 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJean-Baptiste Mouret
Parametric-Task MAP-Elites
Feb 02, 2024
Optimizing a set of functions simultaneously by leveraging their similarity is called multi-task optimization. Current black-box multi-task algorithms only solve a finite set of tasks, even when the tasks originate from a continuous space. In this paper, we introduce Parametric-task MAP-Elites (PT-ME), a novel black-box algorithm to solve continuous multi-task optimization problems. This algorithm (1) solves a new task at each iteration, effectively covering the continuous space, and (2) exploits a new variation operator based on local linear regression. The resulting dataset of solutions makes it possible to create a function that maps any task parameter to its optimal solution. We show on two parametric-task toy problems and a more realistic and challenging robotic problem in simulation that PT-ME outperforms all baselines, including the deep reinforcement learning algorithm PPO.
Multi-Contact Whole Body Force Control for Position-Controlled Robots
Jan 16, 2024Many humanoid and multi-legged robots are controlled in positions rather than in torques, preventing direct control of contact forces, and hampering their ability to create multiple contacts to enhance their balance, such as placing a hand on a wall or a handrail. This paper introduces the SEIKO (Sequential Equilibrium Inverse Kinematic Optimization) pipeline, drawing inspiration from flexibility models used in serial elastic actuators to indirectly control contact forces on traditional position-controlled robots. SEIKO formulates whole-body retargeting from Cartesian commands and admittance control using two quadratic programs solved in real time. We validated our pipeline with experiments on the real, full-scale humanoid robot Talos in various multicontact scenarios, including pushing tasks, far-reaching tasks, stair climbing, and stepping on sloped surfaces. This work opens the possibility of stable, contact-rich behaviors while getting around many of the challenges of torque-controlled robots. Code and videos are available at https://hucebot.github.io/seiko_controller_website/ .
Feasibility Retargeting for Multi-contact Teleoperation and Physical Interaction
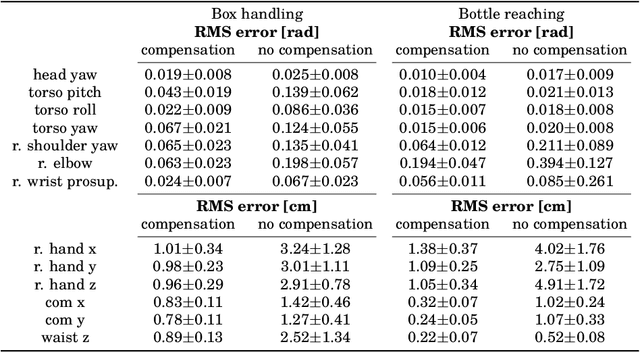
Aug 07, 2023This short paper outlines two recent works on multi-contact teleoperation and the development of the SEIKO (Sequential Equilibrium Inverse Kinematic Optimization) framework. SEIKO adapts commands from the operator in real-time and ensures that the reference configuration sent to the underlying controller is feasible. Additionally, an admittance scheme is used to implement physical interaction, which is then combined with the operator's command and retargeted. SEIKO has been applied in simulations on various robots, including humanoid and quadruped robots designed for loco-manipulation. Furthermore, SEIKO has been tested on real hardware for bimanual heavy object carrying tasks.
