 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Jin
Tackling Structural Hallucination in Image Translation with Local Diffusion
Apr 13, 2024
Recent developments in diffusion models have advanced conditioned image generation, yet they struggle with reconstructing out-of-distribution (OOD) images, such as unseen tumors in medical images, causing ``image hallucination'' and risking misdiagnosis. We hypothesize such hallucinations result from local OOD regions in the conditional images. We verify that partitioning the OOD region and conducting separate image generations alleviates hallucinations in several applications. From this, we propose a training-free diffusion framework that reduces hallucination with multiple Local Diffusion processes. Our approach involves OOD estimation followed by two modules: a ``branching'' module generates locally both within and outside OOD regions, and a ``fusion'' module integrates these predictions into one. Our evaluation shows our method mitigates hallucination over baseline models quantitatively and qualitatively, reducing misdiagnosis by 40% and 25% in the real-world medical and natural image datasets, respectively. It also demonstrates compatibility with various pre-trained diffusion models.
An Image is Worth Multiple Words: Learning Object Level Concepts using Multi-Concept Prompt Learning
Oct 18, 2023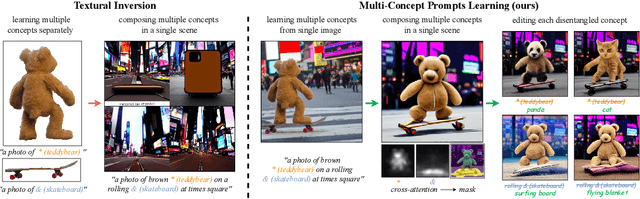
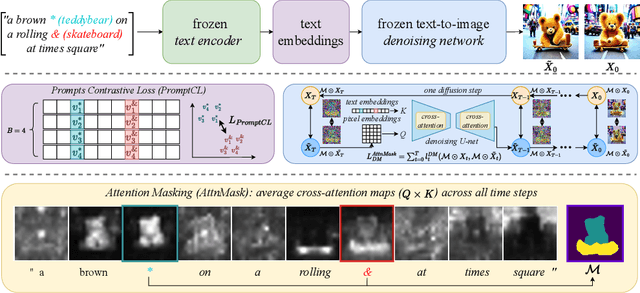


Textural Inversion, a prompt learning method, learns a singular embedding for a new "word" to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying and integrating multiple object-level concepts within one scene poses significant challenges even when embeddings for individual concepts are attainable. This is further confirmed by our empirical tests. To address this challenge, we introduce a framework for Multi-Concept Prompt Learning (MCPL), where multiple new "words" are simultaneously learned from a single sentence-image pair. To enhance the accuracy of word-concept correlation, we propose three regularisation techniques: Attention Masking (AttnMask) to concentrate learning on relevant areas; Prompts Contrastive Loss (PromptCL) to separate the embeddings of different concepts; and Bind adjective (Bind adj.) to associate new "words" with known words. We evaluate via image generation, editing, and attention visualisation with diverse images. Extensive quantitative comparisons demonstrate that our method can learn more semantically disentangled concepts with enhanced word-concept correlation. Additionally, we introduce a novel dataset and evaluation protocol tailored for this new task of learning object-level concepts.
