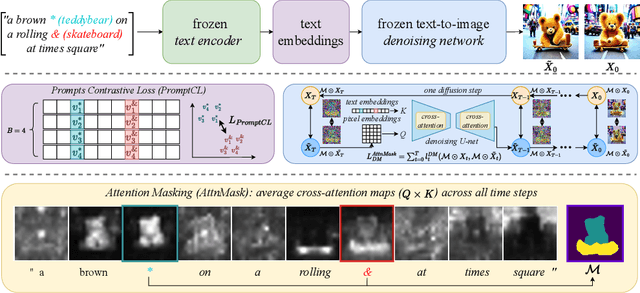


Textural Inversion, a prompt learning method, learns a singular embedding for a new "word" to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by our empirical tests. To address this challenge, we introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new "words" are simultaneously learned from a single sentence-image pair. To enhance the accuracy of word-concept correlation, we propose three regularisation techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new "words" with known words. We evaluate via image generation, editing, and attention visualisation with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, we introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
Towards Generalist Biomedical AI
Jul 26, 2023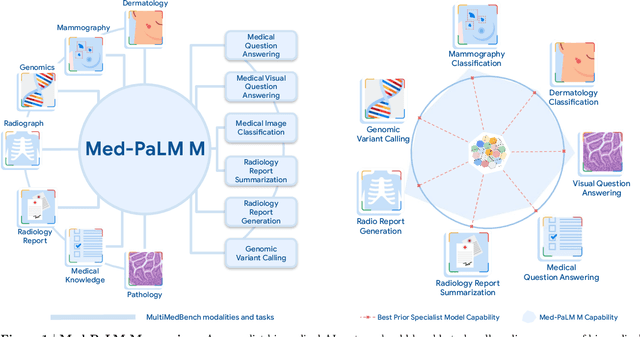
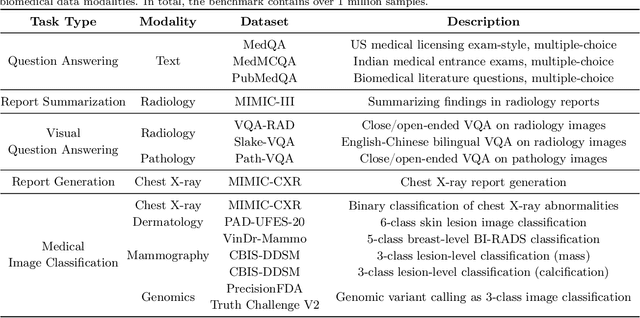

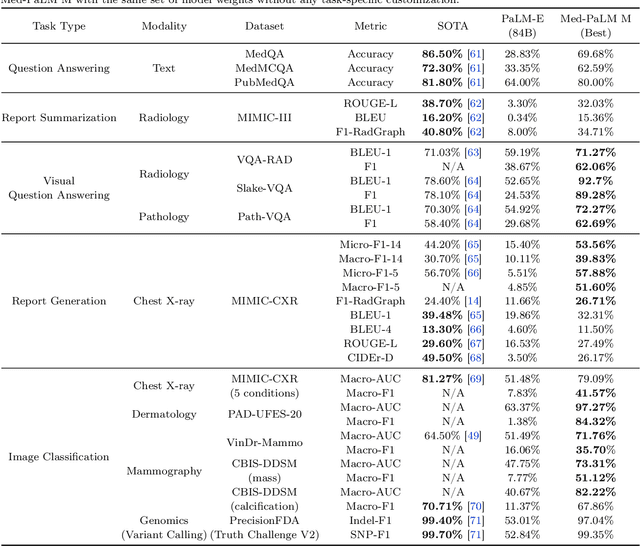
Medicine is inherently multimodal, with rich data modalities spanning text, imaging, genomics, and more. Generalist biomedical artificial intelligence (AI) systems that flexibly encode, integrate, and interpret this data at scale can potentially enable impactful applications ranging from scientific discovery to care delivery. To enable the development of these models, we first curate MultiMedBench, a new multimodal biomedical benchmark. MultiMedBench encompasses 14 diverse tasks such as medical question answering, mammography and dermatology image interpretation, radiology report generation and summarization, and genomic variant calling. We then introduce Med-PaLM Multimodal (Med-PaLM M), our proof of concept for a generalist biomedical AI system. Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data including clinical language, imaging, and genomics with the same set of model weights. Med-PaLM M reaches performance competitive with or exceeding the state of the art on all MultiMedBench tasks, often surpassing specialist models by a wide margin. We also report examples of zero-shot generalization to novel medical concepts and tasks, positive transfer learning across tasks, and emergent zero-shot medical reasoning. To further probe the capabilities and limitations of Med-PaLM M, we conduct a radiologist evaluation of model-generated (and human) chest X-ray reports and observe encouraging performance across model scales. In a side-by-side ranking on 246 retrospective chest X-rays, clinicians express a pairwise preference for Med-PaLM M reports over those produced by radiologists in up to 40.50% of cases, suggesting potential clinical utility. While considerable work is needed to validate these models in real-world use cases, our results represent a milestone towards the development of generalist biomedical AI systems.
