 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianyu Wang
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Apr 23, 2024
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
Scaling on-chip photonic neural processors using arbitrarily programmable wave propagation
Feb 27, 2024On-chip photonic processors for neural networks have potential benefits in both speed and energy efficiency but have not yet reached the scale at which they can outperform electronic processors. The dominant paradigm for designing on-chip photonics is to make networks of relatively bulky discrete components connected by one-dimensional waveguides. A far more compact alternative is to avoid explicitly defining any components and instead sculpt the continuous substrate of the photonic processor to directly perform the computation using waves freely propagating in two dimensions. We propose and demonstrate a device whose refractive index as a function of space, $n(x,z)$, can be rapidly reprogrammed, allowing arbitrary control over the wave propagation in the device. Our device, a 2D-programmable waveguide, combines photoconductive gain with the electro-optic effect to achieve massively parallel modulation of the refractive index of a slab waveguide, with an index modulation depth of $10^{-3}$ and approximately $10^4$ programmable degrees of freedom. We used a prototype device with a functional area of $12\,\text{mm}^2$ to perform neural-network inference with up to 49-dimensional input vectors in a single pass, achieving 96% accuracy on vowel classification and 86% accuracy on $7 \times 7$-pixel MNIST handwritten-digit classification. This is a scale beyond that of previous photonic chips relying on discrete components, illustrating the benefit of the continuous-waves paradigm. In principle, with large enough chip area, the reprogrammability of the device's refractive index distribution enables the reconfigurable realization of any passive, linear photonic circuit or device. This promises the development of more compact and versatile photonic systems for a wide range of applications, including optical processing, smart sensing, spectroscopy, and optical communications.
Geometry-Calibrated DRO: Combating Over-Pessimism with Free Energy Implications
Nov 08, 2023Machine learning algorithms minimizing average risk are susceptible to distributional shifts. Distributionally Robust Optimization (DRO) addresses this issue by optimizing the worst-case risk within an uncertainty set. However, DRO suffers from over-pessimism, leading to low-confidence predictions, poor parameter estimations as well as poor generalization. In this work, we conduct a theoretical analysis of a probable root cause of over-pessimism: excessive focus on noisy samples. To alleviate the impact of noise, we incorporate data geometry into calibration terms in DRO, resulting in our novel Geometry-Calibrated DRO (GCDRO) for regression. We establish the connection between our risk objective and the Helmholtz free energy in statistical physics, and this free-energy-based risk can extend to standard DRO methods. Leveraging gradient flow in Wasserstein space, we develop an approximate minimax optimization algorithm with a bounded error ratio and elucidate how our approach mitigates noisy sample effects. Comprehensive experiments confirm GCDRO's superiority over conventional DRO methods.
The hardware is the software
Oct 20, 2023Human brains and bodies are not hardware running software: the hardware is the software. We reason that because the microscopic physics of artificial-intelligence hardware and of human biological "hardware" is distinct, neuromorphic engineers need to be cautious (and yet also creative) in how we take inspiration from biological intelligence. We should focus primarily on principles and design ideas that respect -- and embrace -- the underlying hardware physics of non-biological intelligent systems, rather than abstracting it away. We see a major role for neuroscience in neuromorphic computing as identifying the physics-agnostic principles of biological intelligence -- that is the principles of biological intelligence that can be gainfully adapted and applied to any physical hardware.
Variational Inference for Scalable 3D Object-centric Learning
Sep 25, 2023We tackle the task of scalable unsupervised object-centric representation learning on 3D scenes. Existing approaches to object-centric representation learning show limitations in generalizing to larger scenes as their learning processes rely on a fixed global coordinate system. In contrast, we propose to learn view-invariant 3D object representations in localized object coordinate systems. To this end, we estimate the object pose and appearance representation separately and explicitly map object representations across views while maintaining object identities. We adopt an amortized variational inference pipeline that can process sequential input and scalably update object latent distributions online. To handle large-scale scenes with a varying number of objects, we further introduce a Cognitive Map that allows the registration and query of objects on a per-scene global map to achieve scalable representation learning. We explore the object-centric neural radiance field (NeRF) as our 3D scene representation, which is jointly modeled within our unsupervised object-centric learning framework. Experimental results on synthetic and real datasets show that our proposed method can infer and maintain object-centric representations of 3D scenes and outperforms previous models.
