 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShanqing Yu
A Federated Parameter Aggregation Method for Node Classification Tasks with Different Graph Network Structures
Mar 24, 2024
Over the past few years, federated learning has become widely used in various classical machine learning fields because of its collaborative ability to train data from multiple sources without compromising privacy. However, in the area of graph neural networks, the nodes and network structures of graphs held by clients are different in many practical applications, and the aggregation method that directly shares model gradients cannot be directly applied to this scenario. Therefore, this work proposes a federated aggregation method FLGNN applied to various graph federation scenarios and investigates the aggregation effect of parameter sharing at each layer of the graph neural network model. The effectiveness of the federated aggregation method FLGNN is verified by experiments on real datasets. Additionally, for the privacy security of FLGNN, this paper designs membership inference attack experiments and differential privacy defense experiments. The results show that FLGNN performs good robustness, and the success rate of privacy theft is further reduced by adding differential privacy defense methods.
General2Specialized LLMs Translation for E-commerce
Mar 06, 2024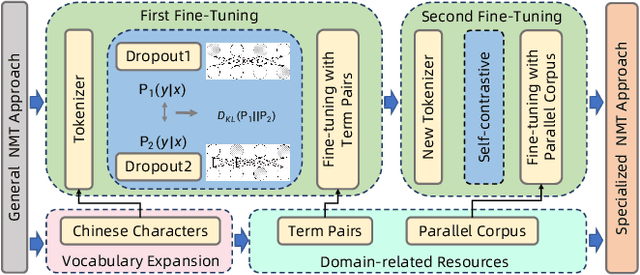
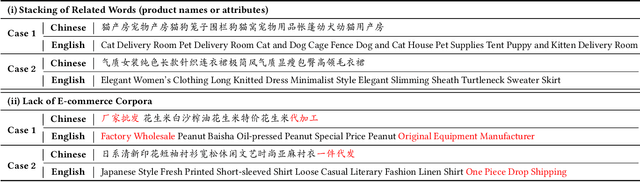
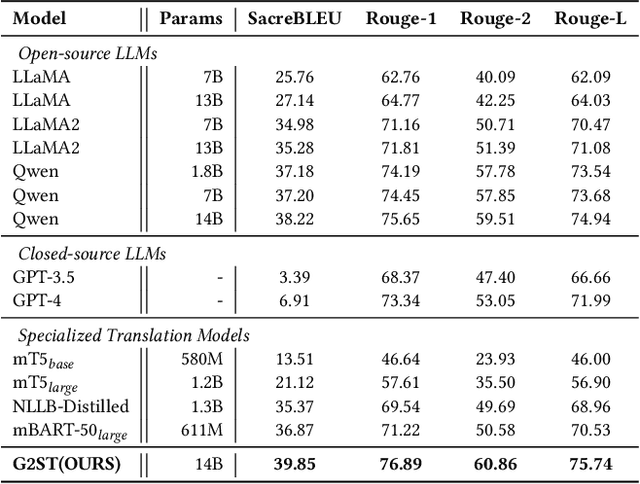
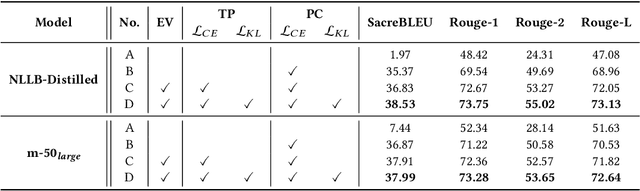
Existing Neural Machine Translation (NMT) models mainly handle translation in the general domain, while overlooking domains with special writing formulas, such as e-commerce and legal documents. Taking e-commerce as an example, the texts usually include amounts of domain-related words and have more grammar problems, which leads to inferior performances of current NMT methods. To address these problems, we collect two domain-related resources, including a set of term pairs (aligned Chinese-English bilingual terms) and a parallel corpus annotated for the e-commerce domain. Furthermore, we propose a two-step fine-tuning paradigm (named G2ST) with self-contrastive semantic enhancement to transfer one general NMT model to the specialized NMT model for e-commerce. The paradigm can be used for the NMT models based on Large language models (LLMs). Extensive evaluations on real e-commerce titles demonstrate the superior translation quality and robustness of our G2ST approach, as compared with state-of-the-art NMT models such as LLaMA, Qwen, GPT-3.5, and even GPT-4.
