 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShubham Tulsiani
G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis
Apr 18, 2024
We propose G-HOP, a denoising diffusion based generative prior for hand-object interactions that allows modeling both the 3D object and a human hand, conditioned on the object category. To learn a 3D spatial diffusion model that can capture this joint distribution, we represent the human hand via a skeletal distance field to obtain a representation aligned with the (latent) signed distance field for the object. We show that this hand-object prior can then serve as generic guidance to facilitate other tasks like reconstruction from interaction clip and human grasp synthesis. We believe that our model, trained by aggregating seven diverse real-world interaction datasets spanning across 155 categories, represents a first approach that allows jointly generating both hand and object. Our empirical evaluations demonstrate the benefit of this joint prior in video-based reconstruction and human grasp synthesis, outperforming current task-specific baselines. Project website: https://judyye.github.io/ghop-www
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Apr 04, 2024We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
Cameras as Rays: Pose Estimation via Ray Diffusion
Feb 22, 2024Estimating camera poses is a fundamental task for 3D reconstruction and remains challenging given sparse views (<10). In contrast to existing approaches that pursue top-down prediction of global parametrizations of camera extrinsics, we propose a distributed representation of camera pose that treats a camera as a bundle of rays. This representation allows for a tight coupling with spatial image features improving pose precision. We observe that this representation is naturally suited for set-level level transformers and develop a regression-based approach that maps image patches to corresponding rays. To capture the inherent uncertainties in sparse-view pose inference, we adapt this approach to learn a denoising diffusion model which allows us to sample plausible modes while improving performance. Our proposed methods, both regression- and diffusion-based, demonstrate state-of-the-art performance on camera pose estimation on CO3D while generalizing to unseen object categories and in-the-wild captures.
UpFusion: Novel View Diffusion from Unposed Sparse View Observations
Jan 04, 2024We propose UpFusion, a system that can perform novel view synthesis and infer 3D representations for an object given a sparse set of reference images without corresponding pose information. Current sparse-view 3D inference methods typically rely on camera poses to geometrically aggregate information from input views, but are not robust in-the-wild when such information is unavailable/inaccurate. In contrast, UpFusion sidesteps this requirement by learning to implicitly leverage the available images as context in a conditional generative model for synthesizing novel views. We incorporate two complementary forms of conditioning into diffusion models for leveraging the input views: a) via inferring query-view aligned features using a scene-level transformer, b) via intermediate attentional layers that can directly observe the input image tokens. We show that this mechanism allows generating high-fidelity novel views while improving the synthesis quality given additional (unposed) images. We evaluate our approach on the Co3Dv2 and Google Scanned Objects datasets and demonstrate the benefits of our method over pose-reliant sparse-view methods as well as single-view methods that cannot leverage additional views. Finally, we also show that our learned model can generalize beyond the training categories and even allow reconstruction from self-captured images of generic objects in-the-wild.
