 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiaomiao Liu
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Apr 23, 2024
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
HashPoint: Accelerated Point Searching and Sampling for Neural Rendering
Apr 22, 2024In this paper, we address the problem of efficient point searching and sampling for volume neural rendering. Within this realm, two typical approaches are employed: rasterization and ray tracing. The rasterization-based methods enable real-time rendering at the cost of increased memory and lower fidelity. In contrast, the ray-tracing-based methods yield superior quality but demand longer rendering time. We solve this problem by our HashPoint method combining these two strategies, leveraging rasterization for efficient point searching and sampling, and ray marching for rendering. Our method optimizes point searching by rasterizing points within the camera's view, organizing them in a hash table, and facilitating rapid searches. Notably, we accelerate the rendering process by adaptive sampling on the primary surface encountered by the ray. Our approach yields substantial speed-up for a range of state-of-the-art ray-tracing-based methods, maintaining equivalent or superior accuracy across synthetic and real test datasets. The code will be available at https://jiahao-ma.github.io/hashpoint/.
* CVPR2024 Highlight
MIDGET: Music Conditioned 3D Dance Generation
Apr 18, 2024In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
* 12 pages, 6 figures Published in AI 2023: Advances in Artificial Intelligence
Scene-aware Human Motion Forecasting via Mutual Distance Prediction
Oct 01, 2023In this paper, we tackle the problem of scene-aware 3D human motion forecasting. A key challenge of this task is to predict future human motions that are consistent with the scene, by modelling the human-scene interactions. While recent works have demonstrated that explicit constraints on human-scene interactions can prevent the occurrence of ghost motion, they only provide constraints on partial human motion e.g., the global motion of the human or a few joints contacting the scene, leaving the rest motion unconstrained. To address this limitation, we propose to model the human-scene interaction with the mutual distance between the human body and the scene. Such mutual distances constrain both the local and global human motion, resulting in a whole-body motion constrained prediction. In particular, mutual distance constraints consist of two components, the signed distance of each vertex on the human mesh to the scene surface, and the distance of basis scene points to the human mesh. We develop a pipeline with two prediction steps that first predicts the future mutual distances from the past human motion sequence and the scene, and then forecasts the future human motion conditioning on the predicted mutual distances. During training, we explicitly encourage consistency between the predicted poses and the mutual distances. Our approach outperforms the state-of-the-art methods on both synthetic and real datasets.
Variational Inference for Scalable 3D Object-centric Learning
Sep 25, 2023We tackle the task of scalable unsupervised object-centric representation learning on 3D scenes. Existing approaches to object-centric representation learning show limitations in generalizing to larger scenes as their learning processes rely on a fixed global coordinate system. In contrast, we propose to learn view-invariant 3D object representations in localized object coordinate systems. To this end, we estimate the object pose and appearance representation separately and explicitly map object representations across views while maintaining object identities. We adopt an amortized variational inference pipeline that can process sequential input and scalably update object latent distributions online. To handle large-scale scenes with a varying number of objects, we further introduce a Cognitive Map that allows the registration and query of objects on a per-scene global map to achieve scalable representation learning. We explore the object-centric neural radiance field (NeRF) as our 3D scene representation, which is jointly modeled within our unsupervised object-centric learning framework. Experimental results on synthetic and real datasets show that our proposed method can infer and maintain object-centric representations of 3D scenes and outperforms previous models.