PathMLP: Smooth Path Towards High-order Homophily
Jun 23, 2023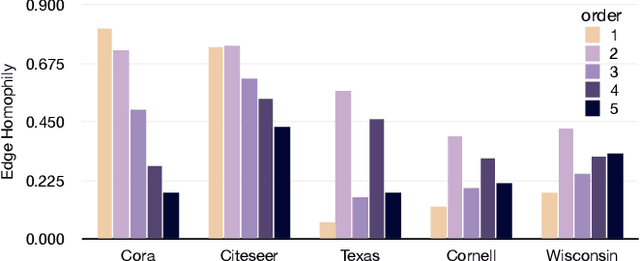
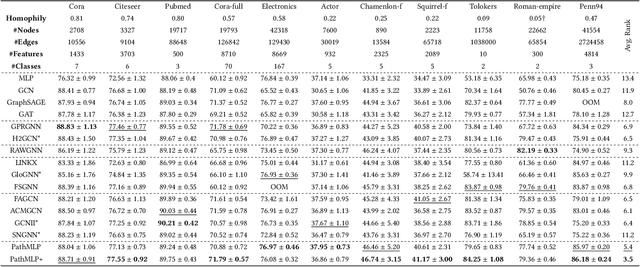


Real-world graphs exhibit increasing heterophily, where nodes no longer tend to be connected to nodes with the same label, challenging the homophily assumption of classical graph neural networks (GNNs) and impeding their performance. Intriguingly, we observe that certain high-order information on heterophilous data exhibits high homophily, which motivates us to involve high-order information in node representation learning. However, common practices in GNNs to acquire high-order information mainly through increasing model depth and altering message-passing mechanisms, which, albeit effective to a certain extent, suffer from three shortcomings: 1) over-smoothing due to excessive model depth and propagation times; 2) high-order information is not fully utilized; 3) low computational efficiency. In this regard, we design a similarity-based path sampling strategy to capture smooth paths containing high-order homophily. Then we propose a lightweight model based on multi-layer perceptrons (MLP), named PathMLP, which can encode messages carried by paths via simple transformation and concatenation operations, and effectively learn node representations in heterophilous graphs through adaptive path aggregation. Extensive experiments demonstrate that our method outperforms baselines on 16 out of 20 datasets, underlining its effectiveness and superiority in alleviating the heterophily problem. In addition, our method is immune to over-smoothing and has high computational efficiency.
Subgraph Networks Based Contrastive Learning
Jun 06, 2023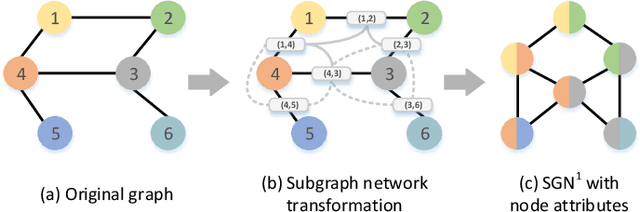

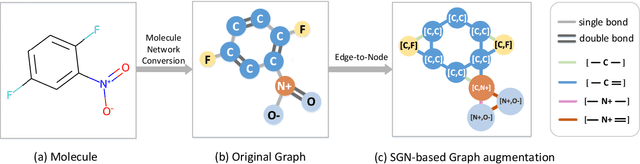
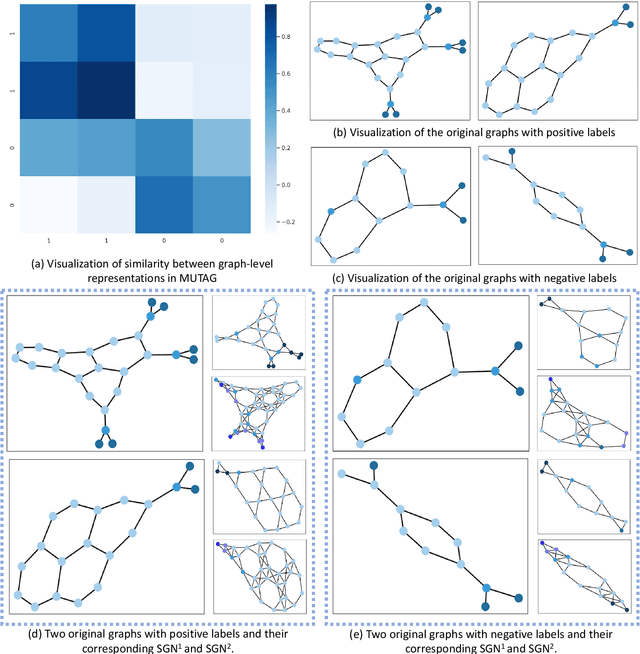
Graph contrastive learning (GCL), as a self-supervised learning method, can solve the problem of annotated data scarcity. It mines explicit features in unannotated graphs to generate favorable graph representations for downstream tasks. Most existing GCL methods focus on the design of graph augmentation strategies and mutual information estimation operations. Graph augmentation produces augmented views by graph perturbations. These views preserve a locally similar structure