 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiang Li
Mitigating Heterogeneity among Factor Tensors via Lie Group Manifolds for Tensor Decomposition Based Temporal Knowledge Graph Embedding
Apr 14, 2024
Recent studies have highlighted the effectiveness of tensor decomposition methods in the Temporal Knowledge Graphs Embedding (TKGE) task. However, we found that inherent heterogeneity among factor tensors in tensor decomposition significantly hinders the tensor fusion process and further limits the performance of link prediction. To overcome this limitation, we introduce a novel method that maps factor tensors onto a unified smooth Lie group manifold to make the distribution of factor tensors approximating homogeneous in tensor decomposition. We provide the theoretical proof of our motivation that homogeneous tensors are more effective than heterogeneous tensors in tensor fusion and approximating the target for tensor decomposition based TKGE methods. The proposed method can be directly integrated into existing tensor decomposition based TKGE methods without introducing extra parameters. Extensive experiments demonstrate the effectiveness of our method in mitigating the heterogeneity and in enhancing the tensor decomposition based TKGE models.
Towards Architecture-Insensitive Untrained Network Priors for Accelerated MRI Reconstruction
Dec 15, 2023Untrained neural networks pioneered by Deep Image Prior (DIP) have recently enabled MRI reconstruction without requiring fully-sampled measurements for training. Their success is widely attributed to the implicit regularization induced by suitable network architectures. However, the lack of understanding of such architectural priors results in superfluous design choices and sub-optimal outcomes. This work aims to simplify the architectural design decisions for DIP-MRI to facilitate its practical deployment. We observe that certain architectural components are more prone to causing overfitting regardless of the number of parameters, incurring severe reconstruction artifacts by hindering accurate extrapolation on the un-acquired measurements. We interpret this phenomenon from a frequency perspective and find that the architectural characteristics favoring low frequencies, i.e., deep and narrow with unlearnt upsampling, can lead to enhanced generalization and hence better reconstruction. Building on this insight, we propose two architecture-agnostic remedies: one to constrain the frequency range of the white-noise input and the other to penalize the Lipschitz constants of the network. We demonstrate that even with just one extra line of code on the input, the performance gap between the ill-designed models and the high-performing ones can be closed. These results signify that for the first time, architectural biases on untrained MRI reconstruction can be mitigated without architectural modifications.
Watch the Speakers: A Hybrid Continuous Attribution Network for Emotion Recognition in Conversation With Emotion Disentanglement
Sep 19, 2023



Emotion Recognition in Conversation (ERC) has attracted widespread attention in the natural language processing field due to its enormous potential for practical applications. Existing ERC methods face challenges in achieving generalization to diverse scenarios due to insufficient modeling of context, ambiguous capture of dialogue relationships and overfitting in speaker modeling. In this work, we present a Hybrid Continuous Attributive Network (HCAN) to address these issues in the perspective of emotional continuation and emotional attribution. Specifically, HCAN adopts a hybrid recurrent and attention-based module to model global emotion continuity. Then a novel Emotional Attribution Encoding (EAE) is proposed to model intra- and inter-emotional attribution for each utterance. Moreover, aiming to enhance the robustness of the model in speaker modeling and improve its performance in different scenarios, A comprehensive loss function emotional cognitive loss $\mathcal{L}_{\rm EC}$ is proposed to alleviate emotional drift and overcome the overfitting of the model to speaker modeling. Our model achieves state-of-the-art performance on three datasets, demonstrating the superiority of our work. Another extensive comparative experiments and ablation studies on three benchmarks are conducted to provided evidence to support the efficacy of each module. Further exploration of generalization ability experiments shows the plug-and-play nature of the EAE module in our method.
