 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaskirat Singh
SmartMask: Context Aware High-Fidelity Mask Generation for Fine-grained Object Insertion and Layout Control
Dec 08, 2023
The field of generative image inpainting and object insertion has made significant progress with the recent advent of latent diffusion models. Utilizing a precise object mask can greatly enhance these applications. However, due to the challenges users encounter in creating high-fidelity masks, there is a tendency for these methods to rely on more coarse masks (e.g., bounding box) for these applications. This results in limited control and compromised background content preservation. To overcome these limitations, we introduce SmartMask, which allows any novice user to create detailed masks for precise object insertion. Combined with a ControlNet-Inpaint model, our experiments demonstrate that SmartMask achieves superior object insertion quality, preserving the background content more effectively than previous methods. Notably, unlike prior works the proposed approach can also be used even without user-mask guidance, which allows it to perform mask-free object insertion at diverse positions and scales. Furthermore, we find that when used iteratively with a novel instruction-tuning based planning model, SmartMask can be used to design detailed layouts from scratch. As compared with user-scribble based layout design, we observe that SmartMask allows for better quality outputs with layout-to-image generation methods. Project page is available at https://smartmask-gen.github.io
IMPUS: Image Morphing with Perceptually-Uniform Sampling Using Diffusion Models
Nov 12, 2023We present a diffusion-based image morphing approach with perceptually-uniform sampling (IMPUS) that produces smooth, direct, and realistic interpolations given an image pair. A latent diffusion model has distinct conditional distributions and data embeddings for each of the two images, especially when they are from different classes. To bridge this gap, we interpolate in the locally linear and continuous text embedding space and Gaussian latent space. We first optimize the endpoint text embeddings and then map the images to the latent space using a probability flow ODE. Unlike existing work that takes an indirect morphing path, we show that the model adaptation yields a direct path and suppresses ghosting artifacts in the interpolated images. To achieve this, we propose an adaptive bottleneck constraint based on a novel relative perceptual path diversity score that automatically controls the bottleneck size and balances the diversity along the path with its directness. We also propose a perceptually-uniform sampling technique that enables visually smooth changes between the interpolated images. Extensive experiments validate that our IMPUS can achieve smooth, direct, and realistic image morphing and be applied to other image generation tasks.
Probabilistic and Semantic Descriptions of Image Manifolds and Their Applications
Jul 10, 2023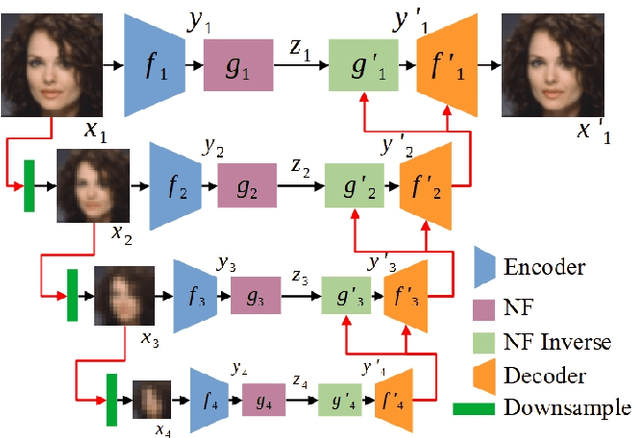