and exploit explicit features. However, these methods have not considered the interaction existing in subgraphs. To explore the impact of substructure interactions on graph representations, we propose a novel framework called subgraph network-based contrastive learning (SGNCL). SGNCL applies a subgraph network generation strategy to produce augmented views. This strategy converts the original graph into an Edge-to-Node mapping network with both topological and attribute features. The single-shot augmented view is a first-order subgraph network that mines the interaction between nodes, node-edge, and edges. In addition, we also investigate the impact of the second-order subgraph augmentation on mining graph structure interactions, and further, propose a contrastive objective that fuses the first-order and second-order subgraph information. We compare SGNCL with classical and state-of-the-art graph contrastive learning methods on multiple benchmark datasets of different domains. Extensive experiments show that SGNCL achieves competitive or better performance (top three) on all datasets in unsupervised learning settings. Furthermore, SGNCL achieves the best average gain of 6.9\% in transfer learning compared to the best method. Finally, experiments also demonstrate that mining substructure interactions have positive implications for graph contrastive learning.
Single Node Injection Label Specificity Attack on Graph Neural Networks via Reinforcement Learning
May 04, 2023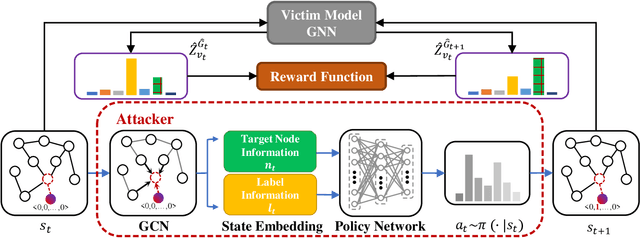


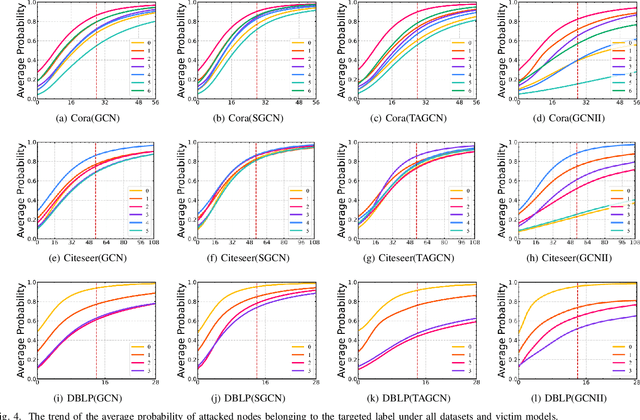
Graph neural networks (GNNs) have achieved remarkable success in various real-world applications. However, recent studies highlight the vulnerability of GNNs to malicious perturbations. Previous adversaries primarily focus on graph modifications or node injections to existing graphs, yielding promising results but with notable limitations. Graph modification attack~(GMA) requires manipulation of the original graph, which is often impractical, while graph injection attack~(GIA) necessitates training a surrogate model in the black-box setting, leading to significant performance degradation due to divergence between the surrogate architecture and the actual victim model. Furthermore, most methods concentrate on