LDP: Language-driven Dual-Pixel Image Defocus Deblurring Network
Jul 21, 2023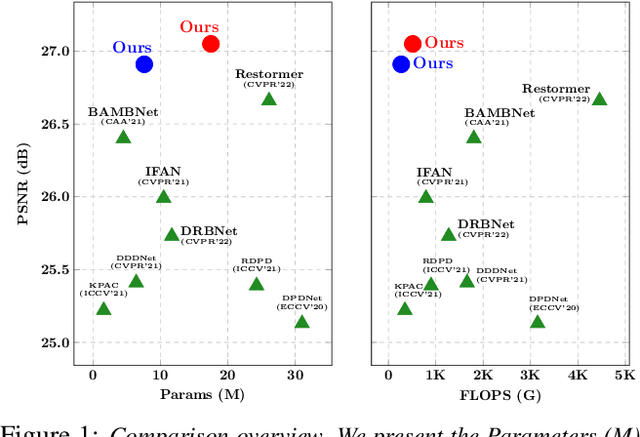
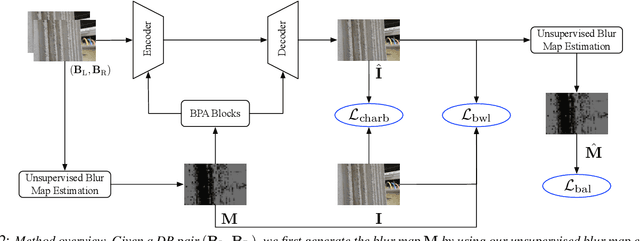
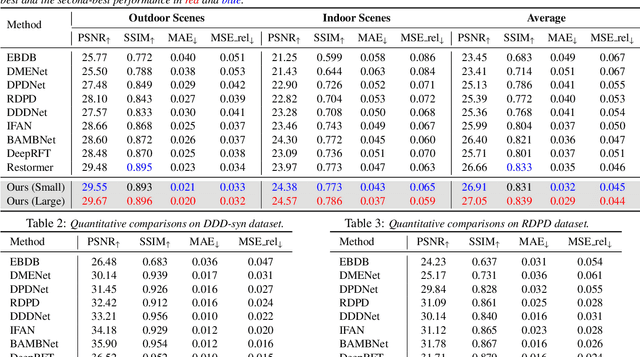

Recovering sharp images from dual-pixel (DP) pairs with disparity-dependent blur is a challenging task.~Existing blur map-based deblurring methods have demonstrated promising results. In this paper, we propose, to the best of our knowledge, the first framework to introduce the contrastive language-image pre-training framework (CLIP) to achieve accurate blur map estimation from DP pairs unsupervisedly. To this end, we first carefully design text prompts to enable CLIP to understand blur-related geometric prior knowledge from the DP pair. Then, we propose a format to input stereo DP pair to the CLIP without any fine-tuning, where the CLIP is pre-trained on monocular images. Given the estimated blur map, we introduce a blur-prior attention block, a blur-weighting loss and a blur-aware loss to recover the all-in-focus image. Our method achieves state-of-the-art performance in extensive experiments.
Parametric Depth Based Feature Representation Learning for Object Detection and Segmentation in Bird's Eye View
Jul 11, 2023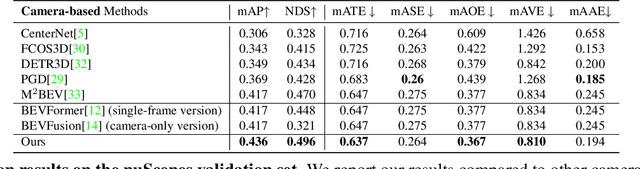

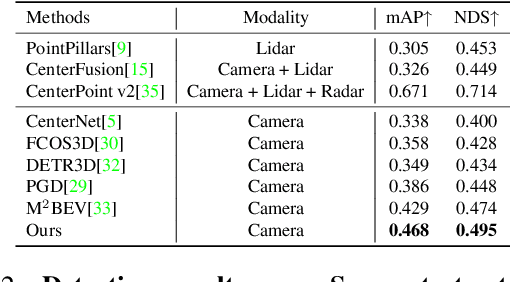
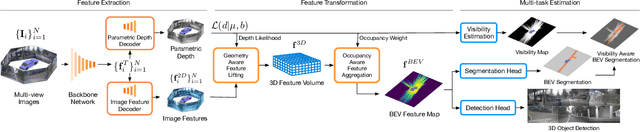
Recent vision-only perception models for autonomous driving achieved promising results by encoding multi-view image features into Bird's-Eye-View (BEV) space. A critical step and the main bottleneck of these methods is transforming image features into the BEV coordinate frame. This paper focuses on leveraging geometry information, such as depth, to model such feature transformation. Existing works rely on non-parametric depth distribution modeling leading to significant memory consumption, or ignore the geometry information to address this problem. In contrast, we propose to use parametric depth distribution modeling for feature transformation. We first lift the 2D image features to the 3D space defined for the ego vehicle via a predicted parametric depth distribution for each pixel in each view. Then, we aggregate the 3D feature volume based on the 3D space occupancy derived from depth to the BEV frame. Finally, we use the transformed features for downstream tasks such as object detection and semantic segmentation. Existing semantic segmentation methods do also suffer from an hallucination problem as they do not take visibility information into account. This hallucination can be particularly problematic for subsequent modules such as control and planning. To mitigate the issue, our method provides depth uncertainty and reliable visibility-aware estimations. We further leverage our parametric depth modeling to present a novel visibility-aware evaluation metric that, when taken into account, can mitigate the hallucination problem. Extensive experiments on object detection and semantic segmentation on the nuScenes datasets demonstrate that our method outperforms existing methods on both tasks.
