 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJessica Ficler
Controlling Linguistic Style Aspects in Neural Language Generation
Jul 09, 2017
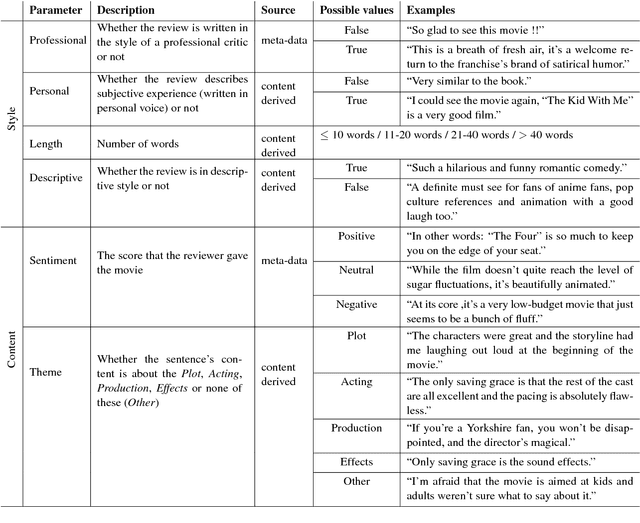
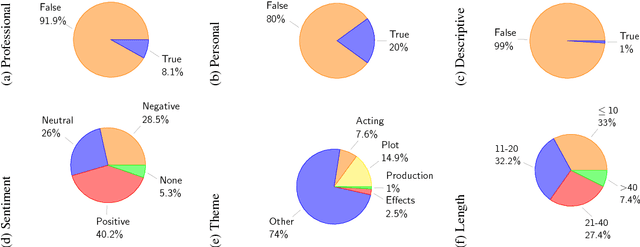

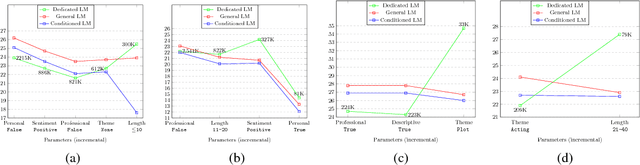
Most work on neural natural language generation (NNLG) focus on controlling the content of the generated text. We experiment with controlling several stylistic aspects of the generated text, in addition to its content. The method is based on conditioned RNN language model, where the desired content as well as the stylistic parameters serve as conditioning contexts. We demonstrate the approach on the movie reviews domain and show that it is successful in generating coherent sentences corresponding to the required linguistic style and content.
Improving a Strong Neural Parser with Conjunction-Specific Features
Feb 22, 2017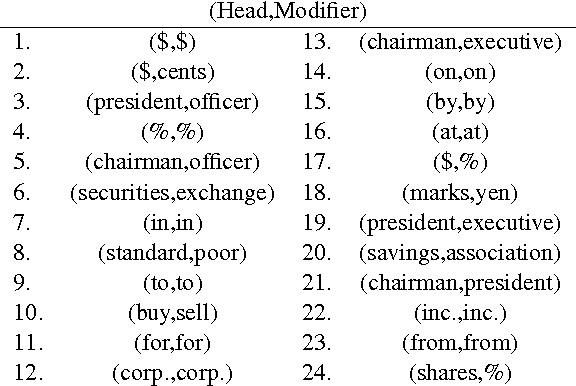



While dependency parsers reach very high overall accuracy, some dependency relations are much harder than others. In particular, dependency parsers perform poorly in coordination construction (i.e., correctly attaching the "conj" relation). We extend a state-of-the-art dependency parser with conjunction-specific features, focusing on the similarity between the conjuncts head words. Training the extended parser yields an improvement in "conj" attachment as well as in overall dependency parsing accuracy on the Stanford dependency conversion of the Penn TreeBank.
A Neural Network for Coordination Boundary Prediction
Oct 13, 2016
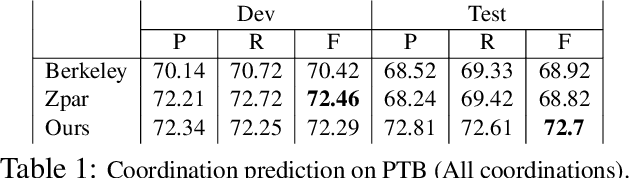

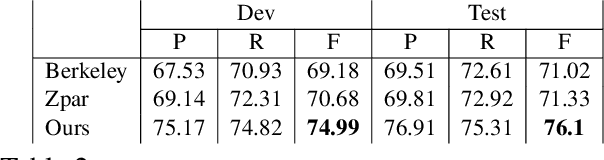
We propose a neural-network based model for coordination boundary prediction. The network is designed to incorporate two signals: the similarity between conjuncts and the observation that replacing the whole coordination phrase with a conjunct tends to produce a coherent sentences. The modeling makes use of several LSTM networks. The model is trained solely on conjunction annotations in a Treebank, without using external resources. We show improvements on predicting coordination boundaries on the PTB compared to two state-of-the-art parsers; as well as improvement over previous coordination boundary prediction systems on the Genia corpus.
Coordination Annotation Extension in the Penn Tree Bank
Jun 08, 2016