a single attack goal and lack a generalizable adversary to develop distinct attack strategies for diverse goals, thus limiting precise control over victim model behavior in real-world scenarios. To address these issues, we present a gradient-free generalizable adversary that injects a single malicious node to manipulate the classification result of a target node in the black-box evasion setting. We propose Gradient-free Generalizable Single Node Injection Attack, namely G$^2$-SNIA, a reinforcement learning framework employing Proximal Policy Optimization. By directly querying the victim model, G$^2$-SNIA learns patterns from exploration to achieve diverse attack goals with extremely limited attack budgets. Through comprehensive experiments over three acknowledged benchmark datasets and four prominent GNNs in the most challenging and realistic scenario, we demonstrate the superior performance of our proposed G$^2$-SNIA over the existing state-of-the-art baselines. Moreover, by comparing G$^2$-SNIA with multiple white-box evasion baselines, we confirm its capacity to generate solutions comparable to those of the best adversaries.
Discover Important Paths in the Knowledge Graph Based on Dynamic Relation Confidence
Nov 02, 2022


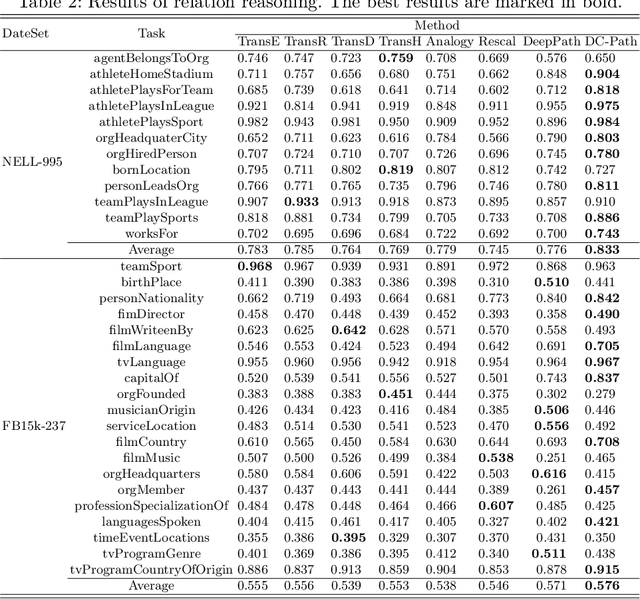
Most of the existing knowledge graphs are not usually complete and can be complemented by some reasoning algorithms. The reasoning method based on path features is widely used in the field of knowledge graph reasoning and completion on account of that its have strong interpretability. However, reasoning methods based on path features still have several problems in the following aspects: Path search isinefficient, insufficient paths for sparse tasks and some paths are not helpful for reasoning tasks. In order to solve the above problems, this paper proposes a method called DC-Path that combines dynamic relation confidence and other indicators to evaluate path features, and then guide path search, finally conduct relation reasoning. Experimental result show that compared with the existing relation reasoning algorithm, this method can select the most representative features in the current reasoning task from the knowledge graph and achieve better performance on the current relation reasoning task.