Data-efficient learning of object-centric grasp preferences
Mar 01, 2022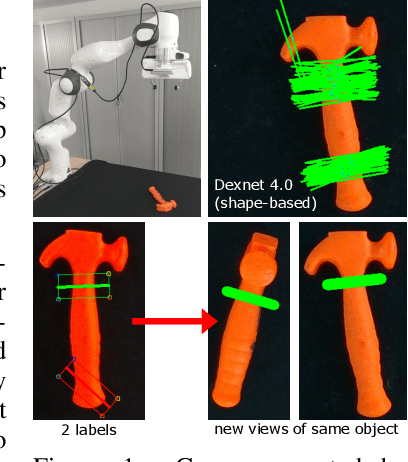

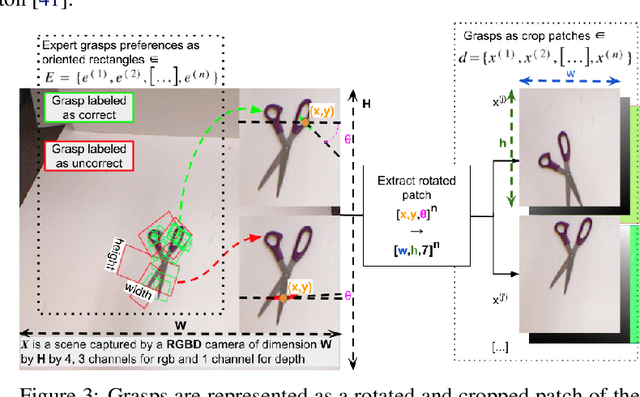

Grasping made impressive progress during the last few years thanks to deep learning. However, there are many objects for which it is not possible to choose a grasp by only looking at an RGB-D image, might it be for physical reasons (e.g., a hammer with uneven mass distribution) or task constraints (e.g., food that should not be spoiled). In such situations, the preferences of experts need to be taken into account. In this paper, we introduce a data-efficient grasping pipeline (Latent Space GP Selector -- LGPS) that learns grasp preferences with only a few labels per object (typically 1 to 4) and generalizes to new views of this object. Our pipeline is based on learning a latent space of grasps with a dataset generated with any state-of-the-art grasp generator (e.g., Dex-Net). This latent space is then used as a low-dimensional input for a Gaussian process classifier that selects the preferred grasp among those proposed by the generator. The results show that our method outperforms both GR-ConvNet and GG-CNN (two state-of-the-art methods that are also based on labeled grasps) on the Cornell dataset, especially when only a few labels are used: only 80 labels are enough to correctly choose 80% of the grasps (885 scenes, 244 objects). Results are similar on our dataset (91 scenes, 28 objects).
