 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaran Zhou
FreqBlender: Enhancing DeepFake Detection by Blending Frequency Knowledge
Apr 22, 2024
Generating synthetic fake faces, known as pseudo-fake faces, is an effective way to improve the generalization of DeepFake detection. Existing methods typically generate these faces by blending real or fake faces in color space. While these methods have shown promise, they overlook the simulation of frequency distribution in pseudo-fake faces, limiting the learning of generic forgery traces in-depth. To address this, this paper introduces {\em FreqBlender}, a new method that can generate pseudo-fake faces by blending frequency knowledge. Specifically, we investigate the major frequency components and propose a Frequency Parsing Network to adaptively partition frequency components related to forgery traces. Then we blend this frequency knowledge from fake faces into real faces to generate pseudo-fake faces. Since there is no ground truth for frequency components, we describe a dedicated training strategy by leveraging the inner correlations among different frequency knowledge to instruct the learning process. Experimental results demonstrate the effectiveness of our method in enhancing DeepFake detection, making it a potential plug-and-play strategy for other methods.
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
Apr 22, 2024Sequential DeepFake detection is an emerging task that aims to predict the manipulation sequence in order. Existing methods typically formulate it as an image-to-sequence problem, employing conventional Transformer architectures for detection. However, these methods lack dedicated design and consequently result in limited performance. In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance. Our method features four major improvements. Firstly, we describe a texture-aware branch that effectively captures subtle manipulation traces with the Diversiform Pixel Difference Attention module. Then we introduce a Bidirectional Interaction Cross-attention module that seeks deep correlations among spatial and sequential features, enabling effective modeling of complex manipulation traces. To further enhance the cross-attention, we describe a Shape-guided Gaussian mapping strategy, providing initial priors of the manipulation shape. Finally, observing that the latter manipulation in a sequence may influence traces left in the earlier one, we intriguingly invert the prediction order from forward to backward, leading to notable gains as expected. Extensive experimental results demonstrate that our method outperforms others by a large margin, highlighting the superiority of our method.
Multilateral Temporal-view Pyramid Transformer for Video Inpainting Detection
Apr 17, 2024The task of video inpainting detection is to expose the pixel-level inpainted regions within a video sequence. Existing methods usually focus on leveraging spatial and temporal inconsistencies. However, these methods typically employ fixed operations to combine spatial and temporal clues, limiting their applicability in different scenarios. In this paper, we introduce a novel Multilateral Temporal-view Pyramid Transformer ({\em MumPy}) that collaborates spatial-temporal clues flexibly. Our method utilizes a newly designed multilateral temporal-view encoder to extract various collaborations of spatial-temporal clues and introduces a deformable window-based temporal-view interaction module to enhance the diversity of these collaborations. Subsequently, we develop a multi-pyramid decoder to aggregate the various types of features and generate detection maps. By adjusting the contribution strength of spatial and temporal clues, our method can effectively identify inpainted regions. We validate our method on existing datasets and also introduce a new challenging and large-scale Video Inpainting dataset based on the YouTube-VOS dataset, which employs several more recent inpainting methods. The results demonstrate the superiority of our method in both in-domain and cross-domain evaluation scenarios.
ForensicsForest Family: A Series of Multi-scale Hierarchical Cascade Forests for Detecting GAN-generated Faces
Aug 02, 2023
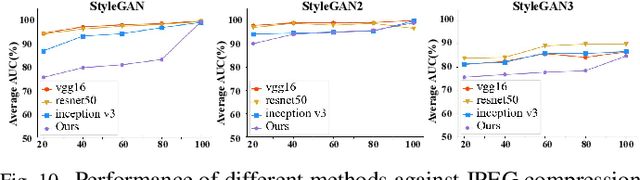
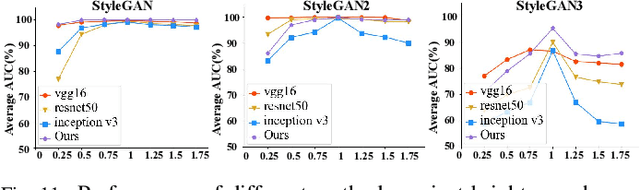

The prominent progress in generative models has significantly improved the reality of generated faces, bringing serious concerns to society. Since recent GAN-generated faces are in high realism, the forgery traces have become more imperceptible, increasing the forensics challenge. To combat GAN-generated faces, many countermeasures based on Convolutional Neural Networks (CNNs) have been spawned due to their strong learning ability. In this paper, we rethink this problem and explore a new approach based on forest models instead of CNNs. Specifically, we describe a simple and effective forest-based method set called {\em ForensicsForest Family} to detect GAN-generate faces. The proposed ForensicsForest family is composed of three variants, which are {\em ForensicsForest}, {\em Hybrid ForensicsForest} and {\em Divide-and-Conquer ForensicsForest} respectively. ForenscisForest is a newly proposed Multi-scale Hierarchical Cascade Forest, which takes semantic, frequency and biology features as input, hierarchically cascades different levels of features for authenticity prediction, and then employs a multi-scale ensemble scheme that can comprehensively consider different levels of information to improve the performance further. Based on ForensicsForest, we develop Hybrid ForensicsForest, an extended version that integrates the CNN layers into models, to further refine the effectiveness of augmented features. Moreover, to reduce the memory cost in training, we propose Divide-and-Conquer ForensicsForest, which can construct a forest model using only a portion of training samplings. In the training stage, we train several candidate forest models using the subsets of training samples. Then a ForensicsForest is assembled by picking the suitable components from these candidate forest models...