 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJesse Thomason
TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models
Mar 25, 2024

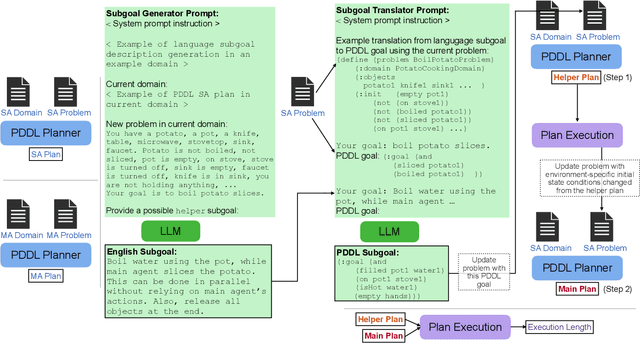


Classical planning formulations like the Planning Domain Definition Language (PDDL) admit action sequences guaranteed to achieve a goal state given an initial state if any are possible. However, reasoning problems defined in PDDL do not capture temporal aspects of action taking, for example that two agents in the domain can execute an action simultaneously if postconditions of each do not interfere with preconditions of the other. A human expert can decompose a goal into largely independent constituent parts and assign each agent to one of these subgoals to take advantage of simultaneous actions for faster execution of plan steps, each using only single agent planning. By contrast, large language models (LLMs) used for directly inferring plan steps do not guarantee execution success, but do leverage commonsense reasoning to assemble action sequences. We combine the strengths of classical planning and LLMs by approximating human intuitions for two-agent planning goal decomposition. We demonstrate that LLM-based goal decomposition leads to faster planning times than solving multi-agent PDDL problems directly while simultaneously achieving fewer plan execution steps than a single agent plan alone and preserving execution success. Additionally, we find that LLM-based approximations of subgoals can achieve similar multi-agent execution steps than those specified by human experts. Website and resources at https://glamor-usc.github.io/twostep
ViSaRL: Visual Reinforcement Learning Guided by Human Saliency
Mar 16, 2024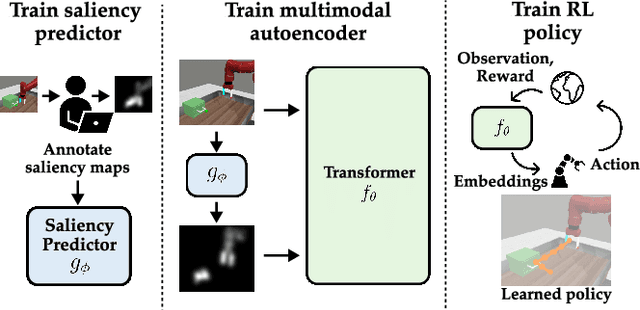

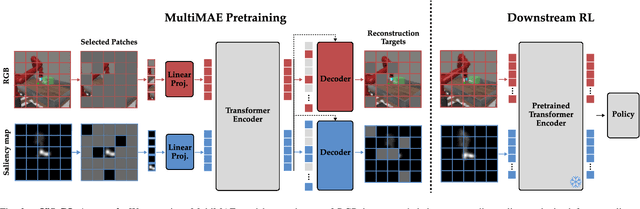
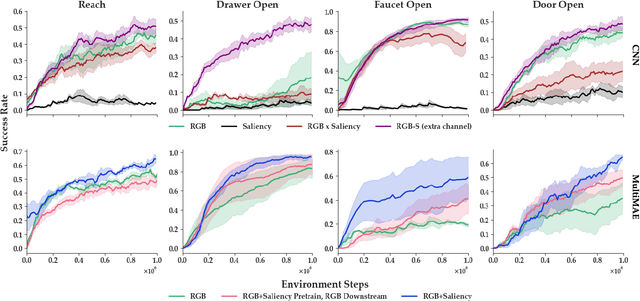
Training robots to perform complex control tasks from high-dimensional pixel input using reinforcement learning (RL) is sample-inefficient, because image observations are comprised primarily of task-irrelevant information. By contrast, humans are able to visually attend to task-relevant objects and areas. Based on this insight, we introduce Visual Saliency-Guided Reinforcement Learning (ViSaRL). Using ViSaRL to learn visual representations significantly improves the success rate, sample efficiency, and generalization of an RL agent on diverse tasks including DeepMind Control benchmark, robot manipulation in simulation and on a real robot. We present approaches for incorporating saliency into both CNN and Transformer-based encoders. We show that visual representations learned using ViSaRL are robust to various sources of visual perturbations including perceptual noise and scene variations. ViSaRL nearly doubles success rate on the real-robot tasks compared to the baseline which does not use saliency.
Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning
Feb 23, 2024Prior work on selective prediction minimizes incorrect predictions from vision-language models (VLMs) by allowing them to abstain from answering when uncertain. However, when deploying a vision-language system with low tolerance for inaccurate predictions, selective prediction may be over-cautious and abstain too frequently, even on many correct predictions. We introduce ReCoVERR, an inference-time algorithm to reduce the over-abstention of a selective vision-language system without decreasing prediction accuracy. When the VLM makes a low-confidence prediction, instead of abstaining ReCoVERR tries to find relevant clues in the image that provide additional evidence for the prediction. ReCoVERR uses an LLM to pose related questions to the VLM, collects high-confidence evidences, and if enough evidence confirms the prediction the system makes a prediction instead of abstaining. ReCoVERR enables two VLMs, BLIP2 and InstructBLIP, to answer up to 20% more questions on the A-OKVQA task than vanilla selective prediction without decreasing system accuracy, thus improving overall system reliability.
WinoViz: Probing Visual Properties of Objects Under Different States
Feb 21, 2024Humans perceive and comprehend different visual properties of an object based on specific contexts. For instance, we know that a banana turns brown ``when it becomes rotten,'' whereas it appears green ``when it is unripe.'' Previous studies on probing visual commonsense knowledge have primarily focused on examining language models' understanding of typical properties (e.g., colors and shapes) of objects. We present WinoViz, a text-only evaluation dataset, consisting of 1,380 examples that probe the reasoning abilities of language models regarding variant visual properties of objects under different contexts or states. Our task is challenging since it requires pragmatic reasoning (finding intended meanings) and visual knowledge reasoning. We also present multi-hop data, a more challenging version of our data, which requires multi-step reasoning chains to solve our task. In our experimental analysis, our findings are: a) Large language models such as GPT-4 demonstrate effective performance, but when it comes to multi-hop data, their performance is significantly degraded. b) Large models perform well on pragmatic reasoning, but visual knowledge reasoning is a bottleneck in our task. c) Vision-language models outperform their language-model counterparts. d) A model with machine-generated images performs poorly in our task. This is due to the poor quality of the generated images.
THE COLOSSEUM: A Benchmark for Evaluating Generalization for Robotic Manipulation
Feb 13, 2024To realize effective large-scale, real-world robotic applications, we must evaluate how well our robot policies adapt to changes in environmental conditions. Unfortunately, a majority of studies evaluate robot performance in environments closely resembling or even identical to the training setup. We present THE COLOSSEUM, a novel simulation benchmark, with 20 diverse manipulation tasks, that enables systematical evaluation of models across 12 axes of environmental perturbations. These perturbations include changes in color, texture, and size of objects, table-tops, and backgrounds; we also vary lighting, distractors, and camera pose. Using THE COLOSSEUM, we compare 4 state-of-the-art manipulation models to reveal that their success rate degrades between 30-50% across these perturbation factors. When multiple perturbations are applied in unison, the success rate degrades $\geq$75%. We identify that changing the number of distractor objects, target object color, or lighting conditions are the perturbations that reduce model performance the most. To verify the ecological validity of our results, we show that our results in simulation are correlated ($\bar{R}^2 = 0.614$) to similar perturbations in real-world experiments. We open source code for others to use THE COLOSSEUM, and also release code to 3D print the objects used to replicate the real-world perturbations. Ultimately, we hope that THE COLOSSEUM will serve as a benchmark to identify modeling decisions that systematically improve generalization for manipulation. See https://robot-colosseum.github.io/ for more details.
Does VLN Pretraining Work with Nonsensical or Irrelevant Instructions?
Dec 02, 2023Data augmentation via back-translation is common when pretraining Vision-and-Language Navigation (VLN) models, even though the generated instructions are noisy. But: does that noise matter? We find that nonsensical or irrelevant language instructions during pretraining can have little effect on downstream performance for both HAMT and VLN-BERT on R2R, and is still better than only using clean, human data. To underscore these results, we concoct an efficient augmentation method, Unigram + Object, which generates nonsensical instructions that nonetheless improve downstream performance. Our findings suggest that what matters for VLN R2R pretraining is the quantity of visual trajectories, not the quality of instructions.
