 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiadong Zhang
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023
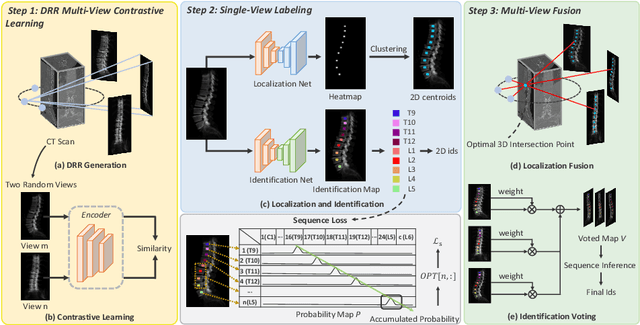
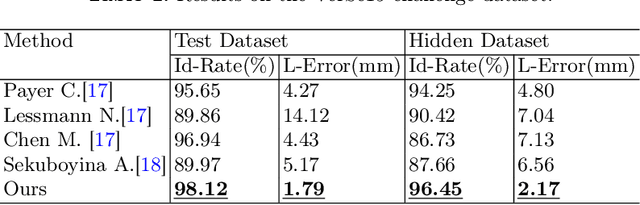
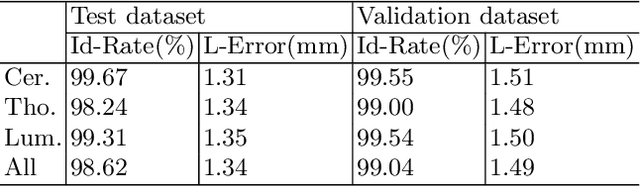
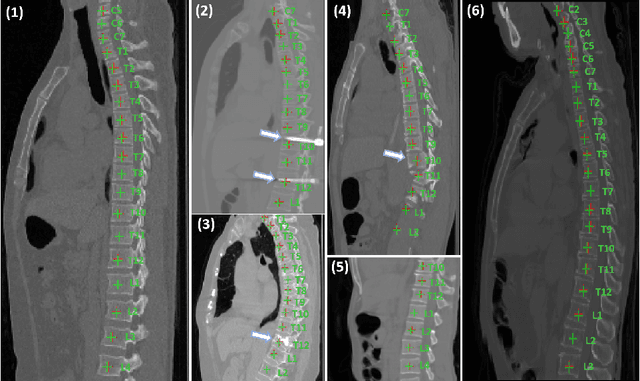
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.
Photoacoustic digital brain: numerical modelling and image reconstruction via deep learning
Sep 19, 2021



Photoacoustic tomography (PAT) is a newly developed medical imaging modality, which combines the advantages of pure optical imaging and ultrasound imaging, owning both high optical contrast and deep penetration depth. Very recently, PAT is studied in human brain imaging. Nevertheless, while ultrasound waves are passing through the human skull tissues, the strong acoustic attenuation and aberration will happen, which causes photoacoustic signals' distortion. In this work, we use 10 magnetic resonance angiography (MRA) human brain volumes, and manually segment them to obtain the 2D human brain numerical phantoms for PAT. The numerical phantoms contain six kinds of tissues which are scalp, skull, white matter, gray matter, blood vessel and cerebral cortex. For every numerical phantom, optical properties are assigned to every kind of tissues. Then, Monte-Carlo based optical simulation is deployed to obtain the photoacoustic initial pressure. Then, we made two k-wave simulation cases: one takes inhomogeneous medium and uneven sound velocity into consideration, and the other not. Then we use the sensor data of the former one as the input of U-net, and the sensor data of the latter one as the output of U-net to train the network. We randomly choose 7 human brain PA sinograms as the training dataset and 3 human brain PA sinograms as the testing set. The testing result shows that our method could correct the skull acoustic aberration and obtain the blood vessel distribution inside the human brain satisfactorily.
SO-SLAM: Semantic Object SLAM with Scale Proportional and Symmetrical Texture Constraints
Sep 10, 2021



Object SLAM introduces the concept of objects into Simultaneous Localization and Mapping (SLAM) and helps understand indoor scenes for mobile robots and object-level interactive applications. The state-of-art object SLAM systems face challenges such as partial observations, occlusions, unobservable problems, limiting the mapping accuracy and robustness. This paper proposes a novel monocular Semantic Object SLAM (SO-SLAM) system that addresses the introduction of object spatial constraints. We explore three representative spatial constraints, including scale proportional constraint, symmetrical texture constraint and plane supporting constraint. Based on these semantic constraints, we propose two new methods - a more robust object initialization method and an orientation fine optimization method. We have verified the performance of the algorithm on the public datasets and an author-recorded mobile robot dataset and achieved a significant improvement on mapping effects. We will release the code here: https://github.com/XunshanMan/SoSLAM.