First do not fall: learning to exploit the environment with a damaged humanoid robot
Mar 01, 2022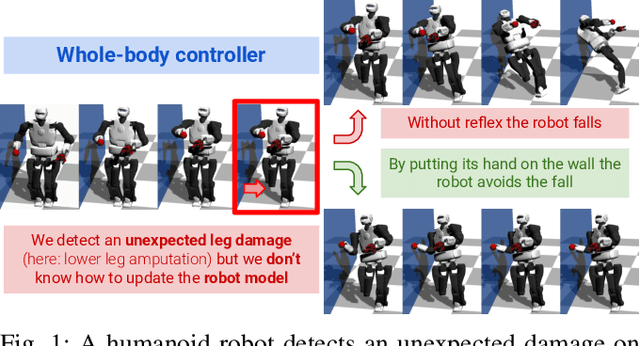
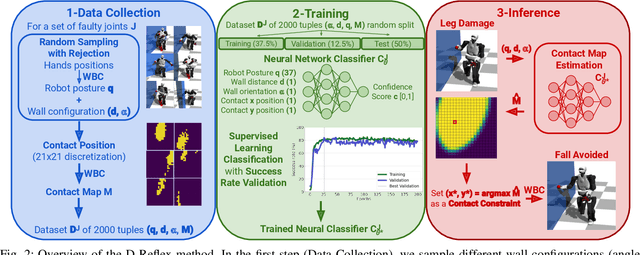
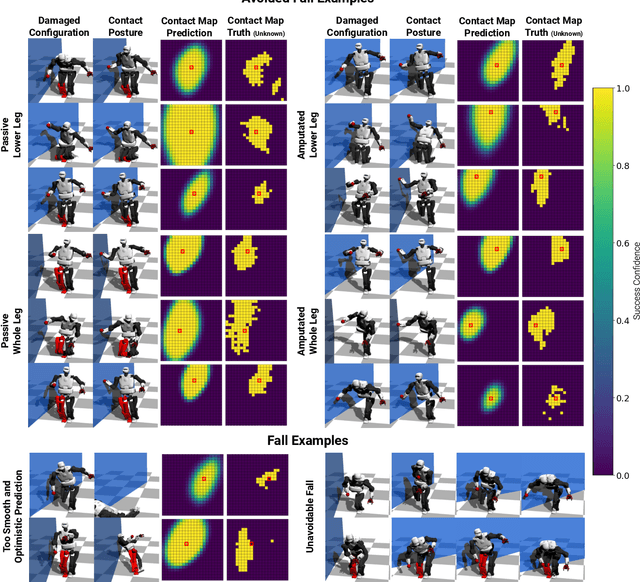
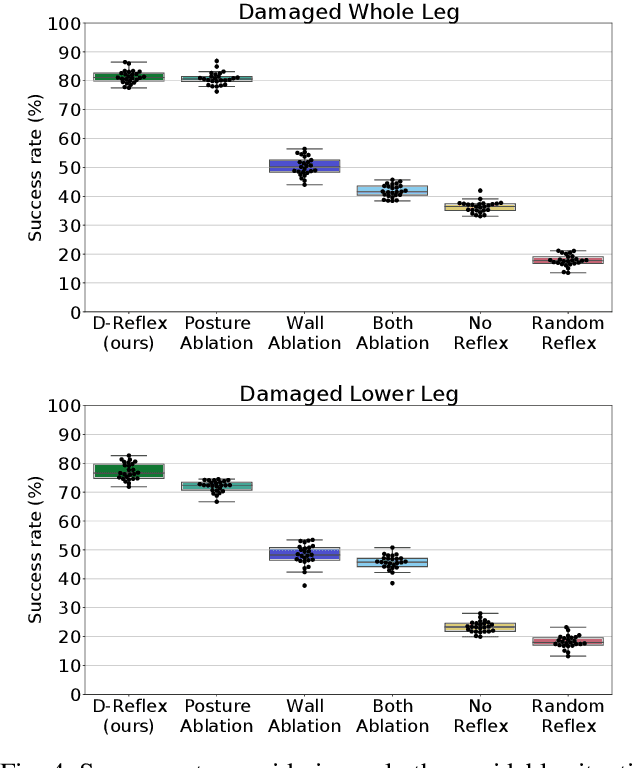
Humanoid robots could replace humans in hazardous situations but most of such situations are equally dangerous for them, which means that they have a high chance of being damaged and fall. We hypothesize that humanoid robots would be mostly used in buildings, which makes them likely to be close to a wall. To avoid a fall, they can therefore lean on the closest wall, like a human would do, provided that they find in a few milliseconds where to put the hand(s). This article introduces a method, called D-Reflex, that learns a neural network that chooses this contact position given the wall orientation, the wall distance, and the posture of the robot. This contact position is then used by a whole-body controller to reach a stable posture. We show that D-Reflex allows a simulated TALOS robot (1.75m, 100kg, 30 degrees of freedom) to avoid more than 75% of the avoidable falls.
