 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJacob Levy
Active Inverse Learning in Stackelberg Trajectory Games
Aug 15, 2023
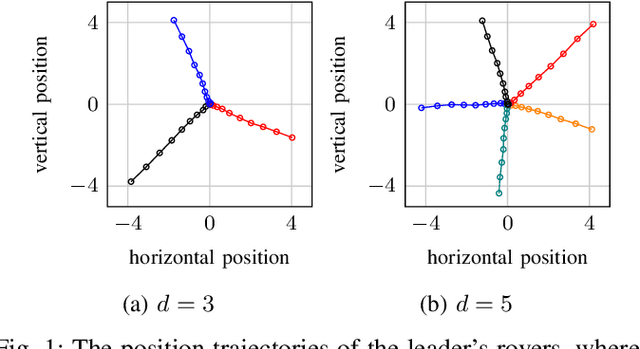

Game-theoretic inverse learning is the problem of inferring the players' objectives from their actions. We formulate an inverse learning problem in a Stackelberg game between a leader and a follower, where each player's action is the trajectory of a dynamical system. We propose an active inverse learning method for the leader to infer which hypothesis among a finite set of candidates describes the follower's objective function. Instead of using passively observed trajectories like existing methods, the proposed method actively maximizes the differences in the follower's trajectories under different hypotheses to accelerate the leader's inference. We demonstrate the proposed method in a receding-horizon repeated trajectory game. Compared with uniformly random inputs, the leader inputs provided by the proposed method accelerate the convergence of the probability of different hypotheses conditioned on the follower's trajectory by orders of magnitude.
Feedback is All You Need: Real-World Reinforcement Learning with Approximate Physics-Based Models
Jul 16, 2023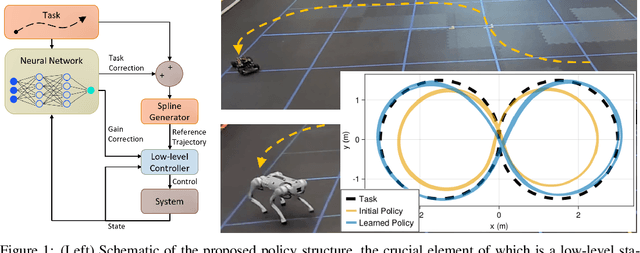
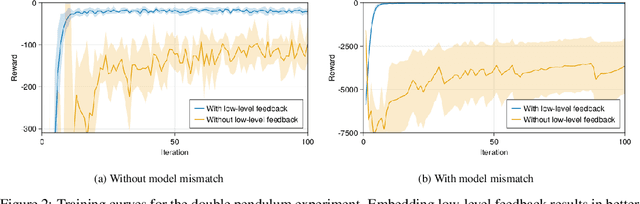
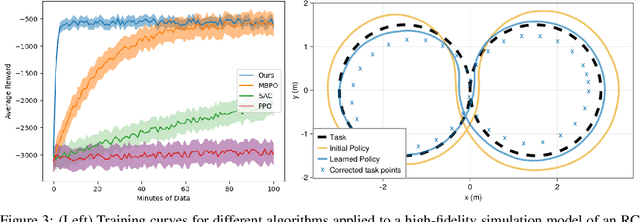
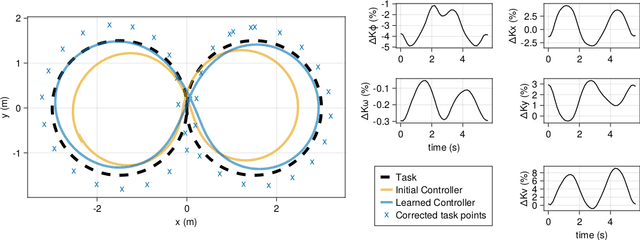
We focus on developing efficient and reliable policy optimization strategies for robot learning with real-world data. In recent years, policy gradient methods have emerged as a promising paradigm for training control policies in simulation. However, these approaches often remain too data inefficient or unreliable to train on real robotic hardware. In this paper we introduce a novel policy gradient-based policy optimization framework which systematically leverages a (possibly highly simplified) first-principles model and enables learning precise control policies with limited amounts of real-world data. Our approach $1)$ uses the derivatives of the model to produce sample-efficient estimates of the policy gradient and $2)$ uses the model to design a low-level tracking controller, which is embedded in the policy class. Theoretical analysis provides insight into how the presence of this feedback controller addresses overcomes key limitations of stand-alone policy gradient methods, while hardware experiments with a small car and quadruped demonstrate that our approach can learn precise control strategies reliably and with only minutes of real-world data.