CAMIL: Context-Aware Multiple Instance Learning for Whole Slide Image Classification
May 09, 2023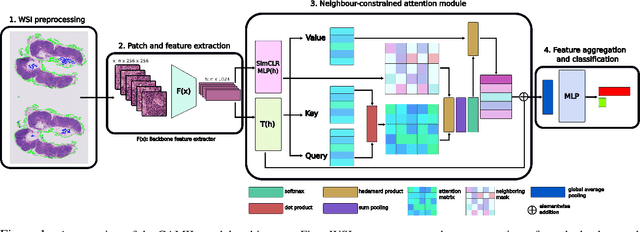

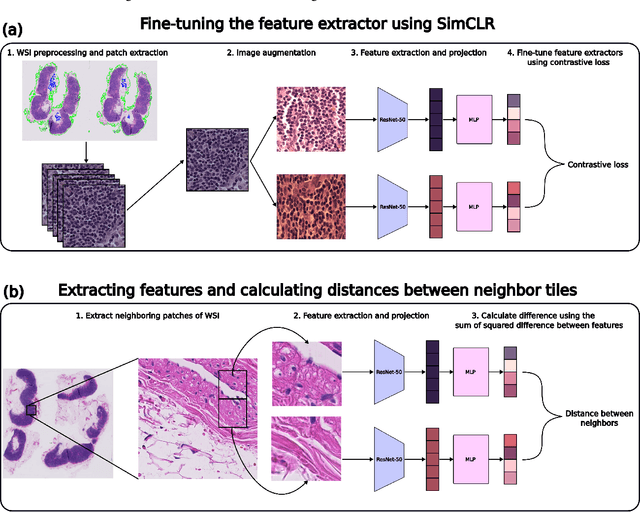

Cancer diagnoses typically involve human pathologists examining whole slide images (WSIs) of tissue section biopsies to identify tumor cells and their subtypes. However, artificial intelligence (AI)-based models, particularly weakly supervised approaches, have recently emerged as viable alternatives. Weakly supervised approaches often use image subsections or tiles as input, with the overall classification of the WSI based on attention scores assigned to each tile. However, this method overlooks the potential for false positives/negatives because tumors can be heterogeneous, with cancer and normal cells growing in patterns larger than a single tile. Such errors at the tile level could lead to misclassification at the tumor level. To address this limitation, we developed a novel deep learning pooling operator called CHARM (Contrastive Histopathology Attention Resolved Models). CHARM leverages the dependencies among single tiles within a WSI and imposes contextual constraints as prior knowledge to multiple instance learning models. We tested CHARM on the subtyping of non-small cell lung cancer (NSLC) and lymph node (LN) metastasis, and the results demonstrated its superiority over other state-of-the-art weakly supervised classification algorithms. Furthermore, CHARM facilitates interpretability by visualizing regions of attention.
Expectation Maximization Pseudo Labelling for Segmentation with Limited Annotations
May 02, 2023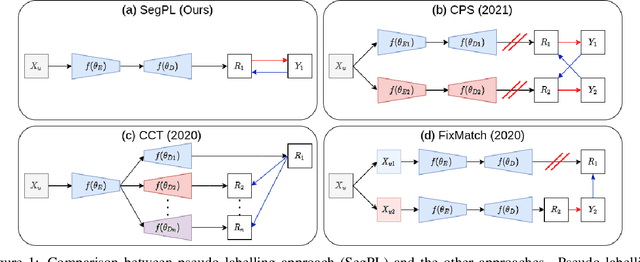
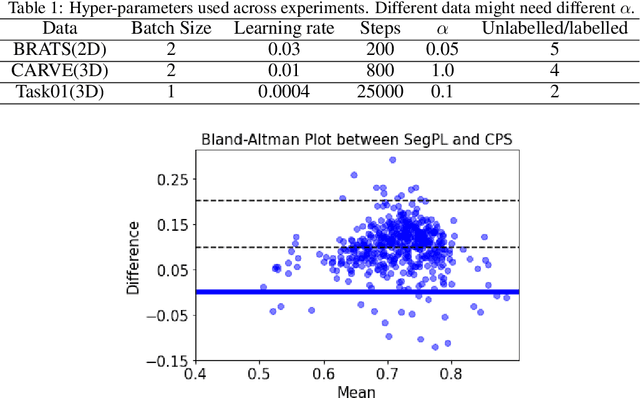
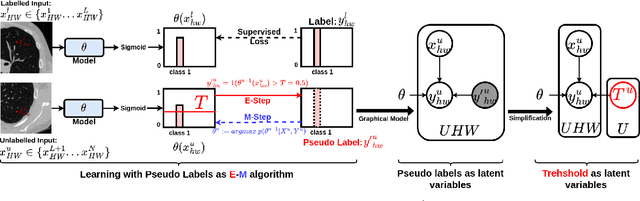
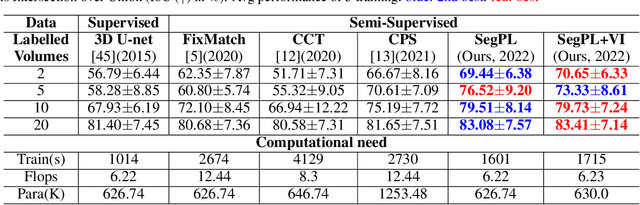
We study pseudo labelling and its generalisation for semi-supervised segmentation of medical images. Pseudo labelling has achieved great empirical successes in semi-supervised learning, by utilising raw inferences on unlabelled data as pseudo labels for self-training. In our paper, we build a connection between pseudo labelling and the Expectation Maximization algorithm which partially explains its empirical successes. We thereby realise that the original pseudo labelling is an empirical estimation of its underlying full formulation. Following this insight, we demonstrate the full generalisation of pseudo labels under Bayes' principle, called Bayesian Pseudo Labels. We then provide a variational approach to learn to approximate Bayesian Pseudo Labels, by learning a threshold to select good quality pseudo labels. In the rest of the paper, we demonstrate the applications of Pseudo Labelling and its generalisation Bayesian Psuedo Labelling in semi-supervised segmentation of medical images on: 1) 3D binary segmentation of lung vessels from CT volumes; 2) 2D multi class segmentation of brain tumours from MRI volumes; 3) 3D binary segmentation of brain tumours from MRI volumes. We also show that pseudo labels can enhance the robustness of the learnt representations.
