 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNizhuan Wang
Multi-View Vertebra Localization and Identification from CT Images
Jul 24, 2023
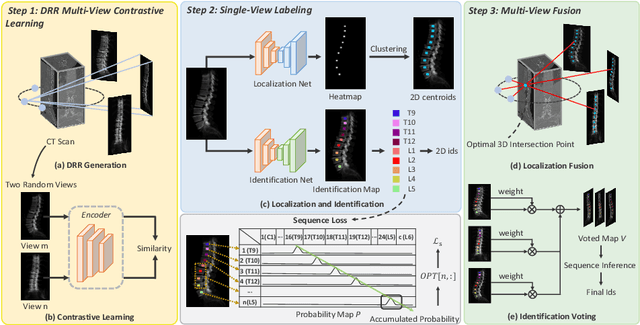
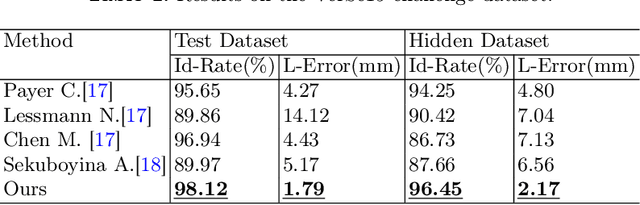
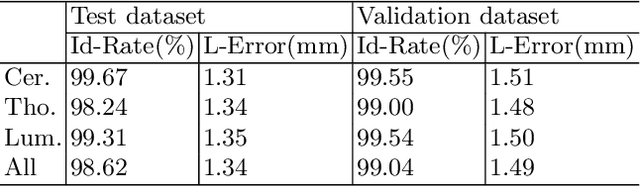
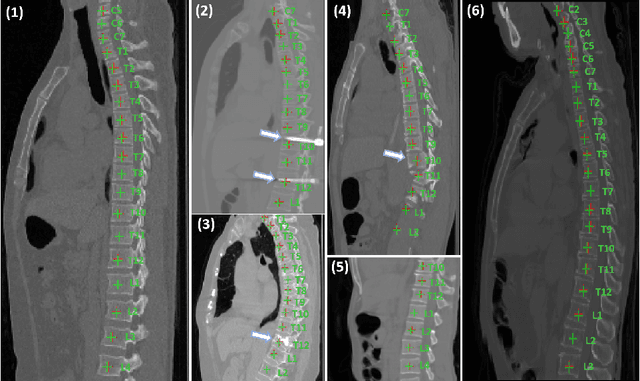
Accurately localizing and identifying vertebrae from CT images is crucial for various clinical applications. However, most existing efforts are performed on 3D with cropping patch operation, suffering from the large computation costs and limited global information. In this paper, we propose a multi-view vertebra localization and identification from CT images, converting the 3D problem into a 2D localization and identification task on different views. Without the limitation of the 3D cropped patch, our method can learn the multi-view global information naturally. Moreover, to better capture the anatomical structure information from different view perspectives, a multi-view contrastive learning strategy is developed to pre-train the backbone. Additionally, we further propose a Sequence Loss to maintain the sequential structure embedded along the vertebrae. Evaluation results demonstrate that, with only two 2D networks, our method can localize and identify vertebrae in CT images accurately, and outperforms the state-of-the-art methods consistently. Our code is available at https://github.com/ShanghaiTech-IMPACT/Multi-View-Vertebra-Localization-and-Identification-from-CT-Images.