An Online Data-Driven Emergency-Response Method for Autonomous Agents in Unforeseen Situations
Dec 17, 2021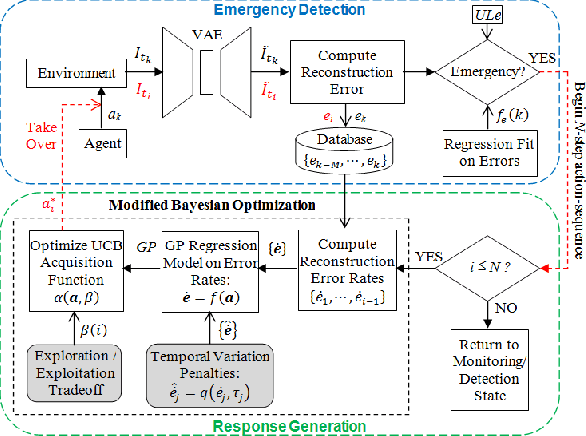
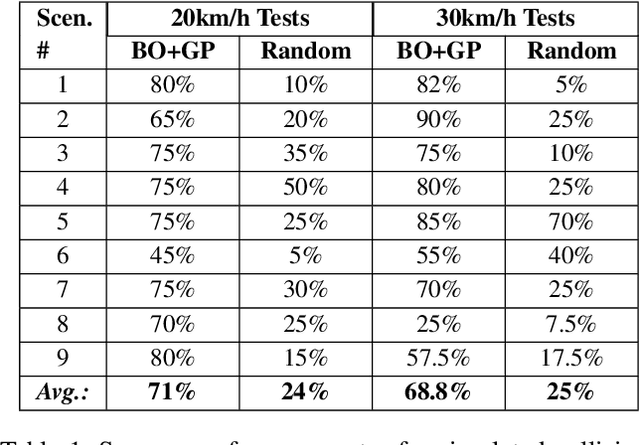

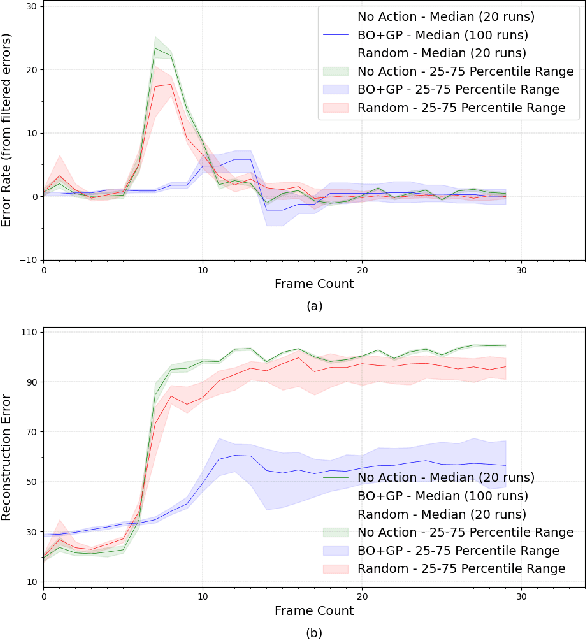
Reinforcement learning agents perform well when presented with inputs within the distribution of those encountered during training. However, they are unable to respond effectively when faced with novel, out-of-distribution events, until they have undergone additional training. This paper presents an online, data-driven, emergency-response method that aims to provide autonomous agents the ability to react to unexpected situations that are very different from those it has been trained or designed to address. In such situations, learned policies cannot be expected to perform appropriately since the observations obtained in these novel situations would fall outside the distribution of inputs that the agent has been optimized to handle. The proposed approach devises a customized response to the unforeseen situation sequentially, by selecting actions that minimize the rate of increase of the reconstruction error from a variational auto-encoder. This optimization is achieved online in a data-efficient manner (on the order of 30 data-points) using a modified Bayesian optimization procedure. We demonstrate the potential of this approach in a simulated 3D car driving scenario, in which the agent devises a response in under 2 seconds to avoid collisions with objects it has not seen during training.
Prescient teleoperation of humanoid robots
Jul 12, 2021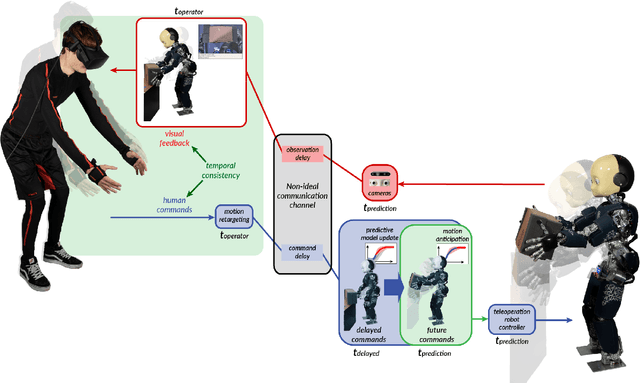


Humanoid robots could be versatile and intuitive human avatars that operate remotely in inaccessible places: the robot could reproduce in the remote location the movements of an operator equipped with a wearable motion capture device while sending visual feedback to the operator. While substantial progress has been made on transferring ("retargeting") human motions to humanoid robots, a major problem preventing the deployment of such systems in real applications is the presence of communication delays between the human input and the feedback from the robot: even a few hundred milliseconds of delay can irreversibly disturb the operator, let alone a few seconds. To overcome these delays, we introduce a system in which a humanoid robot executes commands before it actually receives them, so that the visual feedback appears to be synchronized to the operator, whereas the robot executed the commands in the past. To do so, the robot continuously predicts future commands by querying a machine learning model that is trained on past trajectories and conditioned on the last received commands. In our experiments, an operator was able to successfully control a humanoid robot (32 degrees of freedom) with stochastic delays up to 2 seconds in several whole-body manipulation tasks, including reaching different targets, picking up, and placing a box at distinct locations.