Bayesian Pseudo Labels: Expectation Maximization for Robust and Efficient Semi-Supervised Segmentation
Aug 08, 2022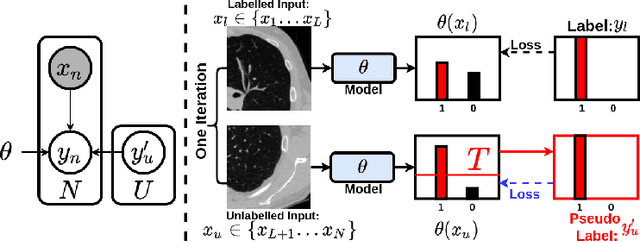
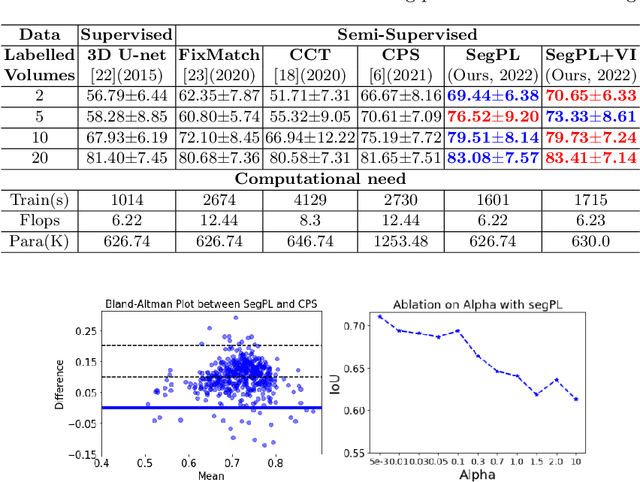
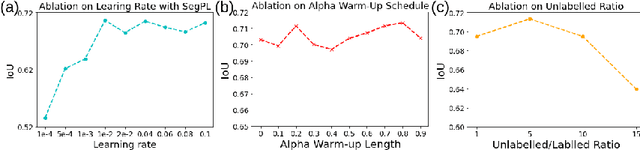
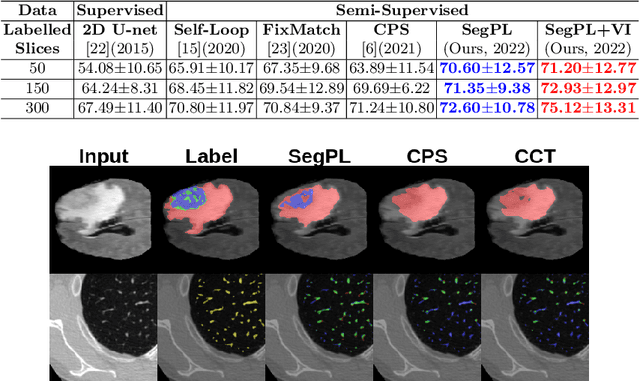
This paper concerns pseudo labelling in segmentation. Our contribution is fourfold. Firstly, we present a new formulation of pseudo-labelling as an Expectation-Maximization (EM) algorithm for clear statistical interpretation. Secondly, we propose a semi-supervised medical image segmentation method purely based on the original pseudo labelling, namely SegPL. We demonstrate SegPL is a competitive approach against state-of-the-art consistency regularisation based methods on semi-supervised segmentation on a 2D multi-class MRI brain tumour segmentation task and a 3D binary CT lung vessel segmentation task. The simplicity of SegPL allows less computational cost comparing to prior methods. Thirdly, we demonstrate that the effectiveness of SegPL may originate from its robustness against out-of-distribution noises and adversarial attacks. Lastly, under the EM framework, we introduce a probabilistic generalisation of SegPL via variational inference, which learns a dynamic threshold for pseudo labelling during the training. We show that SegPL with variational inference can perform uncertainty estimation on par with the gold-standard method Deep Ensemble.