Low-field magnetic resonance image enhancement via stochastic image quality transfer
Apr 26, 2023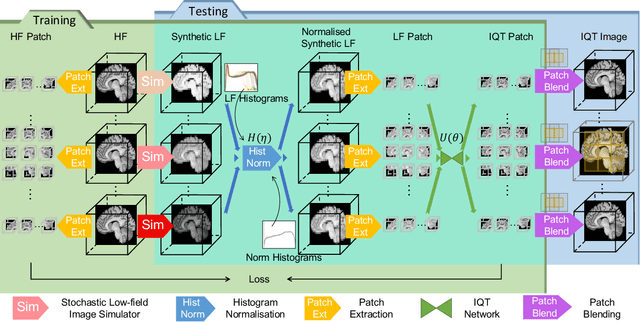
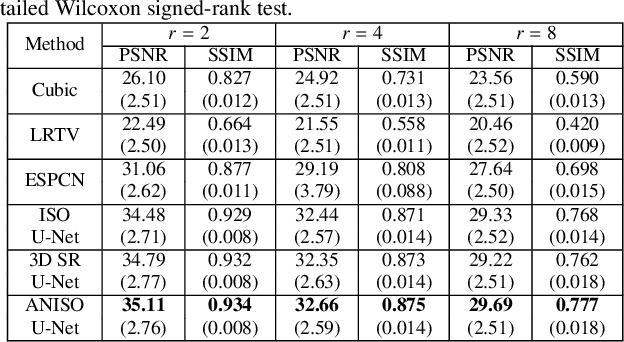
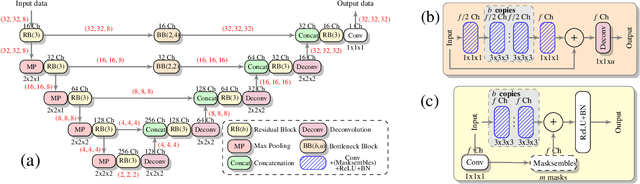
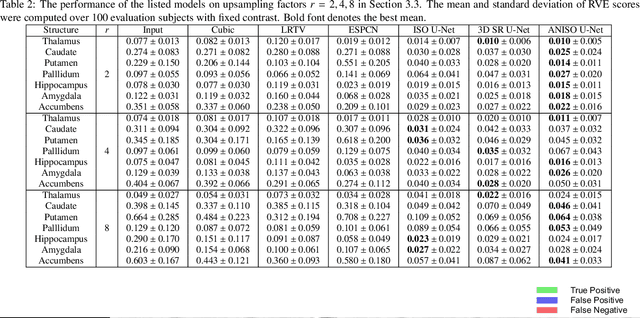
Low-field (<1T) magnetic resonance imaging (MRI) scanners remain in widespread use in low- and middle-income countries (LMICs) and are commonly used for some applications in higher income countries e.g. for small child patients with obesity, claustrophobia, implants, or tattoos. However, low-field MR images commonly have lower resolution and poorer contrast than images from high field (1.5T, 3T, and above). Here, we present Image Quality Transfer (IQT) to enhance low-field structural MRI by estimating from a low-field image the image we would have obtained from the same subject at high field. Our approach uses (i) a stochastic low-field image simulator as the forward model to capture uncertainty and variation in the contrast of low-field images corresponding to a particular high-field image, and (ii) an anisotropic U-Net variant specifically designed for the IQT inverse problem. We evaluate the proposed algorithm both in simulation and using multi-contrast (T1-weighted, T2-weighted, and fluid attenuated inversion recovery (FLAIR)) clinical low-field MRI data from an LMIC hospital. We show the efficacy of IQT in improving contrast and resolution of low-field MR images. We demonstrate that IQT-enhanced images have potential for enhancing visualisation of anatomical structures and pathological lesions of clinical relevance from the perspective of radiologists. IQT is proved to have capability of boosting the diagnostic value of low-field MRI, especially in low-resource settings.
