 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiajie Wang
Collaborative Label Correction via Entropy Thresholding
Apr 27, 2021



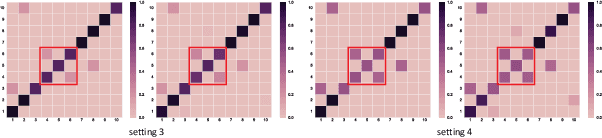
Deep neural networks (DNNs) have the capacity to fit extremely noisy labels nonetheless they tend to learn data with clean labels first and then memorize those with noisy labels. We examine this behavior in light of the Shannon entropy of the predictions and demonstrate the low entropy predictions determined by a given threshold are much more reliable as the supervision than the original noisy labels. It also shows the advantage in maintaining more training samples than previous methods. Then, we power this entropy criterion with the Collaborative Label Correction (CLC) framework to further avoid undesired local minimums of the single network. A range of experiments have been conducted on multiple benchmarks with both synthetic and real-world settings. Extensive results indicate that our CLC outperforms several state-of-the-art methods.
Collaborative Learning for Weakly Supervised Object Detection
Feb 10, 2018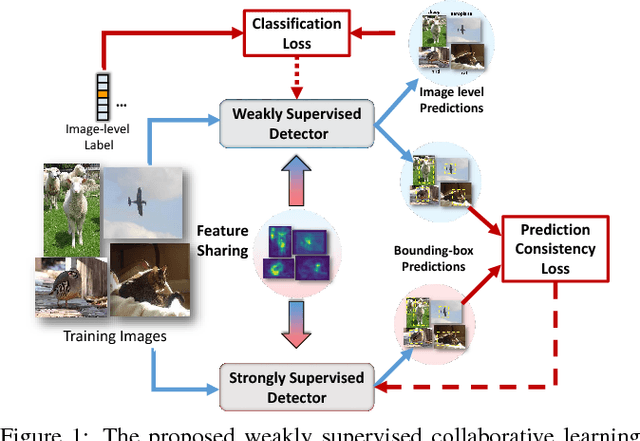
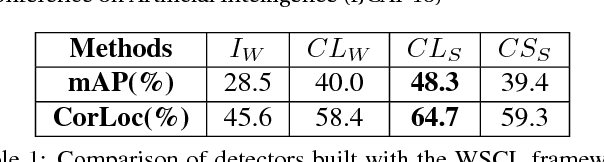
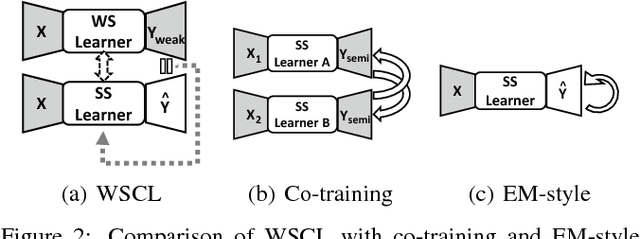
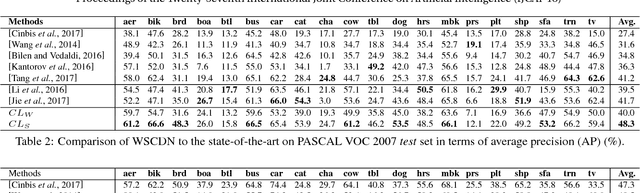
Weakly supervised object detection has recently received much attention, since it only requires image-level labels instead of the bounding-box labels consumed in strongly supervised learning. Nevertheless, the save in labeling expense is usually at the cost of model accuracy. In this paper, we propose a simple but effective weakly supervised collaborative learning framework to resolve this problem, which trains a weakly supervised learner and a strongly supervised learner jointly by enforcing partial feature sharing and prediction consistency. For object detection, taking WSDDN-like architecture as weakly supervised detector sub-network and Faster-RCNN-like architecture as strongly supervised detector sub-network, we propose an end-to-end Weakly Supervised Collaborative Detection Network. As there is no strong supervision available to train the Faster-RCNN-like sub-network, a new prediction consistency loss is defined to enforce consistency of predictions between the two sub-networks as well as within the Faster-RCNN-like sub-networks. At the same time, the two detectors are designed to partially share features to further guarantee the model consistency at perceptual level. Extensive experiments on PASCAL VOC 2007 and 2012 data sets have demonstrated the effectiveness of the proposed framework.
Deep Learning from Noisy Image Labels with Quality Embedding
Nov 02, 2017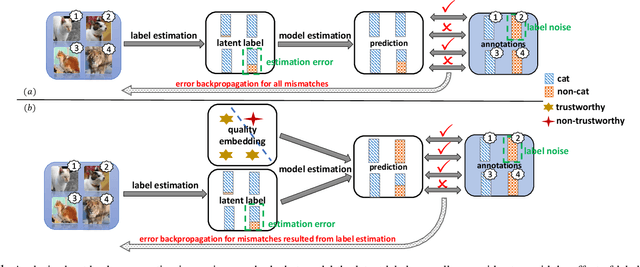
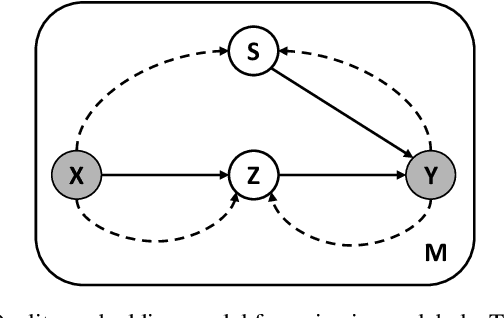
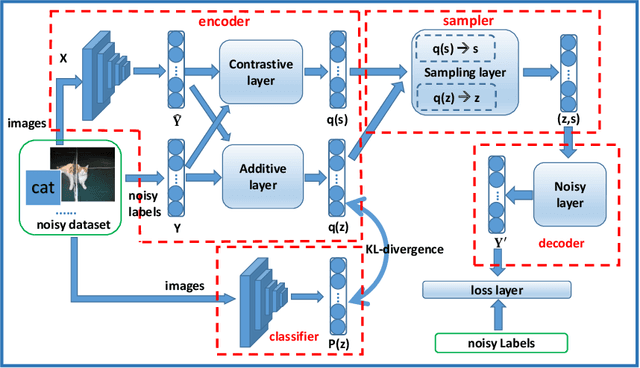

There is an emerging trend to leverage noisy image datasets in many visual recognition tasks. However, the label noise among the datasets severely degenerates the \mbox{performance of deep} learning approaches. Recently, one mainstream is to introduce the latent label to handle label noise, which has shown promising improvement in the network designs. Nevertheless, the mismatch between latent labels and noisy labels still affects the predictions in such methods. To address this issue, we propose a quality embedding model, which explicitly introduces a quality variable to represent the trustworthiness of noisy labels. Our key idea is to identify the mismatch between the latent and noisy labels by embedding the quality variables into different subspaces, which effectively minimizes the noise effect. At the same time, the high-quality labels is still able to be applied for training. To instantiate the model, we further propose a Contrastive-Additive Noise network (CAN), which consists of two important layers: (1) the contrastive layer estimates the quality variable in the embedding space to reduce noise effect; and (2) the additive layer aggregates the prior predictions and noisy labels as the posterior to train the classifier. Moreover, to tackle the optimization difficulty, we deduce an SGD algorithm with the reparameterization tricks, which makes our method scalable to big data. We conduct the experimental evaluation of the proposed method over a range of noisy image datasets. Comprehensive results have demonstrated CAN outperforms the state-of-the-art deep learning approaches.