Learning Morphological Feature Perturbations for Calibrated Semi-Supervised Segmentation
Apr 01, 2022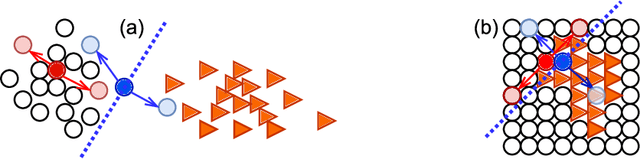
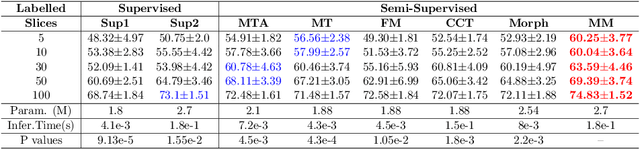
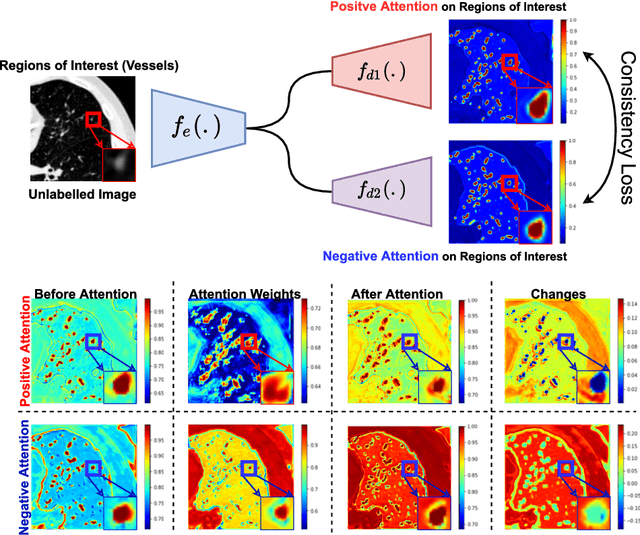

We propose MisMatch, a novel consistency-driven semi-supervised segmentation framework which produces predictions that are invariant to learnt feature perturbations. MisMatch consists of an encoder and a two-head decoders. One decoder learns positive attention to the foreground regions of interest (RoI) on unlabelled images thereby generating dilated features. The other decoder learns negative attention to the foreground on the same unlabelled images thereby generating eroded features. We then apply a consistency regularisation on the paired predictions. MisMatch outperforms state-of-the-art semi-supervised methods on a CT-based pulmonary vessel segmentation task and a MRI-based brain tumour segmentation task. In addition, we show that the effectiveness of MisMatch comes from better model calibration than its supervised learning counterpart.
MisMatch: Learning to Change Predictive Confidences with Attention for Consistency-Based, Semi-Supervised Medical Image Segmentation
Oct 23, 2021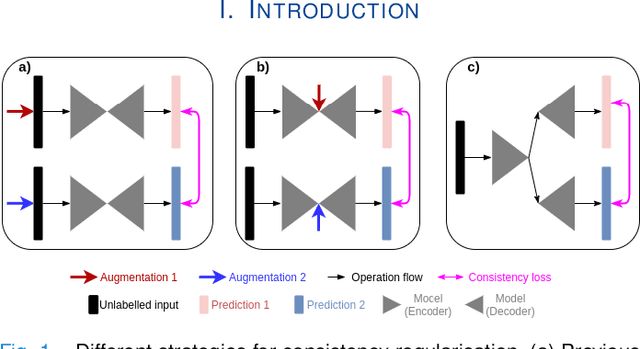
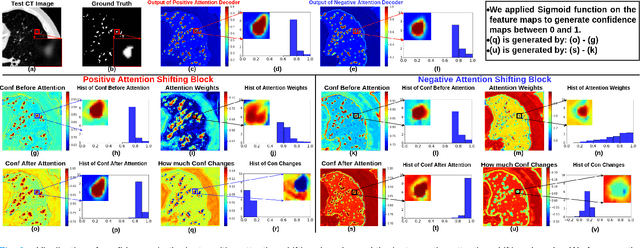
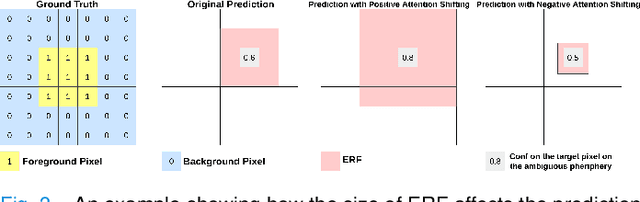
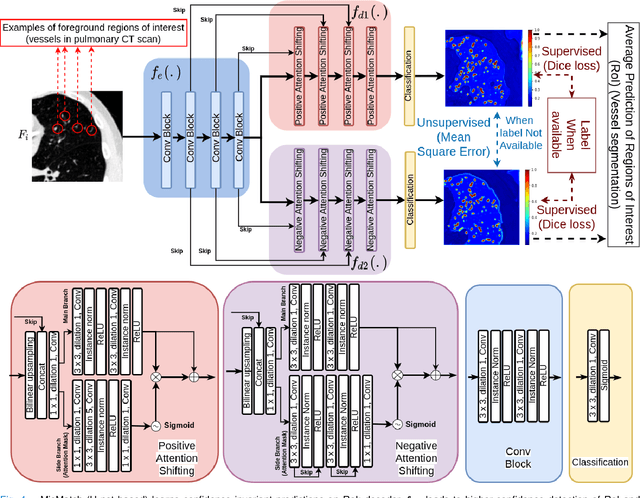
The lack of labels is one of the fundamental constraints in deep learning based methods for image classification and segmentation, especially in applications such as medical imaging. Semi-supervised learning (SSL) is a promising method to address the challenge of labels carcity. The state-of-the-art SSL methods utilise consistency regularisation to learn unlabelled predictions which are invariant to perturbations on the prediction confidence. However, such SSL approaches rely on hand-crafted augmentation techniques which could be sub-optimal. In this paper, we propose MisMatch, a novel consistency based semi-supervised segmentation method. MisMatch automatically learns to produce paired predictions with increasedand decreased confidences. MisMatch consists of an encoder and two decoders. One decoder learns positive attention for regions of interest (RoI) on unlabelled data thereby generating