Underwater target detection based on improved YOLOv7
Feb 14, 2023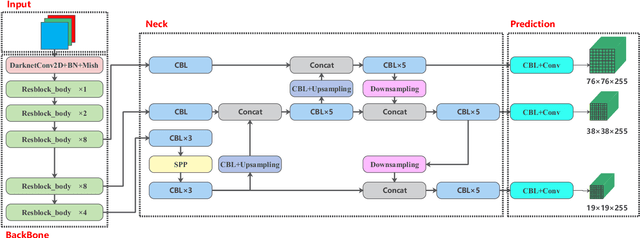
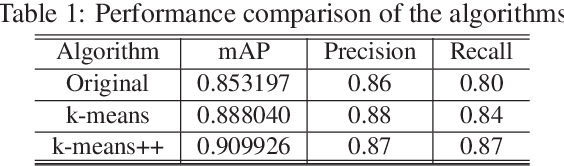
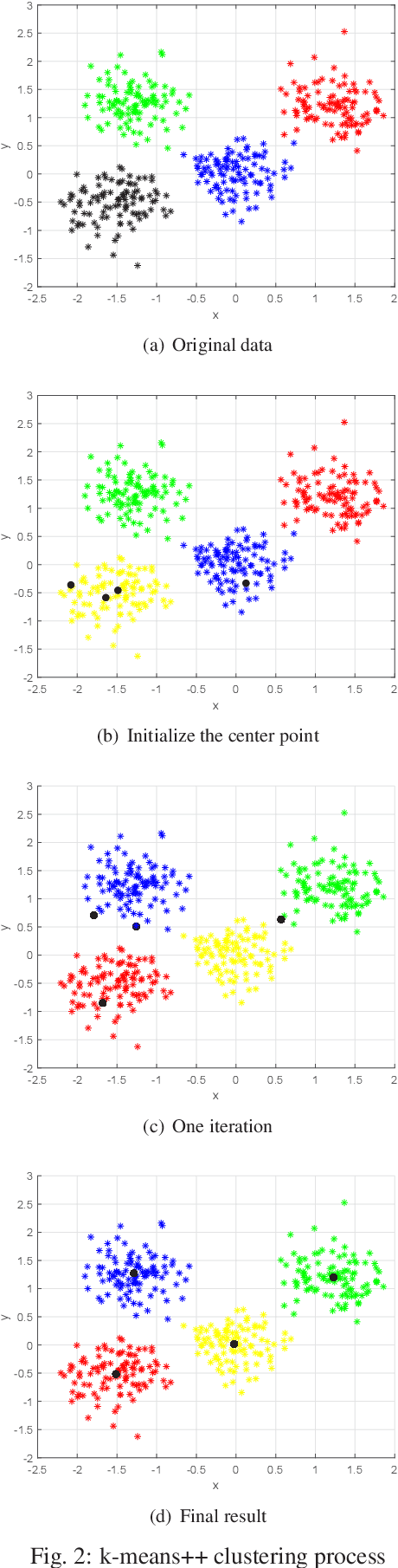
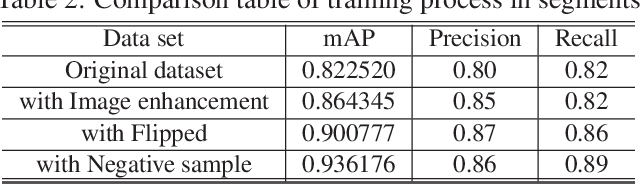
Underwater target detection is a crucial aspect of ocean exploration. However, conventional underwater target detection methods face several challenges such as inaccurate feature extraction, slow detection speed and lack of robustness in complex underwater environments. To address these limitations, this study proposes an improved YOLOv7 network (YOLOv7-AC) for underwater target detection. The proposed network utilizes an ACmixBlock module to replace the 3x3 convolution block in the E-ELAN structure, and incorporates jump connections and 1x1 convolution architecture between ACmixBlock modules to improve feature extraction and network reasoning speed. Additionally, a ResNet-ACmix module is designed to avoid feature information loss and reduce computation, while a Global Attention Mechanism (GAM) is inserted in the backbone and head parts of the model to improve feature extraction. Furthermore, the K-means++ algorithm is used instead of K-means to obtain anchor boxes and enhance model accuracy. Experimental results show that the improved YOLOv7 network outperforms the original YOLOv7 model and other popular underwater target detection methods. The proposed network achieved a mean average precision (mAP) value of 89.6% and 97.4% on the URPC dataset and Brackish dataset, respectively, and demonstrated a higher frame per second (FPS) compared to the original YOLOv7 model. The source code for this study is publicly available at https://github.com/NZWANG/YOLOV7-AC. In conclusion, the improved YOLOv7 network proposed in this study represents a promising solution for underwater target detection and holds great potential for practical applications in various underwater tasks.
A Novel Unified Conditional Score-based Generative Framework for Multi-modal Medical Image Completion
Jul 07, 2022


Multi-modal medical image completion has been extensively applied to alleviate the missing modality issue in a wealth of multi-modal diagnostic tasks. However, for most existing synthesis methods, their inferences of missing modalities can collapse into a deterministic mapping from the available ones, ignoring the uncertainties inherent in the cross-modal relationships. Here, we propose the Unified Multi-Modal Conditional Score-based Generative Model (UMM-CSGM) to take advantage of Score-based Generative Model (SGM) in modeling and stochastically sampling a target probability distribution, and further extend SGM to cross-modal conditional synthesis for various missing-modality configurations in a unified framework. Specifically, UMM-CSGM employs a novel multi-in multi-out Conditional Score Network (mm-CSN) to learn a comprehensive set of cross-modal conditional distributions via conditional diffusion and reverse generation in the complete modality space. In this way, the generation process can be accurately conditioned by all available information, and can fit all possible configurations of missing modalities in a single network. Experiments on BraTS19 dataset show that the UMM-CSGM can more reliably synthesize the heterogeneous enhancement and irregular area in tumor-induced lesions for any missing modalities.