Simple Model Also Works: A Novel Emotion Recognition Network in Textual Conversation Based on Curriculum Learning Strategy
Aug 12, 2023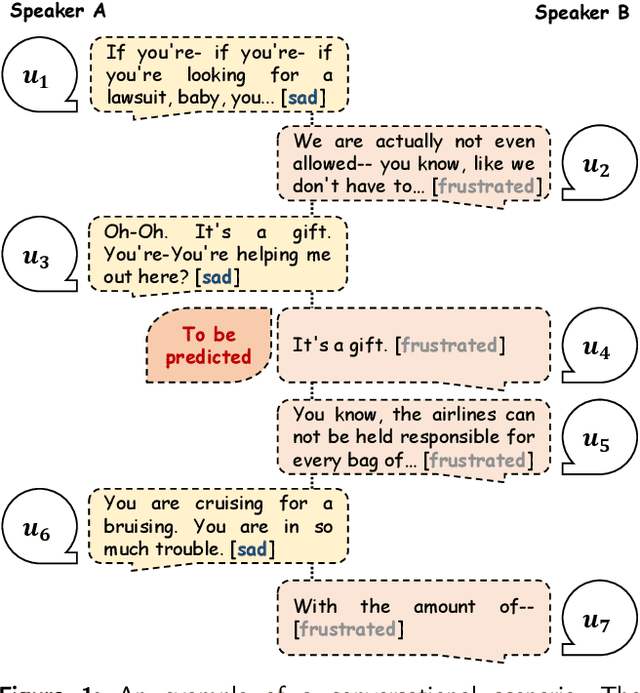
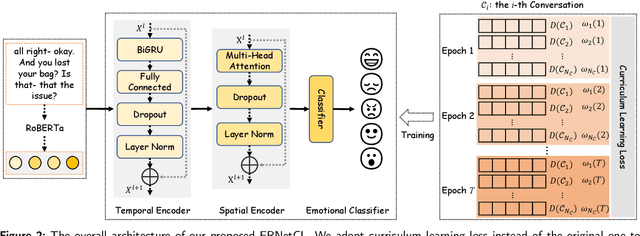
Emotion Recognition in Conversation (ERC) has emerged as a research hotspot in domains such as conversational robots and question-answer systems. How to efficiently and adequately retrieve contextual emotional cues has been one of the key challenges in the ERC task. Existing efforts do not fully model the context and employ complex network structures, resulting in excessive computational resource overhead without substantial performance improvement. In this paper, we propose a novel Emotion Recognition Network based on Curriculum Learning strategy (ERNetCL). The proposed ERNetCL primarily consists of Temporal Encoder (TE), Spatial Encoder (SE), and Curriculum Learning (CL) loss. We utilize TE and SE to combine the strengths of previous methods in a simplistic manner to efficiently capture temporal and spatial contextual information in the conversation. To simulate the way humans learn curriculum from easy to hard, we apply the idea of CL to the ERC task to progressively optimize the network parameters of ERNetCL. At the beginning of training, we assign lower learning weights to difficult samples. As the epoch increases, the learning weights for these samples are gradually raised. Extensive experiments on four datasets exhibit that our proposed method is effective and dramatically beats other baseline models.
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jul 28, 2023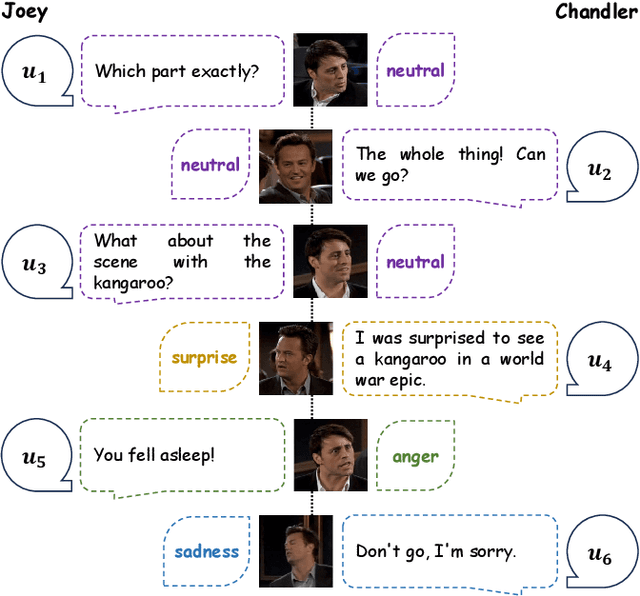
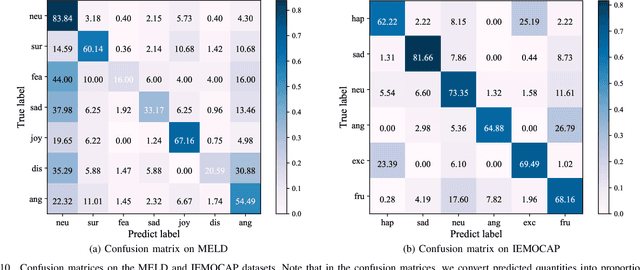
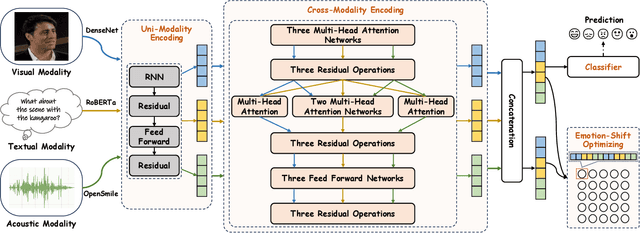
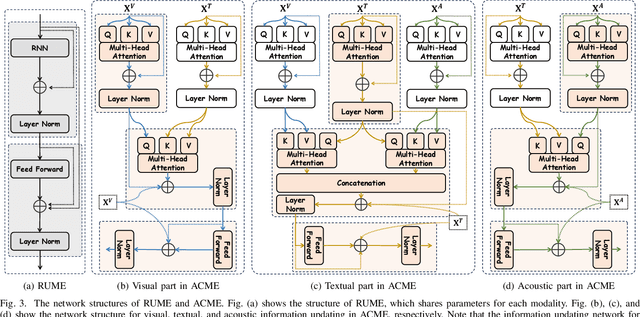
Multimodal Emotion Recognition in Conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a cross-modal fusion network with emotion-shift awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information, rendering it hard to adequately extract complementary and associative information from multimodal data. To cope with