Generative models improve fairness of medical classifiers under distribution shifts
Apr 18, 2023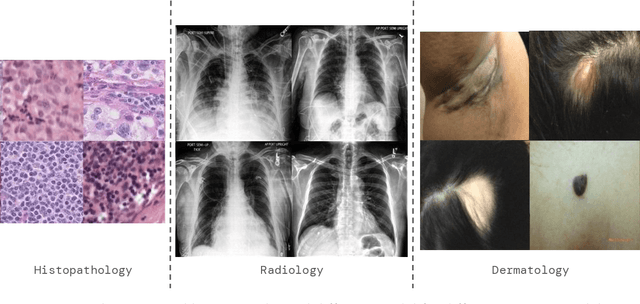
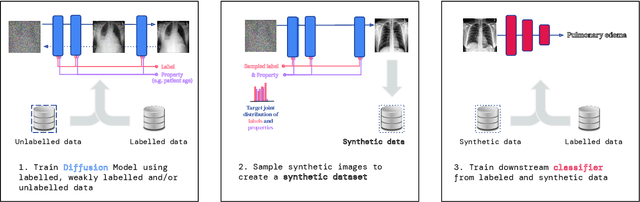
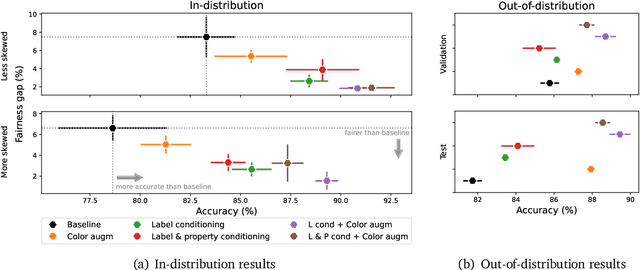
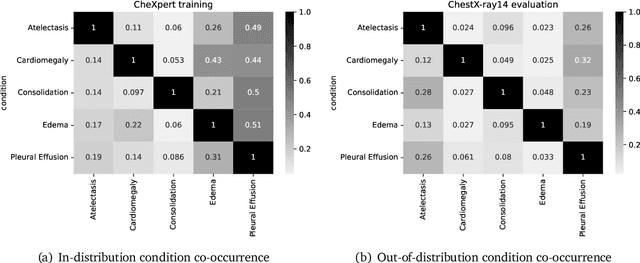
A ubiquitous challenge in machine learning is the problem of domain generalisation. This can exacerbate bias against groups or labels that are underrepresented in the datasets used for model development. Model bias can lead to unintended harms, especially in safety-critical applications like healthcare. Furthermore, the challenge is compounded by the difficulty of obtaining labelled data due to high cost or lack of readily available domain expertise. In our work, we show that learning realistic augmentations automatically from data is possible in a label-efficient manner using generative models. In particular, we leverage the higher abundance of unlabelled data to capture the underlying data distribution of different conditions and subgroups for an imaging modality. By conditioning generative models on appropriate labels, we can steer the distribution of synthetic examples according to specific requirements. We demonstrate that these learned augmentations can surpass heuristic ones by making models more robust and statistically fair in- and out-of-distribution. To evaluate the generality of our approach, we study 3 distinct medical imaging contexts of varying difficulty: (i) histopathology images from a publicly available generalisation benchmark, (ii) chest X-rays from publicly available clinical datasets, and (iii) dermatology images characterised by complex shifts and imaging conditions. Complementing real training samples with synthetic ones improves the robustness of models in all three medical tasks and increases fairness by improving the accuracy of diagnosis within underrepresented groups. This approach leads to stark improvements OOD across modalities: 7.7% prediction accuracy improvement in histopathology, 5.2% in chest radiology with 44.6% lower fairness gap and a striking 63.5% improvement in high-risk sensitivity for dermatology with a 7.5x reduction in fairness gap.
Repairing Neural Networks by Leaving the Right Past Behind
Jul 11, 2022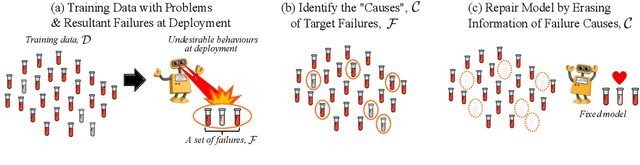
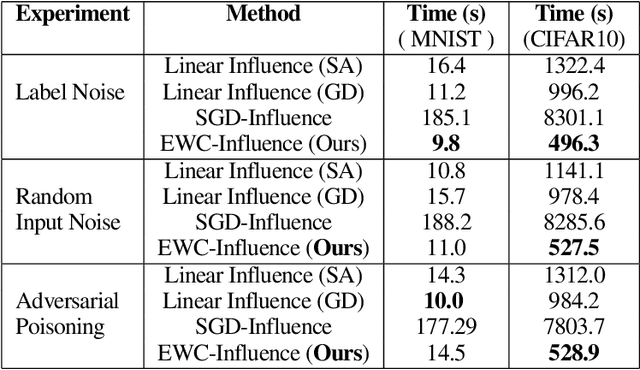
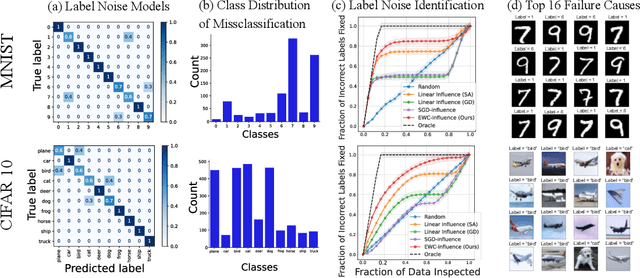
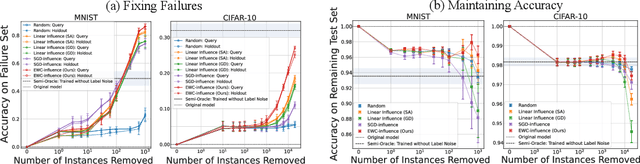
Prediction failures of machine learning models often arise from deficiencies in training data, such as incorrect labels, outliers, and selection biases. However, such data points that are responsible for a given failure mode are generally not known a priori, let alone a mechanism for repairing the failure. This work draws on the Bayesian view of continual learning, and develops a generic framework for both, identifying training examples that have given rise to the target failure, and fixing the model through erasing information about them. This framework naturally allows leveraging recent advances in continual learning to this new problem of model repairment, while subsuming the existing works on influence functions and data deletion as specific instances. Experimentally, the proposed approach outperforms the baselines for both identification of detrimental training data and fixing model failures in a generalisable manner.