Towards Generalizable Zero-Shot Manipulation via Translating Human Interaction Plans
Dec 01, 2023We pursue the goal of developing robots that can interact zero-shot with generic unseen objects via a diverse repertoire of manipulation skills and show how passive human videos can serve as a rich source of data for learning such generalist robots. Unlike typical robot learning approaches which directly learn how a robot should act from interaction data, we adopt a factorized approach that can leverage large-scale human videos to learn how a human would accomplish a desired task (a human plan), followed by translating this plan to the robots embodiment. Specifically, we learn a human plan predictor that, given a current image of a scene and a goal image, predicts the future hand and object configurations. We combine this with a translation module that learns a plan-conditioned robot manipulation policy, and allows following humans plans for generic manipulation tasks in a zero-shot manner with no deployment-time training. Importantly, while the plan predictor can leverage large-scale human videos for learning, the translation module only requires a small amount of in-domain data, and can generalize to tasks not seen during training. We show that our learned system can perform over 16 manipulation skills that generalize to 40 objects, encompassing 100 real-world tasks for table-top manipulation and diverse in-the-wild manipulation. https://homangab.github.io/hopman/
Diffusion-Guided Reconstruction of Everyday Hand-Object Interaction Clips
Sep 11, 2023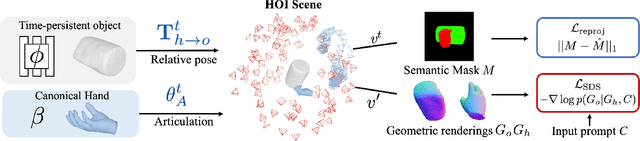
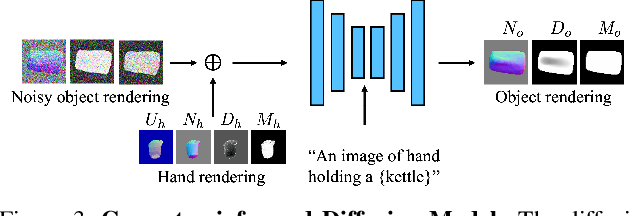

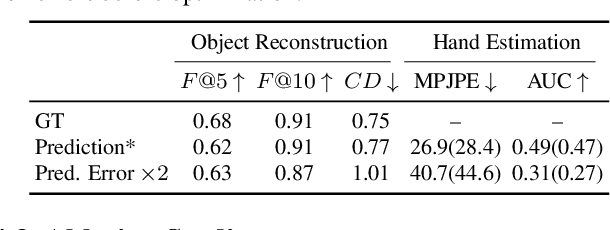
We tackle the task of reconstructing hand-object interactions from short video clips. Given an input video, our approach casts 3D inference as a per-video optimization and recovers a neural 3D representation of the object shape, as well as the time-varying motion and hand articulation. While the input video naturally provides some multi-view cues to guide 3D inference, these are insufficient on their own due to occlusions and limited viewpoint variations. To obtain accurate 3D, we augment the multi-view signals with generic data-driven priors to guide reconstruction. Specifically, we learn a diffusion network to model the conditional distribution of (geometric) renderings of objects conditioned on hand configuration and category label, and leverage it as a prior to guide the novel-view renderings of the reconstructed scene. We empirically evaluate our approach on egocentric videos across 6 object categories, and observe significant improvements over prior single-view and multi-view methods. Finally, we demonstrate our system's ability to reconstruct arbitrary clips from YouTube, showing both 1st and 3rd person interactions.
RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking
Sep 05, 2023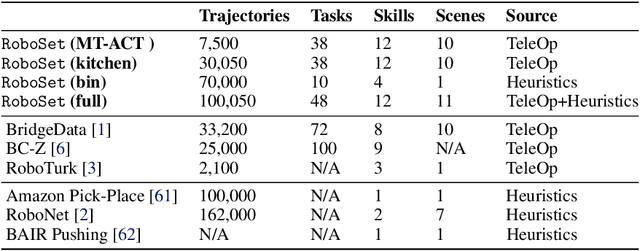
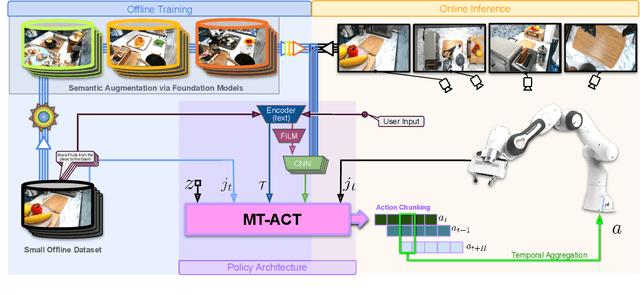
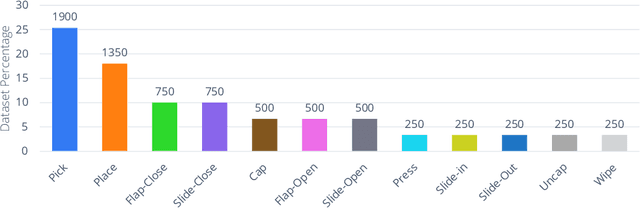
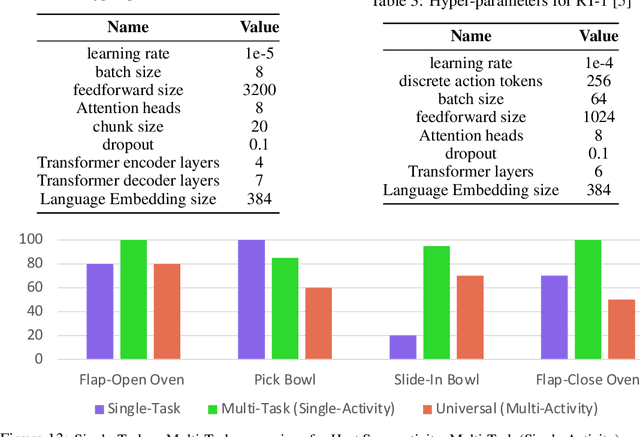
The grand aim of having a single robot that can manipulate arbitrary objects in diverse settings is at odds with the paucity of robotics datasets. Acquiring and growing such datasets is strenuous due to manual efforts, operational costs, and safety challenges. A path toward such an universal agent would require a structured framework capable of wide generalization but trained within a reasonable data budget. In this paper, we develop an efficient system (RoboAgent) for training universal agents capable of multi-task manipulation skills using (a) semantic augmentations that can rapidly multiply existing datasets and (b) action representations that can extract performant policies with small yet diverse multi-modal datasets without overfitting. In addition, reliable task conditioning and an expressive policy architecture enable our agent to exhibit a diverse repertoire of skills in novel situations specified using language commands. Using merely 7500 demonstrations, we are able to train a single agent capable of 12 unique skills, and demonstrate its generalization over 38 tasks spread across common daily activities in diverse kitchen scenes. On average, RoboAgent outperforms prior methods by over 40% in unseen situations while being more sample efficient and being amenable to capability improvements and extensions through fine-tuning. Videos at https://robopen.github.io/
Visual Affordance Prediction for Guiding Robot Exploration
May 28, 2023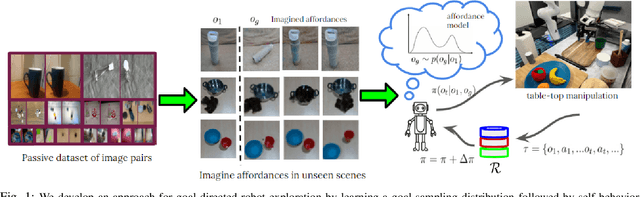
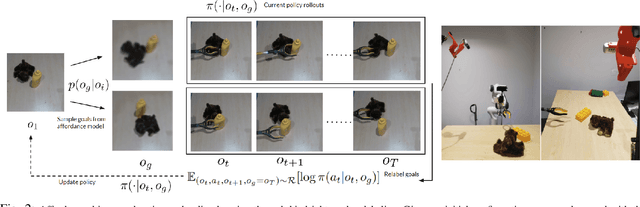
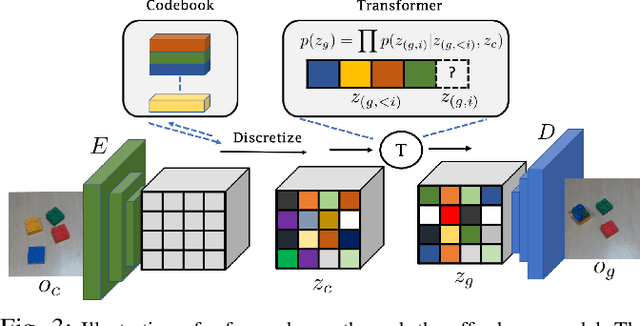

Motivated by the intuitive understanding humans have about the space of possible interactions, and the ease with which they can generalize this understanding to previously unseen scenes, we develop an approach for learning visual affordances for guiding robot exploration. Given an input image of a scene, we infer a distribution over plausible future states that can be achieved via interactions with it. We use a Transformer-based model to learn a conditional distribution in the latent embedding space of a VQ-VAE and show that these models can be trained using large-scale and diverse passive data, and that the learned models exhibit compositional generalization to diverse objects beyond the training distribution. We show how the trained affordance model can be used for guiding exploration by acting as a goal-sampling distribution, during visual goal-conditioned policy learning in robotic manipulation.
