 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiajun Zhou
A Federated Parameter Aggregation Method for Node Classification Tasks with Different Graph Network Structures
Mar 24, 2024
Over the past few years, federated learning has become widely used in various classical machine learning fields because of its collaborative ability to train data from multiple sources without compromising privacy. However, in the area of graph neural networks, the nodes and network structures of graphs held by clients are different in many practical applications, and the aggregation method that directly shares model gradients cannot be directly applied to this scenario. Therefore, this work proposes a federated aggregation method FLGNN applied to various graph federation scenarios and investigates the aggregation effect of parameter sharing at each layer of the graph neural network model. The effectiveness of the federated aggregation method FLGNN is verified by experiments on real datasets. Additionally, for the privacy security of FLGNN, this paper designs membership inference attack experiments and differential privacy defense experiments. The results show that FLGNN performs good robustness, and the success rate of privacy theft is further reduced by adding differential privacy defense methods.
EG-ConMix: An Intrusion Detection Method based on Graph Contrastive Learning
Mar 24, 2024As the number of IoT devices increases, security concerns become more prominent. The impact of threats can be minimized by deploying Network Intrusion Detection System (NIDS) by monitoring network traffic, detecting and discovering intrusions, and issuing security alerts promptly. Most intrusion detection research in recent years has been directed towards the pair of traffic itself without considering the interrelationships among them, thus limiting the monitoring of complex IoT network attack events. Besides, anomalous traffic in real networks accounts for only a small fraction, which leads to a severe imbalance problem in the dataset that makes algorithmic learning and prediction extremely difficult. In this paper, we propose an EG-ConMix method based on E-GraphSAGE, incorporating a data augmentation module to fix the problem of data imbalance. In addition, we incorporate contrastive learning to discern the difference between normal and malicious traffic samples, facilitating the extraction of key features. Extensive experiments on two publicly available datasets demonstrate the superior intrusion detection performance of EG-ConMix compared to state-of-the-art methods. Remarkably, it exhibits significant advantages in terms of training speed and accuracy for large-scale graphs.
LoRETTA: Low-Rank Economic Tensor-Train Adaptation for Ultra-Low-Parameter Fine-Tuning of Large Language Models
Feb 18, 2024Various parameter-efficient fine-tuning (PEFT) techniques have been proposed to enable computationally efficient fine-tuning while maintaining model performance. However, existing PEFT methods are still limited by the growing number of trainable parameters with the rapid deployment of Large Language Models (LLMs). To address this challenge, we present LoRETTA, an ultra-parameter-efficient framework that significantly reduces trainable parameters through tensor-train decomposition. Specifically, we propose two methods, named {LoRETTA}$_{adp}$ and {LoRETTA}$_{rep}$. The former employs tensorized adapters, offering a high-performance yet lightweight approach for the fine-tuning of LLMs. The latter emphasizes fine-tuning via weight parameterization with a set of small tensor factors. LoRETTA achieves comparable or better performance than most widely used PEFT methods with up to $100\times$ fewer parameters on the LLaMA-2-7B models. Furthermore, empirical results demonstrate that the proposed method effectively improves training efficiency, enjoys better multi-task learning performance, and enhances the anti-overfitting capability. Plug-and-play codes built upon the Huggingface framework and PEFT library will be released.
A Unifying Tensor View for Lightweight CNNs
Dec 15, 2023Despite the decomposition of convolutional kernels for lightweight CNNs being well studied, existing works that rely on tensor network diagrams or hyperdimensional abstraction lack geometry intuition. This work devises a new perspective by linking a 3D-reshaped kernel tensor to its various slice-wise and rank-1 decompositions, permitting a straightforward connection between various tensor approximations and efficient CNN modules. Specifically, it is discovered that a pointwise-depthwise-pointwise (PDP) configuration constitutes a viable construct for lightweight CNNs. Moreover, a novel link to the latest ShiftNet is established, inspiring a first-ever shift layer pruning that achieves nearly 50% compression with < 1% drop in accuracy for ShiftResNet.
Hundred-Kilobyte Lookup Tables for Efficient Single-Image Super-Resolution
Dec 11, 2023Conventional super-resolution (SR) schemes make heavy use of convolutional neural networks (CNNs), which involve intensive multiply-accumulate (MAC) operations, and require specialized hardware such as graphics processing units. This contradicts the regime of edge AI that often runs on devices strained by power, computing, and storage resources. Such a challenge has motivated a series of lookup table (LUT)-based SR schemes that employ simple LUT readout and largely elude CNN computation. Nonetheless, the multi-megabyte LUTs in existing methods still prohibit on-chip storage and necessitate off-chip memory transport. This work tackles this storage hurdle and innovates hundred-kilobyte LUT (HKLUT) models amenable to on-chip cache. Utilizing an asymmetric two-branch multistage network coupled with a suite of specialized kernel patterns, HKLUT demonstrates an uncompromising performance and superior hardware efficiency over existing LUT schemes.