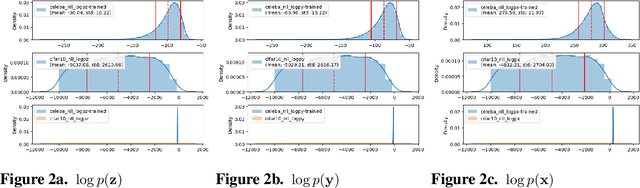

This paper begins with a description of methods for estimating probability density functions for images that reflects the observation that such data is usually constrained to lie in restricted regions of the high-dimensional image space - not every pattern of pixels is an image. It is common to say that images lie on a lower-dimensional manifold in the high-dimensional space. However, although images may lie on such lower-dimensional manifolds, it is not the case that all points on the manifold have an equal probability of being images. Images are unevenly distributed on the manifold, and our task is to devise ways to model this distribution as a probability distribution. In pursuing this goal, we consider generative models that are popular in AI and computer vision community. For our purposes, generative/probabilistic models should have the properties of 1) sample generation: it should be possible to sample from this distribution according to the modelled density function, and 2) probability computation: given a previously unseen sample from the dataset of interest, one should be able to compute the probability of the sample, at least up to a normalising constant. To this end, we investigate the use of methods such as normalising flow and diffusion models. We then show that such probabilistic descriptions can be used to construct defences against adversarial attacks. In addition to describing the manifold in terms of density, we also consider how semantic interpretations can be used to describe points on the manifold. To this end, we consider an emergent language framework which makes use of variational encoders to produce a disentangled representation of points that reside on a given manifold. Trajectories between points on a manifold can then be described in terms of evolving semantic descriptions.
Divide, Evaluate, and Refine: Evaluating and Improving Text-to-Image Alignment with Iterative VQA Feedback
Jul 10, 2023



The field of text-conditioned image generation has made unparalleled progress with the recent advent of latent diffusion models. While remarkable, as the complexity of given text input increases, the state-of-the-art diffusion models may still fail in generating images which accurately convey the semantics of the given prompt. Furthermore, it has been observed that such misalignments are often left undetected by pretrained multi-modal models such as CLIP. To address these problems, in this paper we explore a simple yet effective decompositional approach towards both evaluation and improvement of text-to-image alignment. In particular, we first introduce a Decompositional-Alignment-Score which given a complex prompt decomposes it into a set of disjoint assertions. The alignment of each assertion with generated images is then measured using a VQA model. Finally, alignment scores for different assertions are combined aposteriori to give the final text-to-image alignment score. Experimental analysis reveals that the proposed alignment metric shows significantly higher correlation with human ratings as opposed to traditional CLIP, BLIP scores. Furthermore, we also find that the assertion level alignment scores provide a useful feedback which can then be used in a simple iterative procedure to gradually increase the expression of different assertions in the final image outputs. Human user studies indicate that the proposed approach surpasses previous state-of-the-art by 8.7% in overall text-to-image alignment accuracy. Project page for our paper is available at https://1jsingh.github.io/divide-evaluate-and-refine
High-Fidelity Guided Image Synthesis with Latent Diffusion Models
Nov 30, 2022



Controllable image synthesis with user scribbles has gained huge public interest with the recent advent of text-conditioned latent diffusion models. The user scribbles control the color composition while the text prompt provides control over the overall image semantics. However, we note that prior works in this direction suffer from an intrinsic domain shift problem, wherein the generated outputs often lack details and resemble simplistic representations of the target domain. In this paper, we propose a novel guided image synthesis framework, which addresses this problem by modeling the output image as the solution of a constrained optimization problem. We show that while computing an exact solution to the optimization is infeasible, an approximation of the same can be achieved while just requiring a single pass of the reverse diffusion process. Additionally, we show that by simply defining a cross-attention based correspondence between the input text tokens and the user stroke-painting, the user is also able to control the semantics of different painted regions without requiring any conditional training or finetuning. Human user study results show that the proposed approach outperforms the previous state-of-the-art by over 85.32% on the overall user satisfaction scores. Project page for our paper is available at https://1jsingh.github.io/gradop.
UAV-based Visual Remote Sensing for Automated Building Inspection
Sep 27, 2022



Unmanned Aerial Vehicle (UAV) based remote sensing system incorporated with computer vision has demonstrated potential for assisting building construction and in disaster management like damage assessment during earthquakes. The vulnerability of a building to earthquake can be assessed through inspection that takes into account the expected damage progression of the associated component and the component's contribution to structural system performance. Most of these inspections are done manually, leading to high utilization of manpower, time, and cost. This paper proposes a methodology to automate these inspections through UAV-based image data collection and a software library for post-processing that helps in estimating the seismic structural parameters. The key parameters considered here are the distances between adjacent buildings, building plan-shape, building plan area, objects on the rooftop and rooftop layout. The accuracy of the proposed methodology in estimating the above-mentioned parameters is verified through field measurements taken using a distance measuring sensor and also from the data obtained through Google Earth. Additional details and code can be accessed from https://uvrsabi.github.io/ .
Real-Time Heuristic Framework for Safe Landing of UAVs in Dynamic Scenarios
Sep 11, 2022