this problem, in CFN-ESA, textual modalities are treated as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of the unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together the data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture related information, thereby guide the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform the state-of-the-art models.
A Dual-Stream Recurrence-Attention Network with Global-Local Awareness for Emotion Recognition in Textual Dialogue
Jul 02, 2023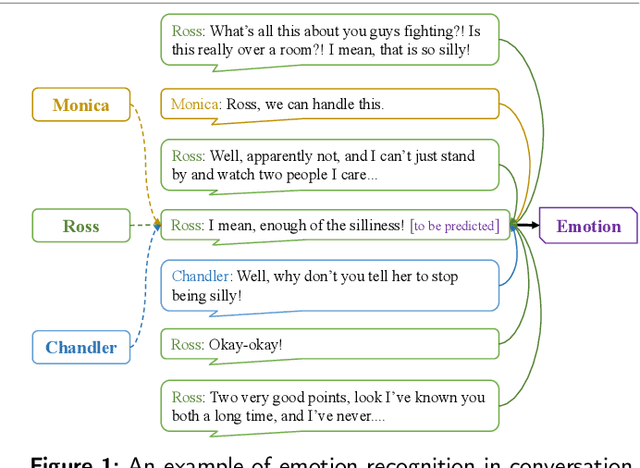
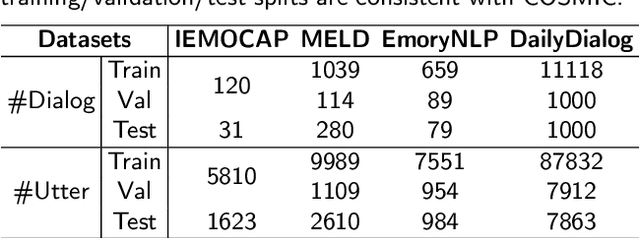
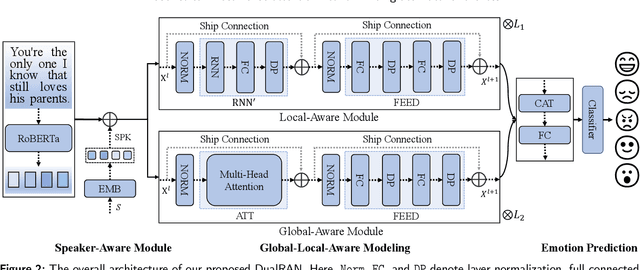

In real-world dialogue systems, the ability to understand the user's emotions and interact anthropomorphically is of great significance. Emotion Recognition in Conversation (ERC) is one of the key ways to accomplish this goal and has attracted growing attention. How to model the context in a conversation is a central aspect and a major challenge of ERC tasks. Most existing approaches are generally unable to capture both global and local contextual information efficiently, and their network structures are too complex to design. For this reason, in this work, we propose a straightforward Dual-stream Recurrence-Attention Network (DualRAN) based on Recurrent Neural Network (RNN) and Multi-head ATtention network (MAT). The proposed model eschews the complex network structure of current methods and focuses on combining recurrence-based methods with attention-based methods. DualRAN is a dual-stream structure mainly consisting of local- and global-aware modules, modeling a conversation from distinct perspectives. To achieve the local-aware module, we extend the structure of RNN, thus enhancing the expressive capability of the network. In addition, we develop two single-stream network variants for DualRAN, i.e., SingleRANv1 and SingleRANv2. We conduct extensive experiments on four widely used benchmark datasets, and the results reveal that the proposed model outshines all baselines. Ablation studies further demonstrate the effectiveness of each component.