Anisotropic body compliance facilitates robotic sidewinding in complex environments
Sep 24, 2023Sidewinding, a locomotion strategy characterized by the coordination of lateral and vertical body undulations, is frequently observed in rattlesnakes and has been successfully reconstructed by limbless robotic systems for effective movement across diverse terrestrial terrains. However, the integration of compliant mechanisms into sidewinding limbless robots remains less explored, posing challenges for navigation in complex, rheologically diverse environments. Inspired by a notable control simplification via mechanical intelligence in lateral undulation, which offloads feedback control to passive body mechanics and interactions with the environment, we present an innovative design of a mechanically intelligent limbless robot for sidewinding. This robot features a decentralized bilateral cable actuation system that resembles organismal muscle actuation mechanisms. We develop a feedforward controller that incorporates programmable body compliance into the sidewinding gait template. Our experimental results highlight the emergence of mechanical intelligence when the robot is equipped with an appropriate level of body compliance. This allows the robot to 1) locomote more energetically efficiently, as evidenced by a reduced cost of transport, and 2) navigate through terrain heterogeneities, all achieved in an open-loop manner, without the need for environmental awareness.
Robust self-propulsion in sand using simply controlled vibrating cubes
Sep 22, 2023Much of the Earth and many surfaces of extraterrestrial bodies are composed of in-cohesive particle matter. Locomoting on granular terrain is challenging for common robotic devices, either wheeled or legged. In this work, we discover a robust alternative locomotion mechanism on granular media -- generating movement via self-vibration. To demonstrate the effectiveness of this locomotion mechanism, we develop a cube-shaped robot with an embedded vibratory motor and conduct systematic experiments on diverse granular terrains of various particle properties. We investigate how locomotion changes as a function of vibration frequency/intensity on granular terrains. Compared to hard surfaces, we find such a vibratory locomotion mechanism enables the robot