SubGraph Networks based Entity Alignment for Cross-lingual Knowledge Graph
May 07, 2022

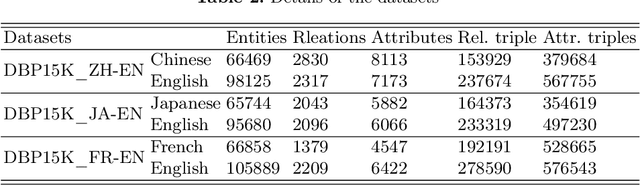
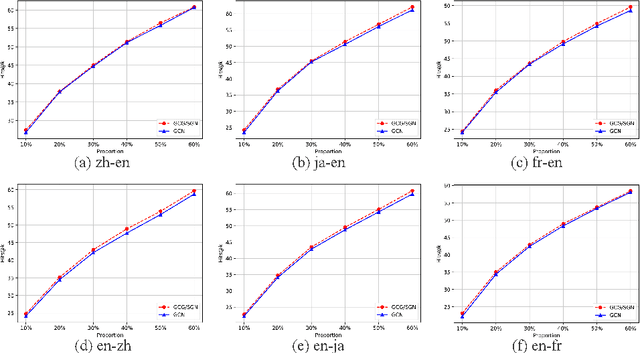
Entity alignment is the task of finding entities representing the same real-world object in two knowledge graphs(KGs). Cross-lingual knowledge graph entity alignment aims to discover the cross-lingual links in the multi-language KGs, which is of great significance to the NLP applications and multi-language KGs fusion. In the task of aligning cross-language knowledge graphs, the structures of the two graphs are very similar, and the equivalent entities often have the same subgraph structure characteristics. The traditional GCN method neglects to obtain structural features through representative parts of the original graph and the use of adjacency matrix is not enough to effectively represent the structural features of the graph. In this paper, we introduce the subgraph network (SGN) method into the GCN-based cross-lingual KG entity alignment method. In the method, we extracted the first-order subgraphs of the KGs to expand the structural features of the original graph to enhance the representation ability of the entity embedding and improve the alignment accuracy. Experiments show that the proposed method outperforms the state-of-the-art GCN-based method.
Mixing Signals: Data Augmentation Approach for Deep Learning Based Modulation Recognition
Apr 05, 2022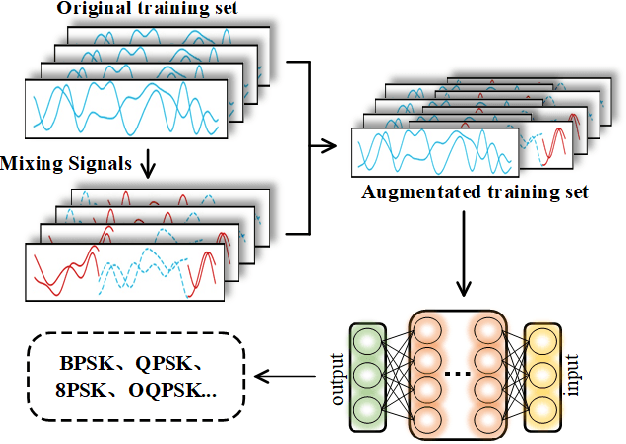
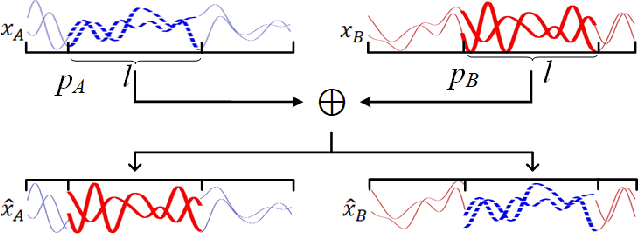
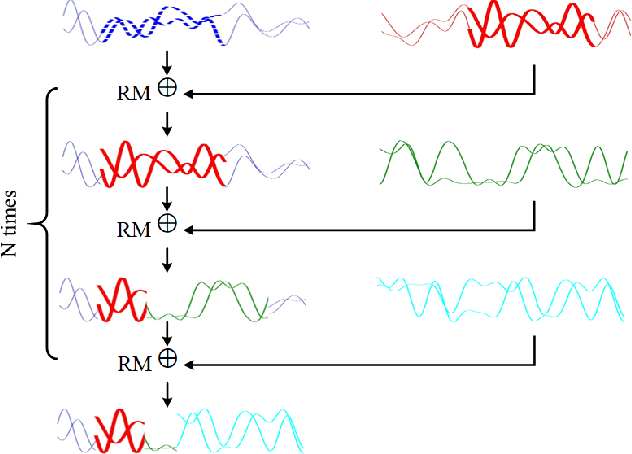

With the rapid development of deep learning, automatic modulation recognition (AMR), as an important task in cognitive radio, has gradually transformed from traditional feature extraction and classification to automatic classification by deep learning technology. However, deep learning models are data-driven methods, which often require a large amount of data as the training support. Data augmentation, as the strategy of expanding dataset, can improve the generalization of the deep learning models and thus improve the accuracy of the models to a certain extent. In this paper, for AMR of radio signals, we propose a data augmentation strategy based on mixing signals and consider four specific methods (Random Mixing, Maximum-Similarity-Mixing, $\theta-$Similarity Mixing and n-times Random Mixing) to achieve data augmentation. Experiments show that our proposed method can improve the classification accuracy of deep learning based AMR models in the full public dataset RML2016.10a. In particular, for the case of a single signal-to-noise ratio signal set, the classification accuracy can be significantly improved, which verifies the effectiveness of the methods.