WSEBP: A Novel Width-depth Synchronous Extension-based Basis Pursuit Algorithm for Multi-Layer Convolutional Sparse Coding
Mar 30, 2022



The pursuit algorithms integrated in multi-layer convolutional sparse coding (ML-CSC) can interpret the convolutional neural networks (CNNs). However, many current state-of-art (SOTA) pursuit algorithms require multiple iterations to optimize the solution of ML-CSC, which limits their applications to deeper CNNs due to high computational cost and large number of resources for getting very tiny gain of performance. In this study, we focus on the 0th iteration in pursuit algorithm by introducing an effective initialization strategy for each layer, by which the solution for ML-CSC can be improved. Specifically, we first propose a novel width-depth synchronous extension-based basis pursuit (WSEBP) algorithm which solves the ML-CSC problem without the limitation of the number of iterations compared to the SOTA algorithms and maximizes the performance by an effective initialization in each layer. Then, we propose a simple and unified ML-CSC-based classification network (ML-CSC-Net) which consists of an ML-CSC-based feature encoder and a fully-connected layer to validate the performance of WSEBP on image classification task. The experimental results show that our proposed WSEBP outperforms SOTA algorithms in terms of accuracy and consumption resources. In addition, the WSEBP integrated in CNNs can improve the performance of deeper CNNs and make them interpretable. Finally, taking VGG as an example, we propose WSEBP-VGG13 to enhance the performance of VGG13, which achieves competitive results on four public datasets, i.e., 87.79% vs. 86.83% on Cifar-10 dataset, 58.01% vs. 54.60% on Cifar-100 dataset, 91.52% vs. 89.58% on COVID-19 dataset, and 99.88% vs. 99.78% on Crack dataset, respectively. The results show the effectiveness of the proposed WSEBP, the improved performance of ML-CSC with WSEBP, and interpretation of the CNNs or deeper CNNs.
MSHCNet: Multi-Stream Hybridized Convolutional Networks with Mixed Statistics in Euclidean/Non-Euclidean Spaces and Its Application to Hyperspectral Image Classification
Oct 07, 2021



It is well known that hyperspectral images (HSI) contain rich spatial-spectral contextual information, and how to effectively combine both spectral and spatial information using DNN for HSI classification has become a new research hotspot. Compared with CNN with square kernels, GCN have exhibited exciting potential to model spatial contextual structure and conduct flexible convolution on arbitrarily irregular image regions. However, current GCN only using first-order spectral-spatial signatures can result in boundary blurring and isolated misclassification. To address these, we first designed the graph-based second-order pooling (GSOP) operation to obtain contextual nodes information in non-Euclidean space for GCN. Further, we proposed a novel multi-stream hybridized convolutional network (MSHCNet) with combination of first and second order statistics in Euclidean/non-Euclidean spaces to learn and fuse multi-view complementary information to segment HSIs. Specifically, our MSHCNet adopted four parallel streams, which contained G-stream, utilizing the irregular correlation between adjacent land covers in terms of first-order graph in non-Euclidean space; C-stream, adopting convolution operator to learn regular spatial-spectral features in Euclidean space; N-stream, combining first and second order features to learn representative and discriminative regular spatial-spectral features of Euclidean space; S-stream, using GSOP to capture boundary correlations and obtain graph representations from all nodes in graphs of non-Euclidean space. Besides, these feature representations learned from four different streams were fused to integrate the multi-view complementary information for HSI classification. Finally, we evaluated our proposed MSHCNet on three hyperspectral datasets, and experimental results demonstrated that our method significantly outperformed state-of-the-art eight methods.