TransERR: Translation-based Knowledge Graph Completion via Efficient Relation Rotation
Jun 26, 2023



This paper presents translation-based knowledge graph completion method via efficient relation rotation (TransERR), a straightforward yet effective alternative to traditional translation-based knowledge graph completion models. Different from the previous translation-based models, TransERR encodes knowledge graphs in the hypercomplex-valued space, thus enabling it to possess a higher degree of translation freedom in mining latent information between the head and tail entities. To further minimize the translation distance, TransERR adaptively rotates the head entity and the tail entity with their corresponding unit quaternions, which are learnable in model training. The experiments on 7 benchmark datasets validate the effectiveness and the generalization of TransERR. The results also indicate that TransERR can better encode large-scale datasets with fewer parameters than the previous translation-based models. Our code is available at: \url{https://github.com/dellixx/TransERR}.
Towards Complex Real-World Safety Factory Inspection: A High-Quality Dataset for Safety Clothing and Helmet Detection
Jun 03, 2023


Safety clothing and helmets play a crucial role in ensuring worker safety at construction sites. Recently, deep learning methods have garnered significant attention in the field of computer vision for their potential to enhance safety and efficiency in various industries. However, limited availability of high-quality datasets has hindered the development of deep learning methods for safety clothing and helmet detection. In this work, we present a large, comprehensive, and realistic high-quality dataset for safety clothing and helmet detection, which was collected from a real-world chemical plant and annotated by professional security inspectors. Our dataset has been compared with several existing open-source datasets, and its effectiveness has been verified applying some classic object detection methods. The results demonstrate that our dataset is more complete and performs better in real-world settings. Furthermore, we have released our deployment code to the public to encourage the adoption of our dataset and improve worker safety. We hope that our efforts will promote the convergence of academic research and industry, ultimately contribute to the betterment of society.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023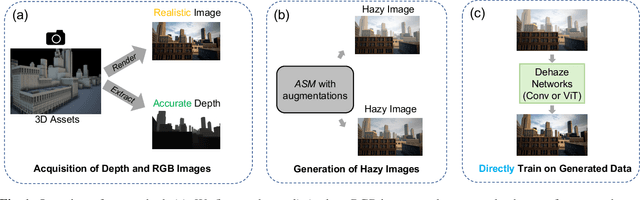
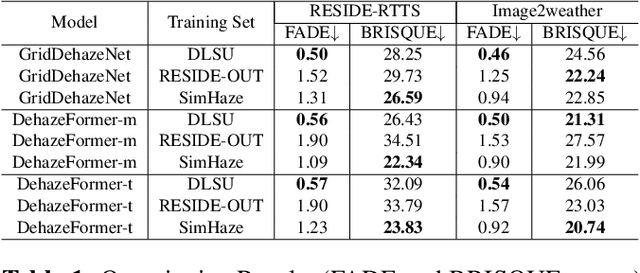

Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
The Devil is in the Upsampling: Architectural Decisions Made Simpler for Denoising with Deep Image Prior
Apr 22, 2023



Deep Image Prior (DIP) shows that some network architectures naturally bias towards smooth images and resist noises, a phenomenon known as spectral bias. Image denoising is an immediate application of this property. Although DIP has removed the requirement of large training sets, it still presents two practical challenges for denoising: architectural design and noise-fitting, which are often intertwined. Existing methods mostly handcraft or search for the architecture from a large design space, due to the lack of understanding on how the architectural choice corresponds to the image. In this study, we analyze from a frequency perspective to demonstrate that the unlearnt upsampling is the main driving force behind the denoising phenomenon in DIP. This finding then leads to strategies for estimating a suitable architecture for every image without a laborious search. Extensive experiments show that the estimated architectures denoise and preserve the textural details better than current methods with up to 95% fewer parameters. The under-parameterized nature also makes them especially robust to a higher level of noise.