Graph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning
Oct 13, 2021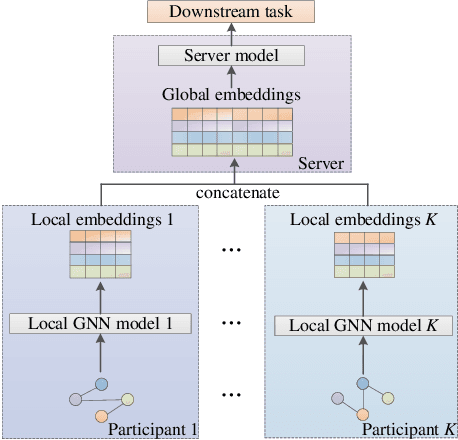
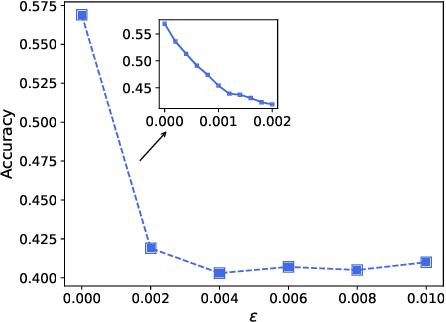
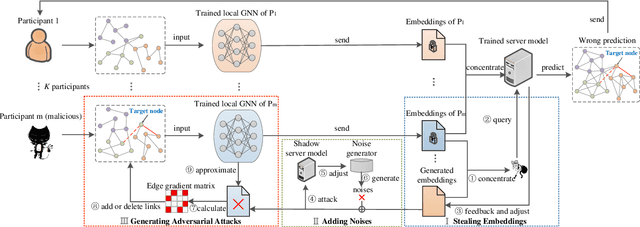
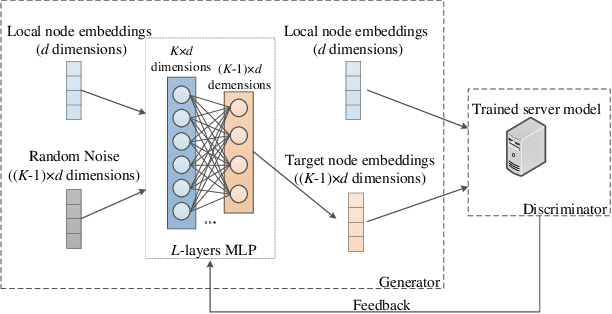
Graph neural network (GNN) models have achieved great success on graph representation learning. Challenged by large scale private data collection from user-side, GNN models may not be able to reflect the excellent performance, without rich features and complete adjacent relationships. Addressing to the problem, vertical federated learning (VFL) is proposed to implement local data protection through training a global model collaboratively. Consequently, for graph-structured data, it is natural idea to construct VFL framework with GNN models. However, GNN models are proven to be vulnerable to adversarial attacks. Whether the vulnerability will be brought into the VFL has not been studied. In this paper, we devote to study the security issues of GNN based VFL (GVFL), i.e., robustness against adversarial attacks. Further, we propose an adversarial attack method, named Graph-Fraudster. It generates adversarial perturbations based on the noise-added global node embeddings via GVFL's privacy leakage, and the gradient of pairwise node. First, it steals the global node embeddings and sets up a shadow server model for attack generator. Second, noises are added into node embeddings to confuse the shadow server model. At last, the gradient of pairwise node is used to generate attacks with the guidance of noise-added node embeddings. To the best of our knowledge, this is the first study of adversarial attacks on GVFL. The extensive experiments on five benchmark datasets demonstrate that Graph-Fraudster performs better than three possible baselines in GVFL. Furthermore, Graph-Fraudster can remain a threat to GVFL even if two possible defense mechanisms are applied. This paper reveals that GVFL is vulnerable to adversarial attack similar to centralized GNN models.