VisFusion: Visibility-aware Online 3D Scene Reconstruction from Videos
Apr 21, 2023
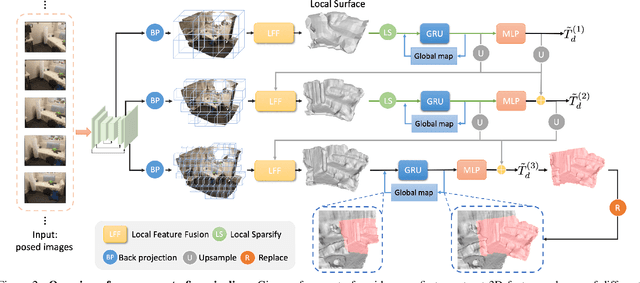

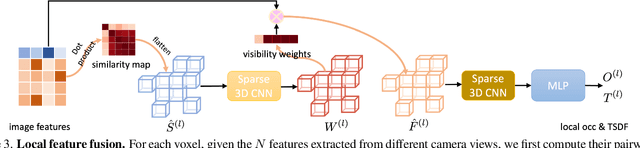
We propose VisFusion, a visibility-aware online 3D scene reconstruction approach from posed monocular videos. In particular, we aim to reconstruct the scene from volumetric features. Unlike previous reconstruction methods which aggregate features for each voxel from input views without considering its visibility, we aim to improve the feature fusion by explicitly inferring its visibility from a similarity matrix, computed from its projected features in each image pair. Following previous works, our model is a coarse-to-fine pipeline including a volume sparsification process. Different from their works which sparsify voxels globally with a fixed occupancy threshold, we perform the sparsification on a local feature volume along each visual ray to preserve at least one voxel per ray for more fine details. The sparse local volume is then fused with a global one for online reconstruction. We further propose to predict TSDF in a coarse-to-fine manner by learning its residuals across scales leading to better TSDF predictions. Experimental results on benchmarks show that our method can achieve superior performance with more scene details. Code is available at: https://github.com/huiyu-gao/VisFusion
Sampled Transformer for Point Sets
Feb 28, 2023
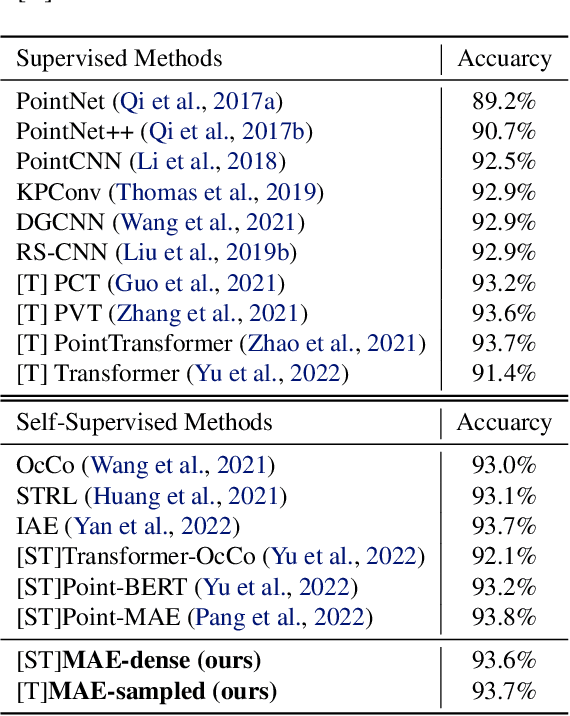
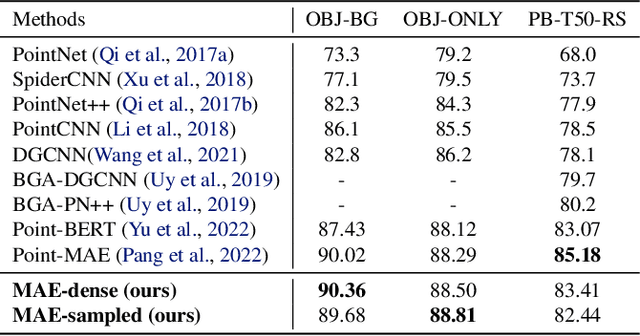
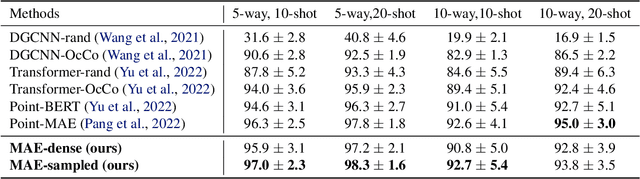
The sparse transformer can reduce the computational complexity of the self-attention layers to $O(n)$, whilst still being a universal approximator of continuous sequence-to-sequence functions. However, this permutation variant operation is not appropriate for direct application to sets. In this paper, we proposed an $O(n)$ complexity sampled transformer that can process point set elements directly without any additional inductive bias. Our sampled transformer introduces random element sampling, which randomly splits point sets into subsets, followed by applying a shared Hamiltonian self-attention