The world we live in is full of technology and with each passing day the advancement and usage of UAVs increases efficiently. As a result of the many application scenarios, there are some missions where the UAVs are vulnerable to external disruptions, such as a ground station's loss of connectivity, security missions, safety concerns, and delivery-related missions. Therefore, depending on the scenario, this could affect the operations and result in the safe landing of UAVs. Hence, this paper presents a heuristic approach towards safe landing of multi-rotor UAVs in the dynamic environments. The aim of this approach is to detect safe potential landing zones - PLZ, and find out the best one to land in. The PLZ is initially, detected by processing an image through the canny edge algorithm, and then the diameter-area estimation is applied for each region with minimal edges. The spots that have a higher area than the vehicle's clearance are labeled as safe PLZ. Onto the second phase of this approach, the velocities of dynamic obstacles that are moving towards the PLZs are calculated and their time to reach the zones are taken into consideration. The ETA of the UAV is calculated and during the descending of UAV, the dynamic obstacle avoidance is executed. The approach tested on the real-world environments have shown better results from existing work.
Paint2Pix: Interactive Painting based Progressive Image Synthesis and Editing
Aug 17, 2022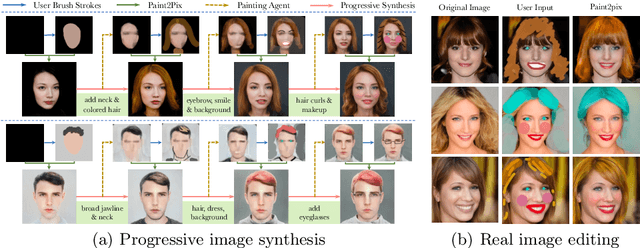
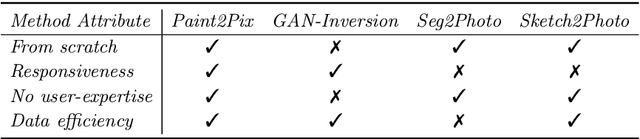
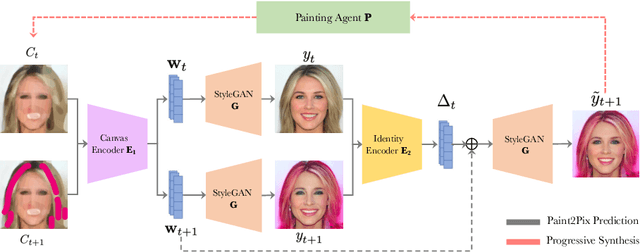
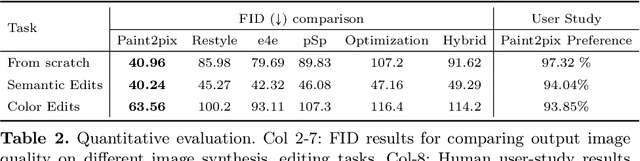
Controllable image synthesis with user scribbles is a topic of keen interest in the computer vision community. In this paper, for the first time we study the problem of photorealistic image synthesis from incomplete and primitive human paintings. In particular, we propose a novel approach paint2pix, which learns to predict (and adapt) "what a user wants to draw" from rudimentary brushstroke inputs, by learning a mapping from the manifold of incomplete human paintings to their realistic renderings. When used in conjunction with recent works in autonomous painting agents, we show that paint2pix can be used for progressive image synthesis from scratch. During this process, paint2pix allows a novice user to progressively synthesize the desired image output, while requiring just few coarse user scribbles to accurately steer the trajectory of the synthesis process. Furthermore, we find that our approach also forms a surprisingly convenient approach for real image editing, and allows the user to perform a diverse range of custom fine-grained edits through the addition of only a few well-placed brushstrokes. Supplemental video and demo are available at https://1jsingh.github.io/paint2pix
* ECCV 2022
Intelli-Paint: Towards Developing Human-like Painting Agents
Dec 16, 2021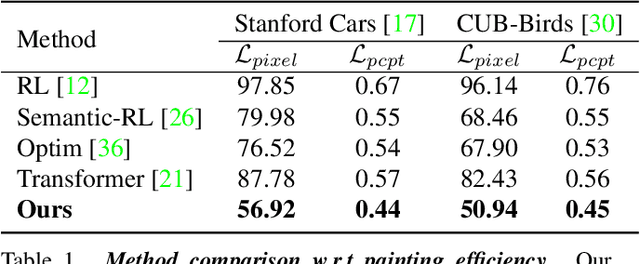
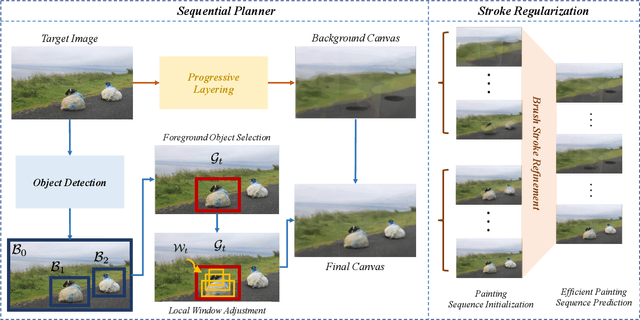