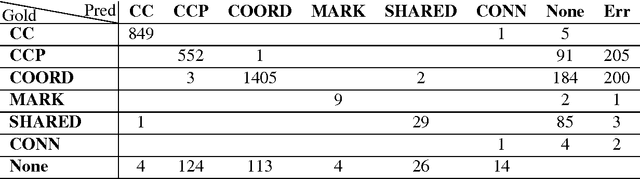
Coordination is an important and common syntactic construction which is not handled well by state of the art parsers. Coordinations in the Penn Treebank are missing internal structure in many cases, do not include explicit marking of the conjuncts and contain various errors and inconsistencies. In this work, we initiated manual annotation process for solving these issues. We identify the different elements in a coordination phrase and label each element with its function. We add phrase boundaries when these are missing, unify inconsistencies, and fix errors. The outcome is an extension of the PTB that includes consistent and detailed structures for coordinations. We make the coordination annotation publicly available, in hope that they will facilitate further research into coordination disambiguation.
Improved Parsing for Argument-Clusters Coordination
Jun 01, 2016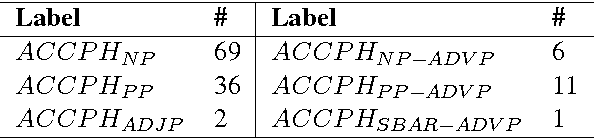
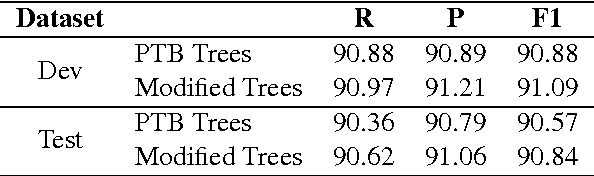

Syntactic parsers perform poorly in prediction of Argument-Cluster Coordination (ACC). We change the PTB representation of ACC to be more suitable for learning by a statistical PCFG parser, affecting 125 trees in the training set. Training on the modified trees yields a slight improvement in EVALB scores on sections 22 and 23. The main evaluation is on a corpus of 4th grade science exams, in which ACC structures are prevalent. On this corpus, we obtain an impressive x2.7 improvement in recovering ACC structures compared to a parser trained on the original PTB trees.
Getting More Out Of Syntax with PropS
Mar 04, 2016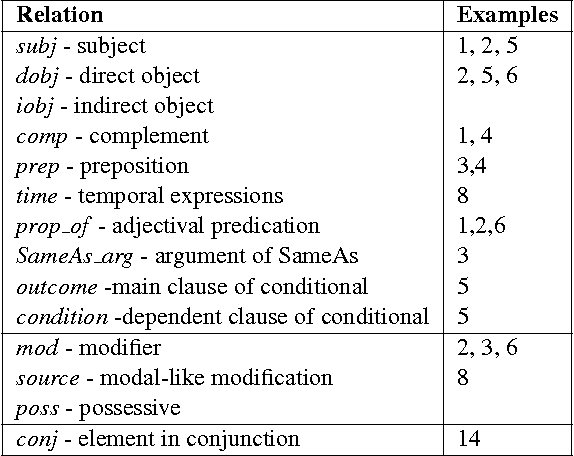
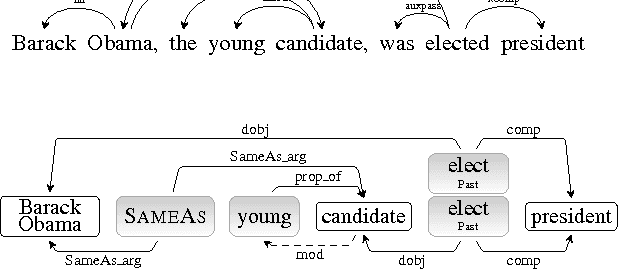
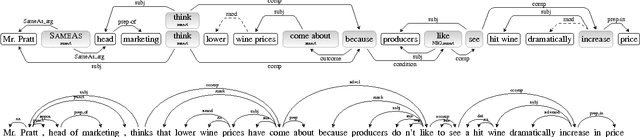
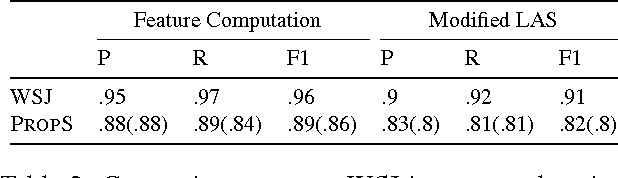
Semantic NLP applications often rely on dependency trees to recognize major elements of the proposition structure of sentences. Yet, while much semantic structure is indeed expressed by syntax, many phenomena are not easily read out of dependency trees, often leading to further ad-hoc heuristic post-processing or to information loss. To directly address the needs of semantic applications, we present PropS -- an output representation designed to explicitly and uniformly express much of the proposition structure which is implied from syntax, and an associated tool for extracting it from dependency trees.