RSI-Net: Two-Stream Deep Neural Network Integrating GCN and Atrous CNN for Semantic Segmentation of High-resolution Remote Sensing Images
Sep 19, 2021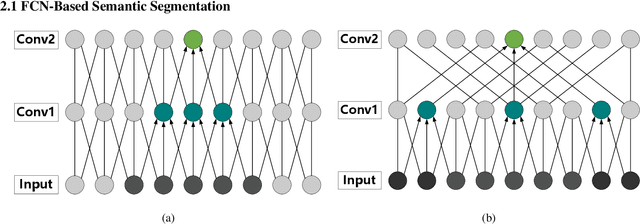
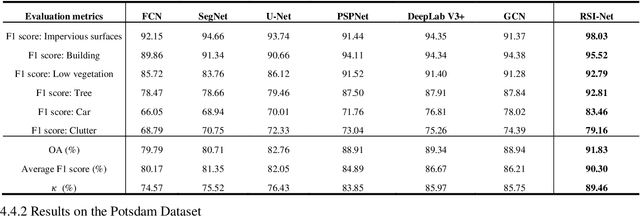
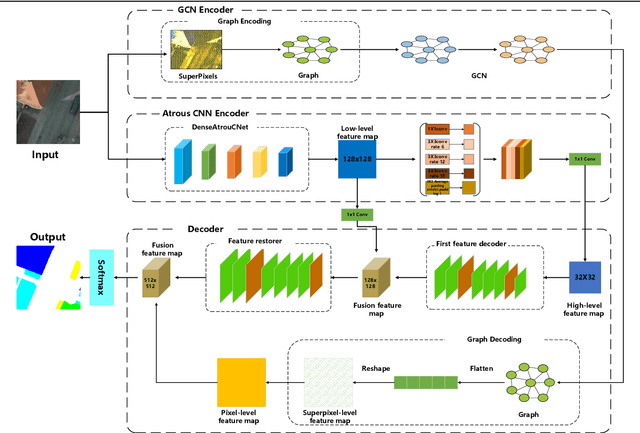
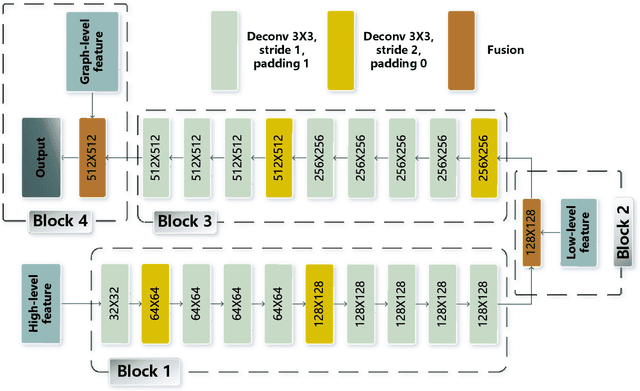
For semantic segmentation of remote sensing images (RSI), trade-off between representation power and location accuracy is quite important. How to get the trade-off effectively is an open question, where current approaches of utilizing attention schemes or very deep models result in complex models with large memory consumption. Compared with the popularly-used convolutional neural network (CNN) with fixed square kernels, graph convolutional network (GCN) can explicitly utilize correlations between adjacent land covers and conduct flexible convolution on arbitrarily irregular image regions. However, the problems of large variations of target scales and blurred boundary cannot be easily solved by GCN, while densely connected atrous convolution network (DenseAtrousCNet) with multi-scale atrous convolution can expand the receptive fields and obtain image global information. Inspired by the advantages of both GCN and Atrous CNN, a two-stream deep neural network for semantic segmentation of RSI (RSI-Net) is proposed in this paper to obtain improved performance through modeling and propagating spatial contextual structure effectively and a novel decoding scheme with image-level and graph-level combination. Extensive experiments are implemented on the Vaihingen, Potsdam and Gaofen RSI datasets, where the comparison results demonstrate the superior performance of RSI-Net in terms of overall accuracy, F1 score and kappa coefficient when compared with six state-of-the-art RSI semantic segmentation methods.
CSC-Unet: A Novel Convolutional Sparse Coding Strategy based Neural Network for Semantic Segmentation
Aug 01, 2021



It is a challenging task to accurately perform semantic segmentation due to the complexity of real picture scenes. Many semantic segmentation methods based on traditional deep learning insufficiently captured the semantic and appearance information of images, which put limit on their generality and robustness for various application scenes. In this paper, we proposed a novel strategy that reformulated the popularly-used convolution operation to multi-layer convolutional sparse coding block to ease the aforementioned deficiency. This strategy can be possibly used to significantly improve the segmentation performance of any semantic segmentation model that involves convolutional operations. To prove the effectiveness of our idea, we chose the widely-used U-Net model for the demonstration purpose, and we designed CSC-Unet model series based on U-Net. Through extensive analysis and experiments, we provided credible evidence showing that the multi-layer convolutional sparse coding block enables semantic segmentation model to converge faster, can extract finer semantic and appearance information of images, and improve the ability to recover spatial detail information. The best CSC-Unet model significantly outperforms the results of the original U-Net on three public datasets with different scenarios, i.e., 87.14% vs. 84.71% on DeepCrack dataset, 68.91% vs. 67.09% on Nuclei dataset, and 53.68% vs. 48.82% on CamVid dataset, respectively.