A Principled Approach to Failure Analysis and Model Repairment: Demonstration in Medical Imaging
Sep 25, 2021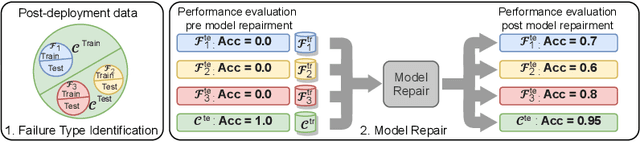
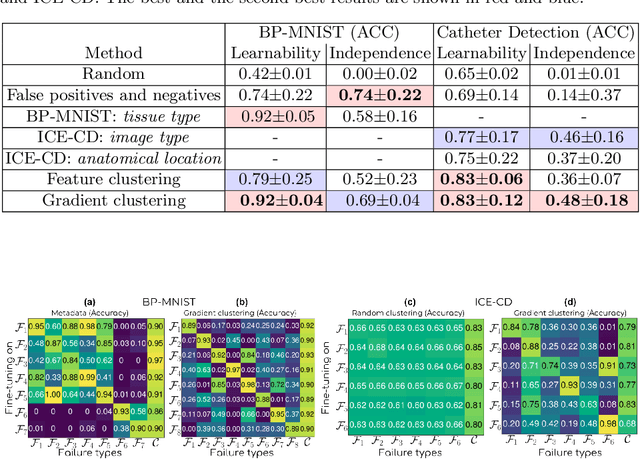
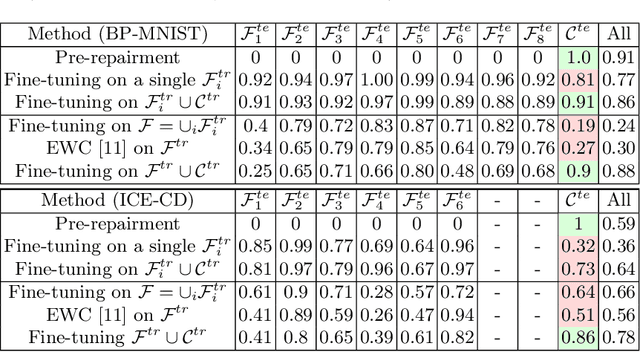
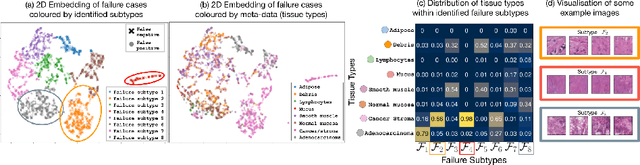
Machine learning models commonly exhibit unexpected failures post-deployment due to either data shifts or uncommon situations in the training environment. Domain experts typically go through the tedious process of inspecting the failure cases manually, identifying failure modes and then attempting to fix the model. In this work, we aim to standardise and bring principles to this process through answering two critical questions: (i) how do we know that we have identified meaningful and distinct failure types?; (ii) how can we validate that a model has, indeed, been repaired? We suggest that the quality of the identified failure types can be validated through measuring the intra- and inter-type generalisation after fine-tuning and introduce metrics to compare different subtyping methods. Furthermore, we argue that a model can be considered repaired if it achieves high accuracy on the failure types while retaining performance on the previously correct data. We combine these two ideas into a principled framework for evaluating the quality of both the identified failure subtypes and model repairment. We evaluate its utility on a classification and an object detection tasks. Our code is available at https://github.com/Rokken-lab6/Failure-Analysis-and-Model-Repairment