Efficient End-to-End Visual Document Understanding with Rationale Distillation
Nov 16, 2023Understanding visually situated language requires recognizing text and visual elements, and interpreting complex layouts. State-of-the-art methods commonly use specialized pre-processing tools, such as optical character recognition (OCR) systems, that map document image inputs to extracted information in the space of textual tokens, and sometimes also employ large language models (LLMs) to reason in text token space. However, the gains from external tools and LLMs come at the cost of increased computational and engineering complexity. In this paper, we ask whether small pretrained image-to-text models can learn selective text or layout recognition and reasoning as an intermediate inference step in an end-to-end model for pixel-level visual language understanding. We incorporate the outputs of such OCR tools, LLMs, and larger multimodal models as intermediate ``rationales'' on training data, and train a small student model to predict both rationales and answers for input questions based on those training examples. A student model based on Pix2Struct (282M parameters) achieves consistent improvements on three visual document understanding benchmarks representing infographics, scanned documents, and figures, with improvements of more than 4\% absolute over a comparable Pix2Struct model that predicts answers directly.
Do Localization Methods Actually Localize Memorized Data in LLMs?
Nov 15, 2023Large language models (LLMs) can memorize many pretrained sequences verbatim. This paper studies if we can locate a small set of neurons in LLMs responsible for memorizing a given sequence. While the concept of localization is often mentioned in prior work, methods for localization have never been systematically and directly evaluated; we address this with two benchmarking approaches. In our INJ Benchmark, we actively inject a piece of new information into a small subset of LLM weights and measure whether localization methods can identify these "ground truth" weights. In the DEL Benchmark, we study localization of pretrained data that LLMs have already memorized; while this setting lacks ground truth, we can still evaluate localization by measuring whether dropping out located neurons erases a memorized sequence from the model. We evaluate five localization methods on our two benchmarks, and both show similar rankings. All methods exhibit promising localization ability, especially for pruning-based methods, though the neurons they identify are not necessarily specific to a single memorized sequence.
Comparative Multi-View Language Grounding
Nov 14, 2023In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes
Sep 30, 2023
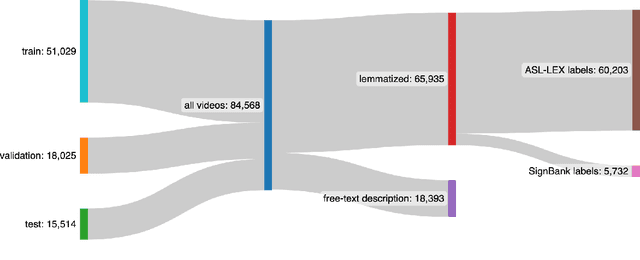
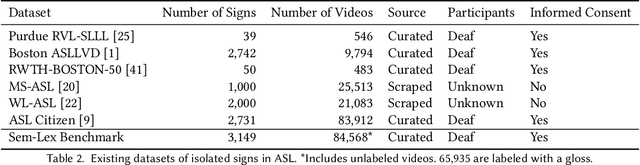

Sign language recognition and translation technologies have the potential to increase access and inclusion of deaf signing communities, but research progress is bottlenecked by a lack of representative data. We introduce a new resource for American Sign Language (ASL) modeling, the Sem-Lex Benchmark. The Benchmark is the current largest of its kind, consisting of over 84k videos of isolated sign productions from deaf ASL signers who gave informed consent and received compensation. Human experts aligned these videos with other sign language resources including ASL-LEX, SignBank, and ASL Citizen, enabling useful expansions for sign and phonological feature recognition. We present a suite of experiments which make use of the linguistic information in ASL-LEX, evaluating the practicality and fairness of the Sem-Lex Benchmark for isolated sign recognition (ISR). We use an SL-GCN model to show that the phonological features are recognizable with 85% accuracy, and that they are effective as an auxiliary target to ISR. Learning to recognize phonological features alongside gloss results in a 6% improvement for few-shot ISR accuracy and a 2% improvement for ISR accuracy overall. Instructions for downloading the data can be found at https://github.com/leekezar/SemLex.