Lite it fly: An All-Deformable-Butterfly Network
Nov 14, 2023Most deep neural networks (DNNs) consist fundamentally of convolutional and/or fully connected layers, wherein the linear transform can be cast as the product between a filter matrix and a data matrix obtained by arranging feature tensors into columns. The lately proposed deformable butterfly (DeBut) decomposes the filter matrix into generalized, butterflylike factors, thus achieving network compression orthogonal to the traditional ways of pruning or low-rank decomposition. This work reveals an intimate link between DeBut and a systematic hierarchy of depthwise and pointwise convolutions, which explains the empirically good performance of DeBut layers. By developing an automated DeBut chain generator, we show for the first time the viability of homogenizing a DNN into all DeBut layers, thus achieving an extreme sparsity and compression. Various examples and hardware benchmarks verify the advantages of All-DeBut networks. In particular, we show it is possible to compress a PointNet to < 5% parameters with < 5% accuracy drop, a record not achievable by other compression schemes.
PathMLP: Smooth Path Towards High-order Homophily
Jun 23, 2023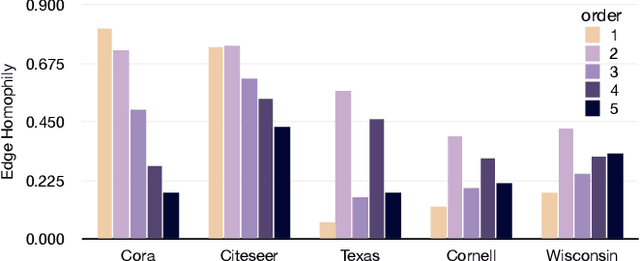
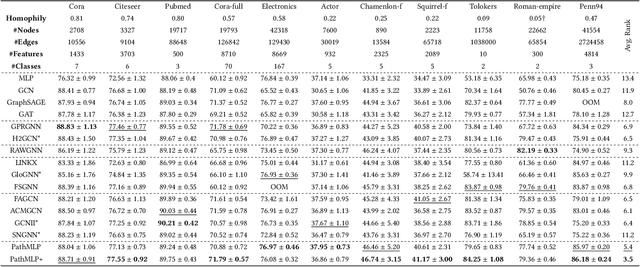


Real-world graphs exhibit increasing heterophily, where nodes no longer tend to be connected to nodes with the same label, challenging the homophily assumption of classical graph neural networks (GNNs) and impeding their performance. Intriguingly, we observe that certain high-order information on heterophilous data exhibits high homophily, which motivates us to involve high-order information in node representation learning. However, common practices in GNNs to acquire high-order information mainly through increasing model depth and altering message-passing mechanisms, which, albeit effective to a certain extent, suffer from three shortcomings: 1) over-smoothing due to excessive model depth and propagation times; 2) high-order information is not fully utilized; 3) low computational efficiency. In this regard, we design a similarity-based path sampling strategy to capture smooth paths containing high-order homophily. Then we propose a lightweight model based on multi-layer perceptrons (MLP), named PathMLP, which can encode messages carried by paths via simple transformation and concatenation operations, and effectively learn node representations in heterophilous graphs through adaptive path aggregation. Extensive experiments demonstrate that our method outperforms baselines on 16 out of 20 datasets, underlining its effectiveness and superiority in alleviating the heterophily problem. In addition, our method is immune to over-smoothing and has high computational efficiency.
Clarify Confused Nodes Through Separated Learning
Jun 04, 2023Graph neural networks (GNNs) have achieved remarkable advances in graph-oriented tasks. However, real-world graphs invariably contain a certain proportion of heterophilous nodes, challenging the homophily assumption of classical GNNs and hindering their performance. Most existing studies continue to design generic models with shared weights between heterophilous and homophilous nodes. Despite the incorporation of high-order message or multi-channel architectures, these efforts often fall short. A minority of studies attempt to train different node groups separately, but suffering from inappropriate separation metric and low efficiency. In this paper, we first propose a new metric, termed Neighborhood Confusion (NC), to facilitate a more reliable separation of nodes. We observe that node groups with different levels of NC values exhibit certain differences in intra-group accuracy and visualized embeddings. These pave a way for Neighborhood Confusion-guided Graph Convolutional Network (NCGCN), in which nodes are grouped by their NC values and accept intra-group weight sharing and message passing. Extensive experiments on both homophilous and heterophilous benchmarks demonstrate that NCGCN can effectively separate nodes and offers significant performance improvement compared to latest methods.
