 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJay Vakil
RoboHive: A Unified Framework for Robot Learning
Oct 10, 2023
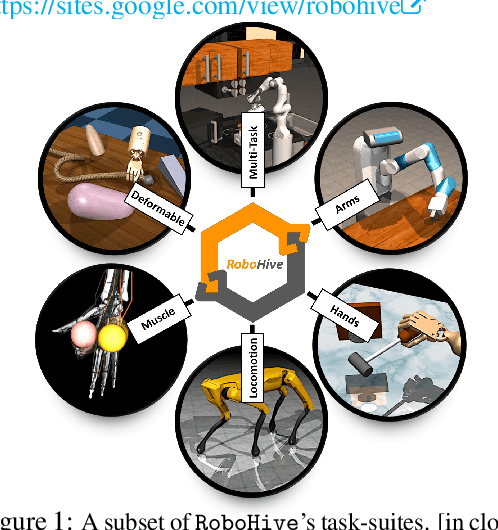

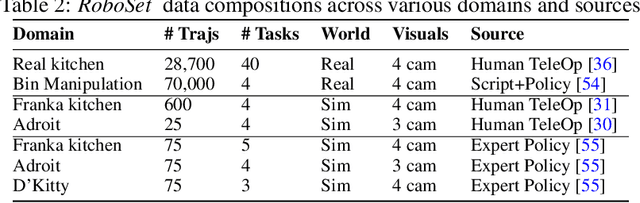
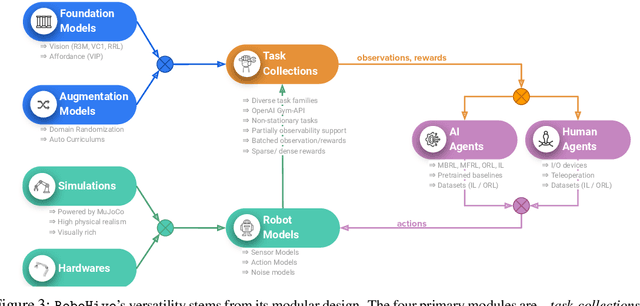
We present RoboHive, a comprehensive software platform and ecosystem for research in the field of Robot Learning and Embodied Artificial Intelligence. Our platform encompasses a diverse range of pre-existing and novel environments, including dexterous manipulation with the Shadow Hand, whole-arm manipulation tasks with Franka and Fetch robots, quadruped locomotion, among others. Included environments are organized within and cover multiple domains such as hand manipulation, locomotion, multi-task, multi-agent, muscles, etc. In comparison to prior works, RoboHive offers a streamlined and unified task interface taking dependency on only a minimal set of well-maintained packages, features tasks with high physics fidelity and rich visual diversity, and supports common hardware drivers for real-world deployment. The unified interface of RoboHive offers a convenient and accessible abstraction for algorithmic research in imitation, reinforcement, multi-task, and hierarchical learning. Furthermore, RoboHive includes expert demonstrations and baseline results for most environments, providing a standard for benchmarking and comparisons. Details: https://sites.google.com/view/robohive
What do we learn from a large-scale study of pre-trained visual representations in sim and real environments?
Oct 03, 2023



We present a large empirical investigation on the use of pre-trained visual representations (PVRs) for training downstream policies that execute real-world tasks. Our study spans five different PVRs, two different policy-learning paradigms (imitation and reinforcement learning), and three different robots for 5 distinct manipulation and indoor navigation tasks. From this effort, we can arrive at three insights: 1) the performance trends of PVRs in the simulation are generally indicative of their trends in the real world, 2) the use of PVRs enables a first-of-its-kind result with indoor ImageNav (zero-shot transfer to a held-out scene in the real world), and 3) the benefits from variations in PVRs, primarily data-augmentation and fine-tuning, also transfer to the real-world performance. See project website for additional details and visuals.
RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking
Sep 05, 2023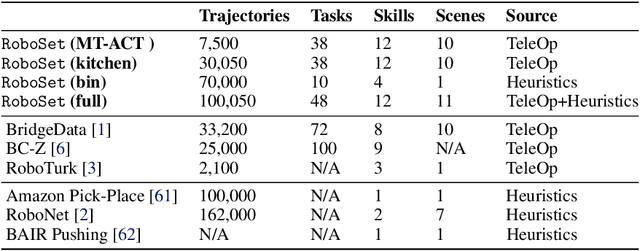
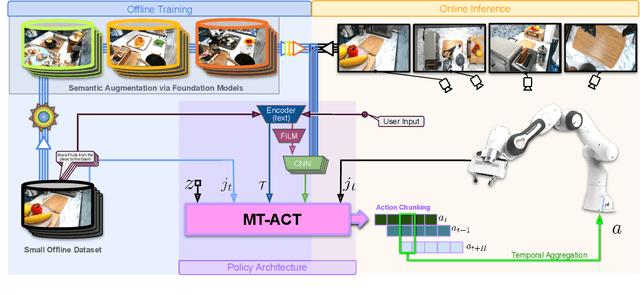
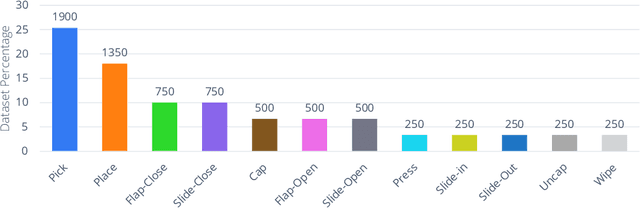
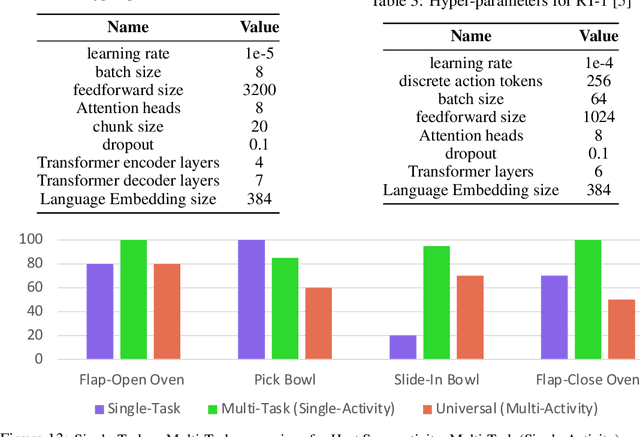
The grand aim of having a single robot that can manipulate arbitrary objects in diverse settings is at odds with the paucity of robotics datasets. Acquiring and growing such datasets is strenuous due to manual efforts, operational costs, and safety challenges. A path toward such an universal agent would require a structured framework capable of wide generalization but trained within a reasonable data budget. In this paper, we develop an efficient system (RoboAgent) for training universal agents capable of multi-task manipulation skills using (a) semantic augmentations that can rapidly multiply existing datasets and (b) action representations that can extract performant policies with small yet diverse multi-modal datasets without overfitting. In addition, reliable task conditioning and an expressive policy architecture enable our agent to exhibit a diverse repertoire of skills in novel situations specified using language commands. Using merely 7500 demonstrations, we are able to train a single agent capable of 12 unique skills, and demonstrate its generalization over 38 tasks spread across common daily activities in diverse kitchen scenes. On average, RoboAgent outperforms prior methods by over 40% in unseen situations while being more sample efficient and being amenable to capability improvements and extensions through fine-tuning. Videos at https://robopen.github.io/
Spatial-Language Attention Policies for Efficient Robot Learning
Apr 21, 2023We investigate how to build and train spatial representations for robot decision making with Transformers. In particular, for robots to operate in a range of environments, we must be able to quickly train or fine-tune robot sensorimotor policies that are robust to clutter, data efficient, and generalize well to different circumstances. As a solution, we propose Spatial Language Attention Policies (SLAP). SLAP uses three-dimensional tokens as the input representation to train a single multi-task, language-conditioned action prediction policy. Our method shows 80% success rate in the real world across eight tasks with a single model, and a 47.5% success rate when unseen clutter and unseen object configurations are introduced, even with only a handful of examples per task. This represents an improvement of 30% over prior work (20% given unseen distractors and configurations).