The generation of well-designed artwork is often quite time-consuming and assumes a high degree of proficiency on part of the human painter. In order to facilitate the human painting process, substantial research efforts have been made on teaching machines how to "paint like a human", and then using the trained agent as a painting assistant tool for human users. However, current research in this direction is often reliant on a progressive grid-based division strategy wherein the agent divides the overall image into successively finer grids, and then proceeds to paint each of them in parallel. This inevitably leads to artificial painting sequences which are not easily intelligible to human users. To address this, we propose a novel painting approach which learns to generate output canvases while exhibiting a more human-like painting style. The proposed painting pipeline Intelli-Paint consists of 1) a progressive layering strategy which allows the agent to first paint a natural background scene representation before adding in each of the foreground objects in a progressive fashion. 2) We also introduce a novel sequential brushstroke guidance strategy which helps the painting agent to shift its attention between different image regions in a semantic-aware manner. 3) Finally, we propose a brushstroke regularization strategy which allows for ~60-80% reduction in the total number of required brushstrokes without any perceivable differences in the quality of the generated canvases. Through both quantitative and qualitative results, we show that the resulting agents not only show enhanced efficiency in output canvas generation but also exhibit a more natural-looking painting style which would better assist human users express their ideas through digital artwork.
Sparse Attention Guided Dynamic Value Estimation for Single-Task Multi-Scene Reinforcement Learning
Feb 14, 2021



Training deep reinforcement learning agents on environments with multiple levels / scenes from the same task, has become essential for many applications aiming to achieve generalization and domain transfer from simulation to the real world. While such a strategy is helpful with generalization, the use of multiple scenes significantly increases the variance of samples collected for policy gradient computations. Current methods, effectively continue to view this collection of scenes as a single Markov decision process (MDP), and thus learn a scene-generic value function V(s). However, we argue that the sample variance for a multi-scene environment is best minimized by treating each scene as a distinct MDP, and then learning a joint value function V(s,M) dependent on both state s and MDP M. We further demonstrate that the true joint value function for a multi-scene environment, follows a multi-modal distribution which is not captured by traditional CNN / LSTM based critic networks. To this end, we propose a dynamic value estimation (DVE) technique, which approximates the true joint value function through a sparse attention mechanism over multiple value function hypothesis / modes. The resulting agent not only shows significant improvements in the final reward score across a range of OpenAI ProcGen environments, but also exhibits enhanced navigation efficiency and provides an implicit mechanism for unsupervised state-space skill decomposition.