DyBit: Dynamic Bit-Precision Numbers for Efficient Quantized Neural Network Inference
Feb 24, 2023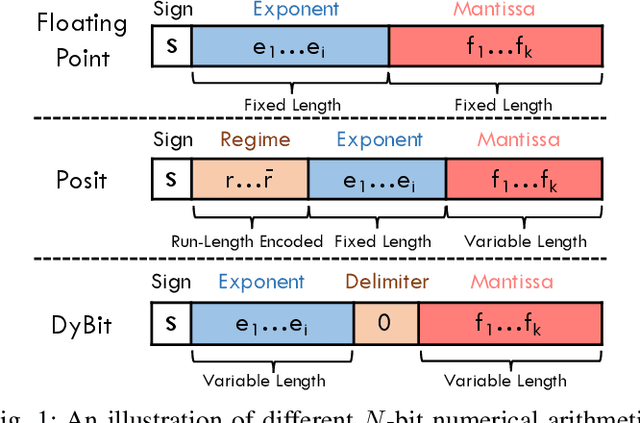

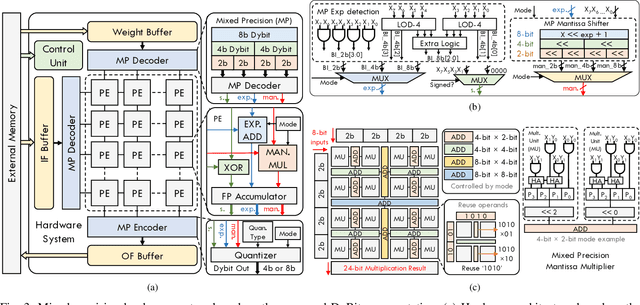
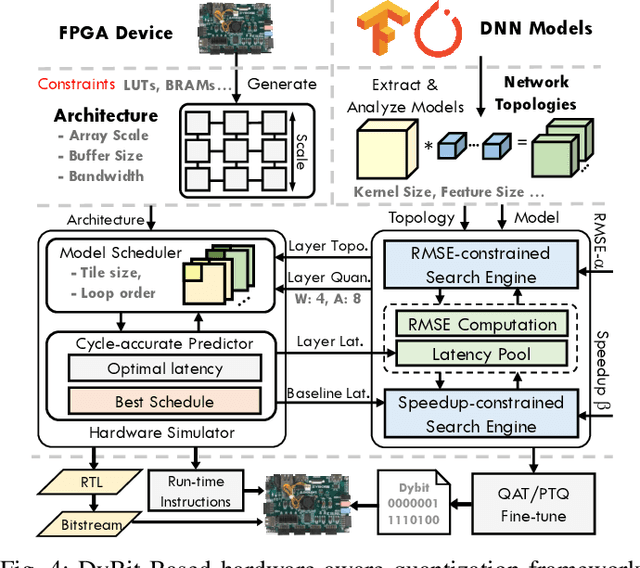
To accelerate the inference of deep neural networks (DNNs), quantization with low-bitwidth numbers is actively researched. A prominent challenge is to quantize the DNN models into low-bitwidth numbers without significant accuracy degradation, especially at very low bitwidths (< 8 bits). This work targets an adaptive data representation with variable-length encoding called DyBit. DyBit can dynamically adjust the precision and range of separate bit-field to be adapted to the DNN weights/activations distribution. We also propose a hardware-aware quantization framework with a mixed-precision accelerator to trade-off the inference accuracy and speedup. Experimental results demonstrate that the inference accuracy via DyBit is 1.997% higher than the state-of-the-art at 4-bit quantization, and the proposed framework can achieve up to 8.1x speedup compared with the original model.
Neighborhood Homophily-Guided Graph Convolutional Network
Jan 24, 2023



Graph neural networks (GNNs) have achieved remarkable advances in graph-oriented tasks. However, many real-world graphs contain heterophily or low homophily, challenging the homophily assumption of classical GNNs and resulting in low performance. Although many studies have emerged to improve the universality of GNNs, they rarely consider the label reuse and the correlation of their proposed metrics and models. In this paper, we first design a new metric, named Neighborhood Homophily (\textit{NH}), to measure the label complexity or purity in the neighborhood of nodes. Furthermore, we incorporate this metric into the classical graph convolutional network (GCN) architecture and propose \textbf{N}eighborhood \textbf{H}omophily-\textbf{G}uided \textbf{G}raph \textbf{C}onvolutional \textbf{N}etwork (\textbf{NHGCN}). In this framework, nodes are grouped by estimated \textit{NH} values to achieve intra-group weight sharing during message propagation and aggregation. Then the generated node predictions are used to estimate and update new \textit{NH} values. The two processes of metric estimation and model inference are alternately optimized to achieve better node classification. Extensive experiments on both homophilous and heterophilous benchmarks demonstrate that \textbf{NHGCN} achieves state-of-the-art overall performance on semi-supervised node classification for the universality problem.