higher confidence predictions of RoI. The other decoder learns negative attention for RoI on the same unlabelled data thereby generating lower confidence predictions. We then apply a consistency regularisation between the paired predictions of the decoders. For evaluation, we first perform extensive cross-validation on a CT-based pulmonary vessel segmentation task and show that MisMatch statistically outperforms state-of-the-art semi-supervised methods when only 6.25% of the total labels are used. Furthermore MisMatch performance using 6.25% ofthe total labels is comparable to state-of-the-art methodsthat utilise all available labels. In a second experiment, MisMatch outperforms state-of-the-art methods on an MRI-based brain tumour segmentation task.
Learning to Downsample for Segmentation of Ultra-High Resolution Images
Sep 22, 2021
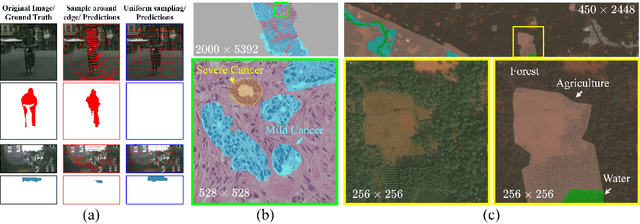


Segmentation of ultra-high resolution images with deep learning is challenging because of their enormous size, often millions or even billions of pixels. Typical solutions drastically downsample the image uniformly to meet memory constraints, implicitly assuming all pixels equally important by sampling at the same density at all spatial locations. However this assumption is not true and compromises the performance of deep learning techniques that have proved powerful on standard-sized images. For example with uniform downsampling, see green boxed region in Fig.1, the rider and bike do not have enough corresponding samples while the trees and buildings are oversampled, and lead to a negative effect on the segmentation prediction from the low-resolution downsampled image. In this work we show that learning the spatially varying downsampling strategy jointly with segmentation offers advantages in segmenting large images with limited computational budget. Fig.1 shows that our method adapts the sampling density over different locations so that more samples are collected from the small important regions and less from the others, which in turn leads to better segmentation accuracy. We show on two public and one local high-resolution datasets that our method consistently learns sampling locations preserving more information and boosting segmentation accuracy over baseline methods.