mechanism to each subset. The overall attention mechanism can be viewed as a Hamiltonian cycle in the complete attention graph, and the permutation of point set elements is equivalent to randomly sampling Hamiltonian cycles. This mechanism implements a Monte Carlo simulation of the $O(n^2)$ dense attention connections. We show that it is a universal approximator for continuous set-to-set functions. Experimental results on point-clouds show comparable or better accuracy with significantly reduced computational complexity compared to the dense transformer or alternative sparse attention schemes.
Contact-aware Human Motion Forecasting
Oct 08, 2022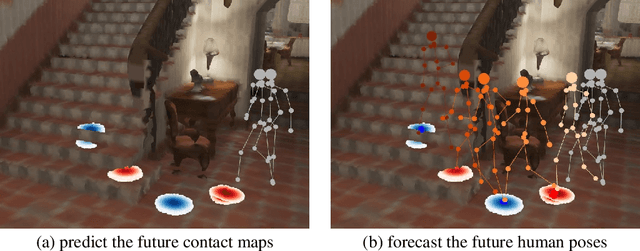
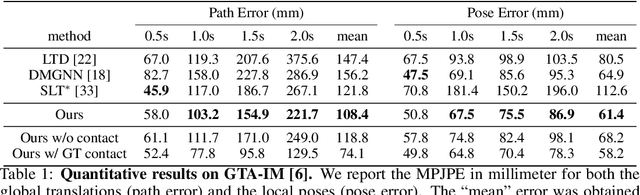
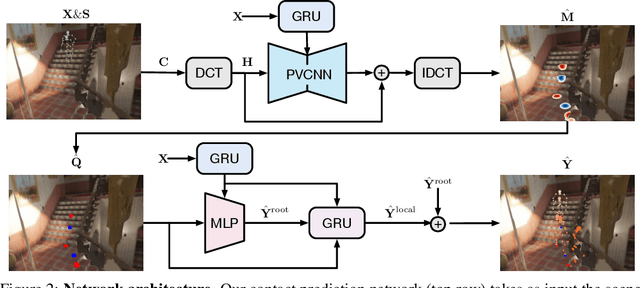
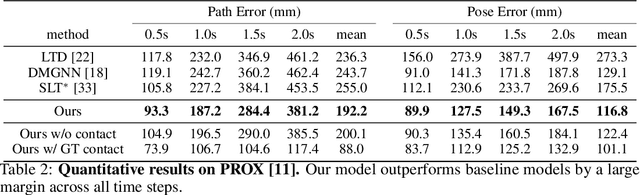
In this paper, we tackle the task of scene-aware 3D human motion forecasting, which consists of predicting future human poses given a 3D scene and a past human motion. A key challenge of this task is to ensure consistency between the human and the scene, accounting for human-scene interactions. Previous attempts to do so model such interactions only implicitly, and thus tend to produce artifacts such as "ghost motion" because of the lack of explicit constraints between the local poses and the global motion. Here, by contrast, we propose to explicitly model the human-scene contacts. To this end, we introduce distance-based contact maps that capture the contact relationships between every joint and every 3D scene point at each time instant. We then develop a two-stage pipeline that first predicts the future contact maps from the past ones and the scene point cloud, and then forecasts the future human poses by conditioning them on the predicted contact maps. During training, we explicitly encourage consistency between the global motion and the local poses via a prior defined using the contact maps and future poses. Our approach outperforms the state-of-the-art human motion forecasting and human synthesis methods on both synthetic and real datasets. Our code is available at https://github.com/wei-mao-2019/ContAwareMotionPred.