RelPose++: Recovering 6D Poses from Sparse-view Observations
May 08, 2023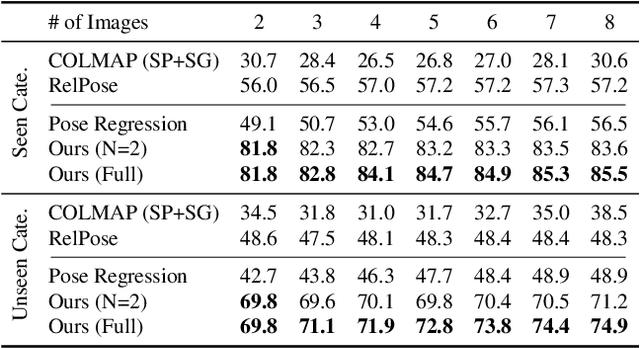
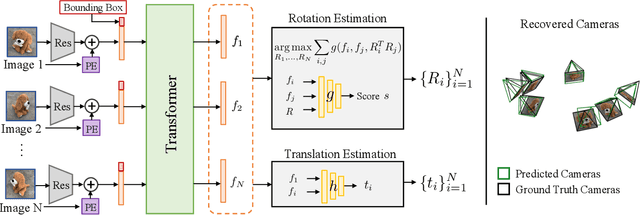
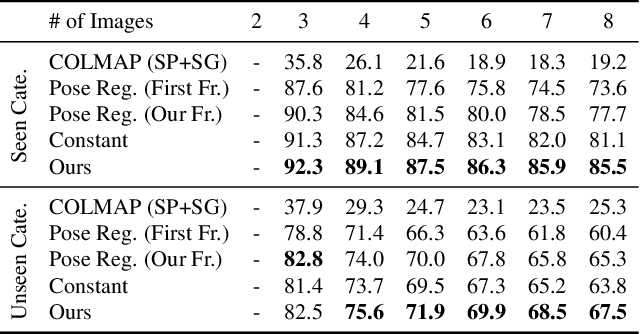
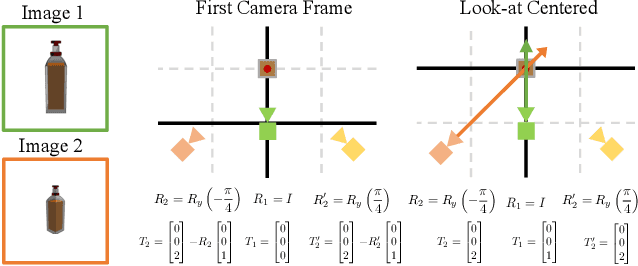
We address the task of estimating 6D camera poses from sparse-view image sets (2-8 images). This task is a vital pre-processing stage for nearly all contemporary (neural) reconstruction algorithms but remains challenging given sparse views, especially for objects with visual symmetries and texture-less surfaces. We build on the recent RelPose framework which learns a network that infers distributions over relative rotations over image pairs. We extend this approach in two key ways; first, we use attentional transformer layers to process multiple images jointly, since additional views of an object may resolve ambiguous symmetries in any given image pair (such as the handle of a mug that becomes visible in a third view). Second, we augment this network to also report camera translations by defining an appropriate coordinate system that decouples the ambiguity in rotation estimation from translation prediction. Our final system results in large improvements in 6D pose prediction over prior art on both seen and unseen object categories and also enables pose estimation and 3D reconstruction for in-the-wild objects.