Bidirectional LSTM-CRF Attention-based Model for Chinese Word Segmentation
May 20, 2021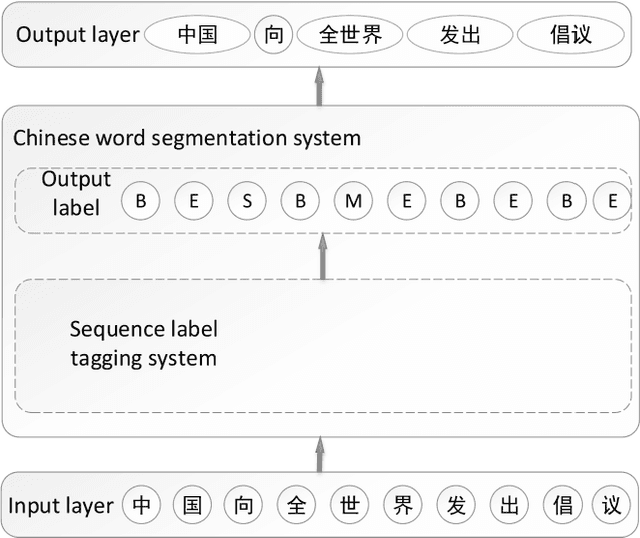
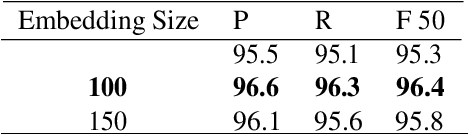

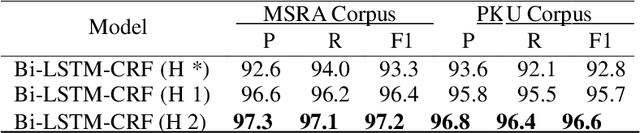
Chinese word segmentation (CWS) is the basic of Chinese natural language processing (NLP). The quality of word segmentation will directly affect the rest of NLP tasks. Recently, with the artificial intelligence tide rising again, Long Short-Term Memory (LSTM) neural network, as one of easily modeling in sequence, has been widely utilized in various kinds of NLP tasks, and functions well. Attention mechanism is an ingenious method to solve the memory compression problem on LSTM. Furthermore, inspired by the powerful abilities of bidirectional LSTM models for modeling sequence and CRF model for decoding, we propose a Bidirectional LSTM-CRF Attention-based Model in this paper. Experiments on PKU and MSRA benchmark datasets show that our model performs better than the baseline methods modeling by other neural networks.
Disentangling Human Error from the Ground Truth in Segmentation of Medical Images
Aug 06, 2020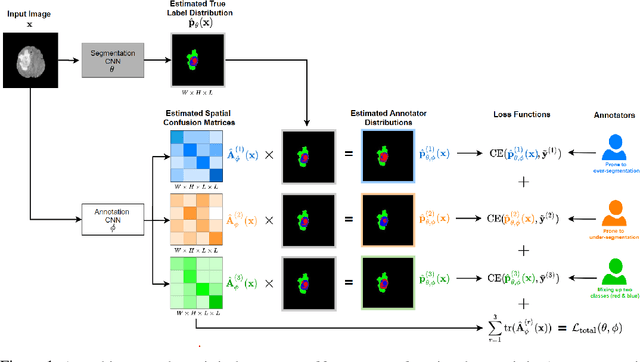
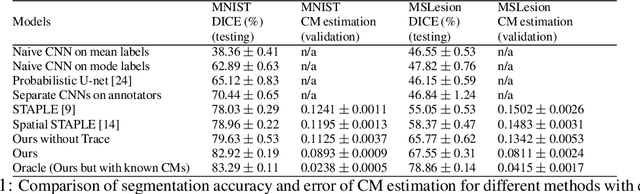


Recent years have seen increasing use of supervised learning methods for segmentation tasks. However, the predictive performance of these algorithms depends on the quality of labels. This problem is particularly pertinent in the medical image domain, where both the annotation cost and inter-observer variability are high. In a typical label acquisition process, different human experts provide their estimates of the 'true' segmentation labels under the influence of their own biases and competence levels. Treating these noisy labels blindly as the ground truth limits the performance that automatic segmentation algorithms can achieve. In this work, we present a method for jointly learning, from purely noisy observations alone, the reliability of individual annotators and the true segmentation label distributions, using two coupled CNNs. The separation of the two is achieved by encouraging the estimated annotators to be maximally unreliable while achieving high fidelity with the noisy training data. We first define a toy segmentation dataset based on MNIST and study the properties of the proposed algorithm. We then demonstrate the utility of the method on three public medical imaging segmentation datasets with simulated (when necessary) and real diverse annotations: 1) MSLSC (multiple-sclerosis lesions); 2) BraTS (brain tumours); 3) LIDC-IDRI (lung abnormalities). In all cases, our method outperforms competing methods and relevant baselines particularly in cases where the number of annotations is small and the amount of disagreement is large. The experiments also show strong ability to capture the complex spatial characteristics of annotators' mistakes.