to move faster, and more stable on granular surfaces, facilitated by the interaction between the body and surrounding granules. The simplicity in structural design and controls of this robotic system indicates that vibratory locomotion can be a valuable alternative way to produce robust locomotion on granular terrains. We further demonstrate that such cube-shape robots can be used as modular units for morphologically structured vibratory robots with capabilities of maneuverable forward and turning motions, showing potential practical scenarios for robotic systems.
Dynamic Handover: Throw and Catch with Bimanual Hands
Sep 11, 2023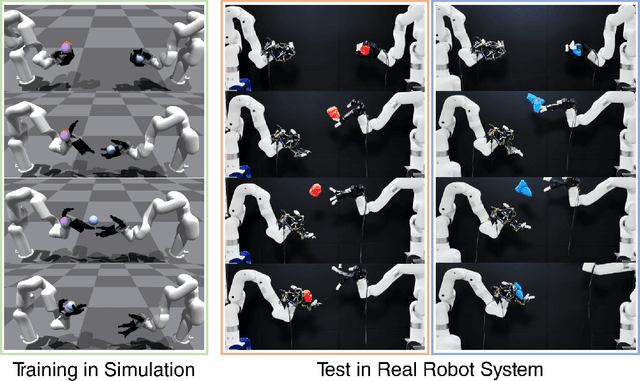
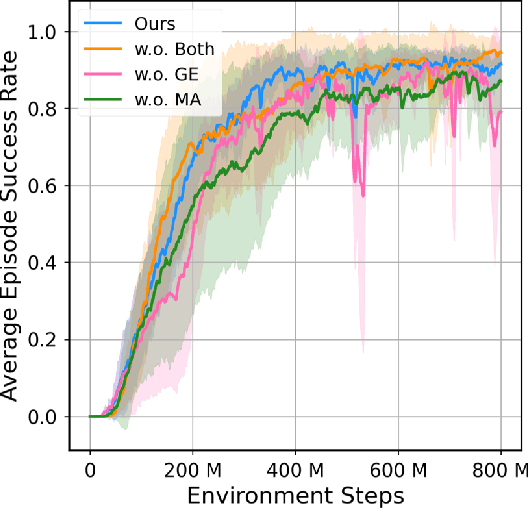
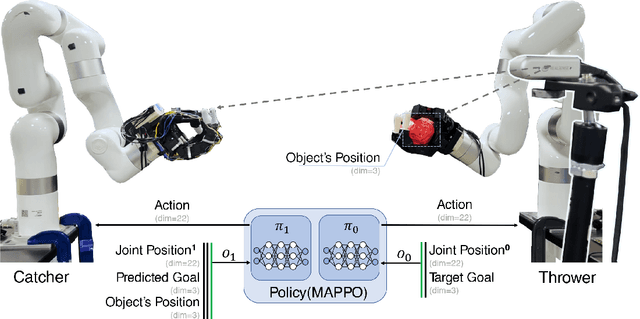
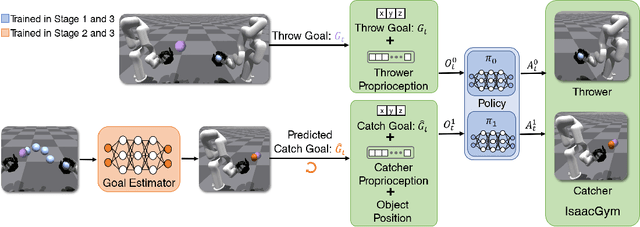
Humans throw and catch objects all the time. However, such a seemingly common skill introduces a lot of challenges for robots to achieve: The robots need to operate such dynamic actions at high-speed, collaborate precisely, and interact with diverse objects. In this paper, we design a system with two multi-finger hands attached to robot arms to solve this problem. We train our system using Multi-Agent Reinforcement Learning in simulation and perform Sim2Real transfer to deploy on the real robots. To overcome the Sim2Real gap, we provide multiple novel algorithm designs including learning a trajectory prediction model for the object. Such a model can help the robot catcher has a real-time estimation of where the object will be heading, and then react accordingly. We conduct our experiments with multiple objects in the real-world system, and show significant improvements over multiple baselines. Our project page is available at \url{https://binghao-huang.github.io/dynamic_handover/}.
WALL-E: Embodied Robotic WAiter Load Lifting with Large Language Model
Aug 31, 2023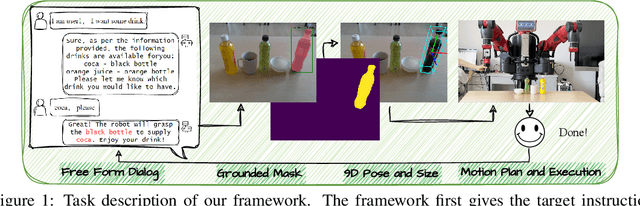
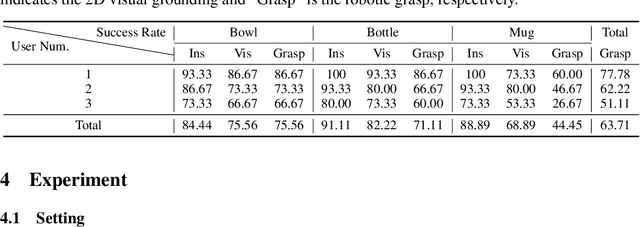
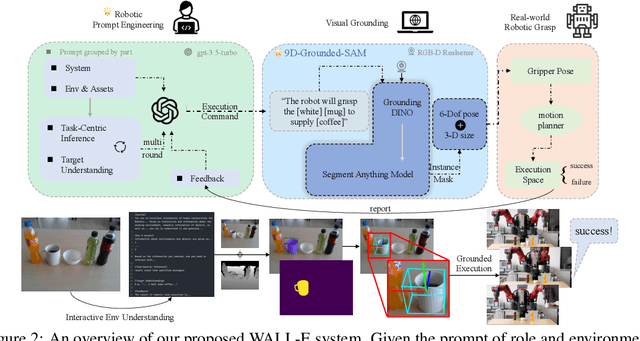
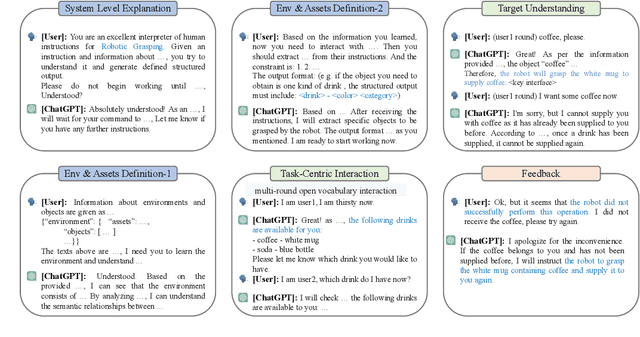