Evolving the Behavior of Machines: From Micro to Macroevolution
Dec 21, 2020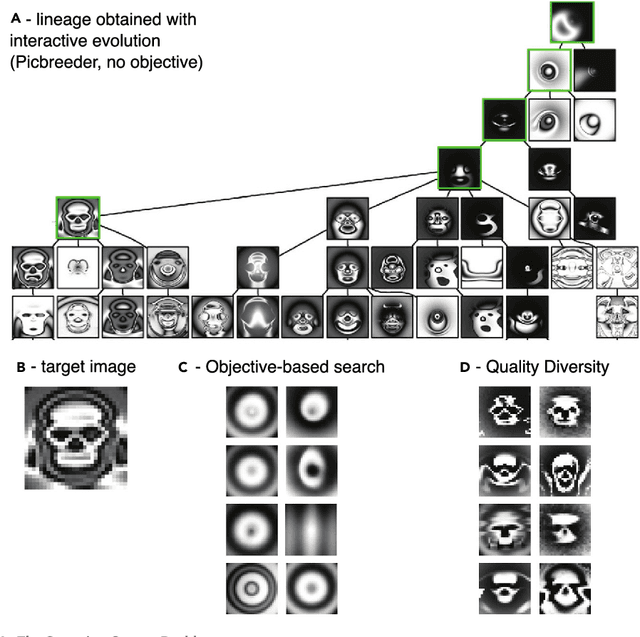
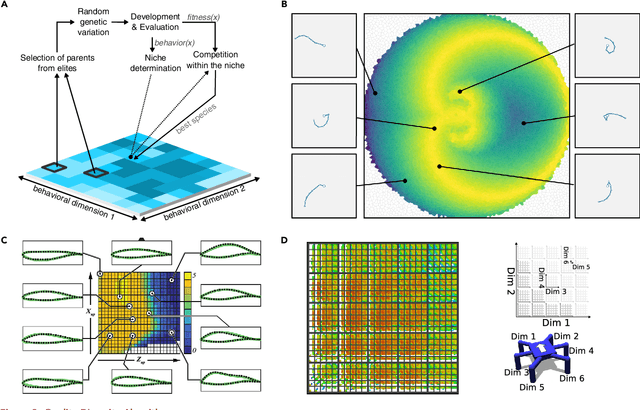
Evolution gave rise to creatures that are arguably more sophisticated than the greatest human-designed systems. This feat has inspired computer scientists since the advent of computing and led to optimization tools that can evolve complex neural networks for machines -- an approach known as "neuroevolution". After a few successes in designing evolvable representations for high-dimensional artifacts, the field has been recently revitalized by going beyond optimization: to many, the wonder of evolution is less in the perfect optimization of each species than in the creativity of such a simple iterative process, that is, in the diversity of species. This modern view of artificial evolution is moving the field away from microevolution, following a fitness gradient in a niche, to macroevolution, filling many niches with highly different species. It already opened promising applications, like evolving gait repertoires, video game levels for different tastes, and diverse designs for aerodynamic bikes.