TSGN: Transaction Subgraph Networks for Identifying Ethereum Phishing Accounts
Apr 20, 2021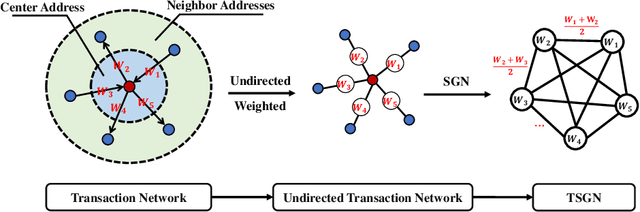
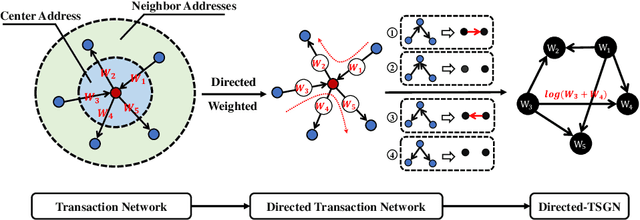
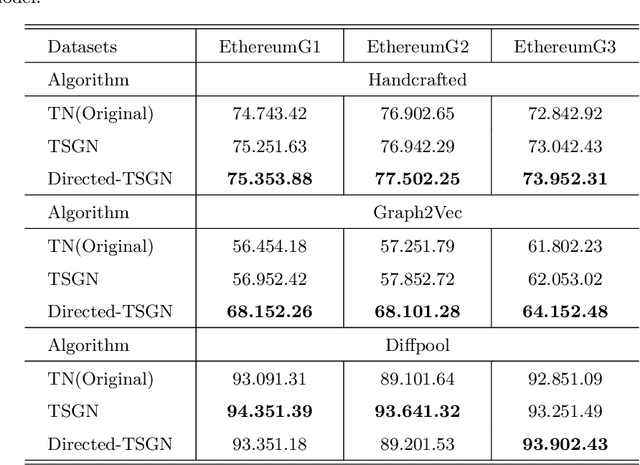
Blockchain technology and, in particular, blockchain-based transaction offers us information that has never been seen before in the financial world. In contrast to fiat currencies, transactions through virtual currencies like Bitcoin are completely public. And these transactions of cryptocurrencies are permanently recorded on Blockchain and are available at any time. Therefore, this allows us to build transaction networks (TN) to analyze illegal phenomenons such as phishing scams in blockchain from a network perspective. In this paper, we propose a Transaction SubGraph Network (TSGN) based classification model to identify phishing accounts in Ethereum. Firstly we extract transaction subgraphs for each address and then expand these subgraphs into corresponding TSGNs based on the different mapping mechanisms. We find that TSGNs can provide more potential information to benefit the identification of phishing accounts. Moreover, Directed-TSGNs, by introducing direction attributes, can retain the transaction flow information that captures the significant topological pattern of phishing scams. By comparing with the TSGN, Directed-TSGN indeed has much lower time complexity, benefiting the graph representation learning. Experimental results demonstrate that, combined with network representation algorithms, the TSGN model can capture more features to enhance the classification algorithm and improve phishing nodes' identification accuracy in the Ethereum networks.