Enabling robots to understand language instructions and react accordingly to visual perception has been a long-standing goal in the robotics research community. Achieving this goal requires cutting-edge advances in natural language processing, computer vision, and robotics engineering. Thus, this paper mainly investigates the potential of integrating the most recent Large Language Models (LLMs) and existing visual grounding and robotic grasping system to enhance the effectiveness of the human-robot interaction. We introduce the WALL-E (Embodied Robotic WAiter load lifting with Large Language model) as an example of this integration. The system utilizes the LLM of ChatGPT to summarize the preference object of the users as a target instruction via the multi-round interactive dialogue. The target instruction is then forwarded to a visual grounding system for object pose and size estimation, following which the robot grasps the object accordingly. We deploy this LLM-empowered system on the physical robot to provide a more user-friendly interface for the instruction-guided grasping task. The further experimental results on various real-world scenarios demonstrated the feasibility and efficacy of our proposed framework. See the project website at: https://star-uu-wang.github.io/WALL-E/
SILT: Shadow-aware Iterative Label Tuning for Learning to Detect Shadows from Noisy Labels
Aug 23, 2023
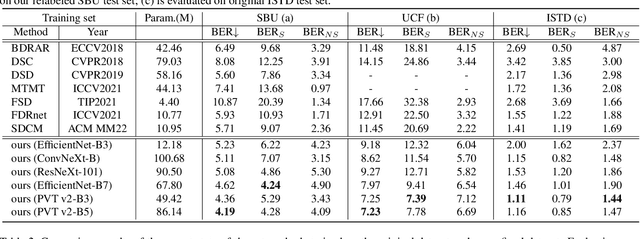

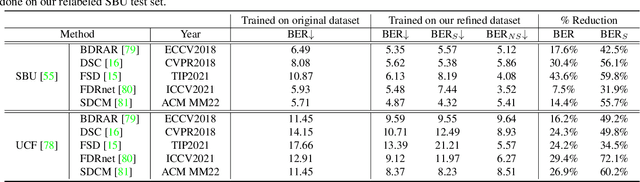
Existing shadow detection datasets often contain missing or mislabeled shadows, which can hinder the performance of deep learning models trained directly on such data. To address this issue, we propose SILT, the Shadow-aware Iterative Label Tuning framework, which explicitly considers noise in shadow labels and trains the deep model in a self-training manner. Specifically, we incorporate strong data augmentations with shadow counterfeiting to help the network better recognize non-shadow regions and alleviate overfitting. We also devise a simple yet effective label tuning strategy with global-local fusion and shadow-aware filtering to encourage the network to make significant refinements on the noisy labels. We evaluate the performance of SILT by relabeling the test set of the SBU dataset and conducting various experiments. Our results show that even a simple U-Net trained with SILT can outperform all state-of-the-art methods by a large margin. When trained on SBU / UCF / ISTD, our network can successfully reduce the Balanced Error Rate by 25.2% / 36.9% / 21.3% over the best state-of-the-art method.