Quality-Diversity Optimization: a novel branch of stochastic optimization
Dec 17, 2020


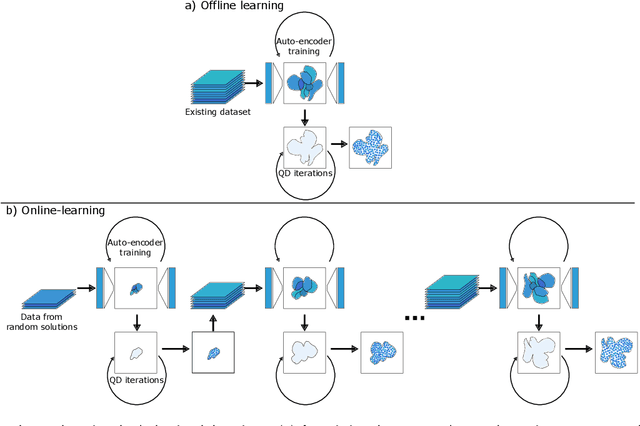
Traditional optimization algorithms search for a single global optimum that maximizes (or minimizes) the objective function. Multimodal optimization algorithms search for the highest peaks in the search space that can be more than one. Quality-Diversity algorithms are a recent addition to the evolutionary computation toolbox that do not only search for a single set of local optima, but instead try to illuminate the search space. In effect, they provide a holistic view of how high-performing solutions are distributed throughout a search space. The main differences with multimodal optimization algorithms are that (1) Quality-Diversity typically works in the behavioral space (or feature space), and not in the genotypic (or parameter) space, and (2) Quality-Diversity attempts to fill the whole behavior space, even if the niche is not a peak in the fitness landscape. In this chapter, we provide a gentle introduction to Quality-Diversity optimization, discuss the main representative algorithms, and the main current topics under consideration in the community. Throughout the chapter, we also discuss several successful applications of Quality-Diversity algorithms, including deep learning, robotics, and reinforcement learning.
Fast Online Adaptation in Robotics through Meta-Learning Embeddings of Simulated Priors
Mar 10, 2020
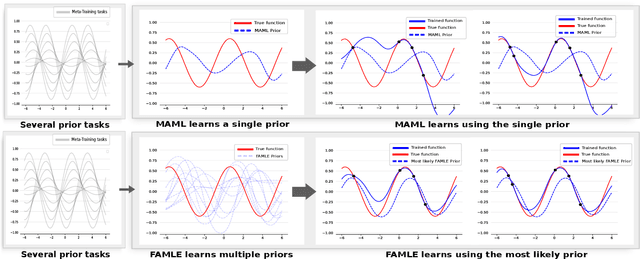
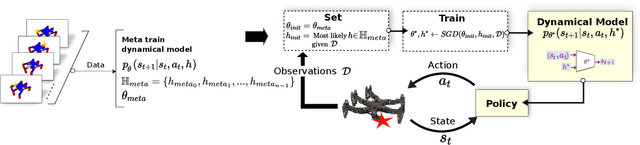

Meta-learning algorithms can accelerate the model-based reinforcement learning (MBRL) algorithms by finding an initial set of parameters for the dynamical model such that the model can be trained to match the actual dynamics of the system with only a few data-points. However, in the real world, a robot might encounter any situation starting from motor failures to finding itself in a rocky terrain where the dynamics of the robot can be significantly different from one another. In this paper, first, we show that when meta-training situations (the prior situations) have such diverse dynamics, using a single set of meta-trained parameters as a starting point still requires a large number of observations from the real system to learn a useful model of the dynamics. Second, we propose an algorithm called FAMLE that mitigates this limitation by meta-training several initial starting points (i.e., initial parameters) for training the model and allows the robot to select the most suitable starting point to adapt the model to the current situation with only a few gradient steps. We compare FAMLE to MBRL, MBRL with a meta-trained model with MAML, and model-free policy search algorithm PPO for various simulated and real robotic tasks, and show that FAMLE allows the robots to adapt to novel damages in significantly fewer time-steps than the baselines.