 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuezun Li
Texture-aware and Shape-guided Transformer for Sequential DeepFake Detection
Apr 22, 2024
Sequential DeepFake detection is an emerging task that aims to predict the manipulation sequence in order. Existing methods typically formulate it as an image-to-sequence problem, employing conventional Transformer architectures for detection. However, these methods lack dedicated design and consequently result in limited performance. In this paper, we propose a novel Texture-aware and Shape-guided Transformer to enhance detection performance. Our method features four major improvements. Firstly, we describe a texture-aware branch that effectively captures subtle manipulation traces with the Diversiform Pixel Difference Attention module. Then we introduce a Bidirectional Interaction Cross-attention module that seeks deep correlations among spatial and sequential features, enabling effective modeling of complex manipulation traces. To further enhance the cross-attention, we describe a Shape-guided Gaussian mapping strategy, providing initial priors of the manipulation shape. Finally, observing that the latter manipulation in a sequence may influence traces left in the earlier one, we intriguingly invert the prediction order from forward to backward, leading to notable gains as expected. Extensive experimental results demonstrate that our method outperforms others by a large margin, highlighting the superiority of our method.
FreqBlender: Enhancing DeepFake Detection by Blending Frequency Knowledge
Apr 22, 2024Generating synthetic fake faces, known as pseudo-fake faces, is an effective way to improve the generalization of DeepFake detection. Existing methods typically generate these faces by blending real or fake faces in color space. While these methods have shown promise, they overlook the simulation of frequency distribution in pseudo-fake faces, limiting the learning of generic forgery traces in-depth. To address this, this paper introduces {\em FreqBlender}, a new method that can generate pseudo-fake faces by blending frequency knowledge. Specifically, we investigate the major frequency components and propose a Frequency Parsing Network to adaptively partition frequency components related to forgery traces. Then we blend this frequency knowledge from fake faces into real faces to generate pseudo-fake faces. Since there is no ground truth for frequency components, we describe a dedicated training strategy by leveraging the inner correlations among different frequency knowledge to instruct the learning process. Experimental results demonstrate the effectiveness of our method in enhancing DeepFake detection, making it a potential plug-and-play strategy for other methods.
Multilateral Temporal-view Pyramid Transformer for Video Inpainting Detection
Apr 17, 2024The task of video inpainting detection is to expose the pixel-level inpainted regions within a video sequence. Existing methods usually focus on leveraging spatial and temporal inconsistencies. However, these methods typically employ fixed operations to combine spatial and temporal clues, limiting their applicability in different scenarios. In this paper, we introduce a novel Multilateral Temporal-view Pyramid Transformer ({\em MumPy}) that collaborates spatial-temporal clues flexibly. Our method utilizes a newly designed multilateral temporal-view encoder to extract various collaborations of spatial-temporal clues and introduces a deformable window-based temporal-view interaction module to enhance the diversity of these collaborations. Subsequently, we develop a multi-pyramid decoder to aggregate the various types of features and generate detection maps. By adjusting the contribution strength of spatial and temporal clues, our method can effectively identify inpainted regions. We validate our method on existing datasets and also introduce a new challenging and large-scale Video Inpainting dataset based on the YouTube-VOS dataset, which employs several more recent inpainting methods. The results demonstrate the superiority of our method in both in-domain and cross-domain evaluation scenarios.
DomainForensics: Exposing Face Forgery across Domains via Bi-directional Adaptation
Dec 17, 2023Recent DeepFake detection methods have shown excellent performance on public datasets but are significantly degraded on new forgeries. Solving this problem is important, as new forgeries emerge daily with the continuously evolving generative techniques. Many efforts have been made for this issue by seeking the commonly existing traces empirically on data level. In this paper, we rethink this problem and propose a new solution from the unsupervised domain adaptation perspective. Our solution, called DomainForensics, aims to transfer the forgery knowledge from known forgeries to new forgeries. Unlike recent efforts, our solution does not focus on data view but on learning strategies of DeepFake detectors to capture the knowledge of new forgeries through the alignment of domain discrepancies. In particular, unlike the general domain adaptation methods which consider the knowledge transfer in the semantic class category, thus having limited application, our approach captures the subtle forgery traces. We describe a new bi-directional adaptation strategy dedicated to capturing the forgery knowledge across domains. Specifically, our strategy considers both forward and backward adaptation, to transfer the forgery knowledge from the source domain to the target domain in forward adaptation and then reverse the adaptation from the target domain to the source domain in backward adaptation. In forward adaptation, we perform supervised training for the DeepFake detector in the source domain and jointly employ adversarial feature adaptation to transfer the ability to detect manipulated faces from known forgeries to new forgeries. In backward adaptation, we further improve the knowledge transfer by coupling adversarial adaptation with self-distillation on new forgeries. This enables the detector to expose new forgery features from unlabeled data and avoid forgetting the known knowledge of known...
Contrastive Multi-FaceForensics: An End-to-end Bi-grained Contrastive Learning Approach for Multi-face Forgery Detection
Aug 03, 2023
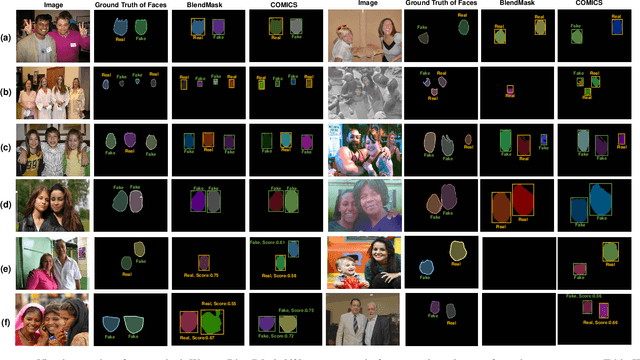


DeepFakes have raised serious societal concerns, leading to a great surge in detection-based forensics methods in recent years. Face forgery recognition is the conventional detection method that usually follows a two-phase pipeline: it extracts the face first and then determines its authenticity by classification. Since DeepFakes in the wild usually contain multiple faces, using face forgery detection methods is merely practical as they have to process faces in a sequel, i.e., only one face is processed at the same time. One straightforward way to address this issue is to integrate face extraction and forgery detection in an end-to-end fashion by adapting advanced object detection architectures. However, as these object detection architectures are designed to capture the semantic information of different object categories rather than the subtle forgery traces among the faces, the direct adaptation is far from optimal. In this paper, we describe a new end-to-end framework, Contrastive Multi-FaceForensics (COMICS), to enhance multi-face forgery detection. The core of the proposed framework is a novel bi-grained contrastive learning approach that explores effective face forgery traces at both the coarse- and fine-grained levels. Specifically, the coarse-grained level contrastive learning captures the discriminative features among positive and negative proposal pairs in multiple scales with the instruction of the proposal generator, and the fine-grained level contrastive learning captures the pixel-wise discrepancy between the forged and original areas of the same face and the pixel-wise content inconsistency between different faces. Extensive experiments on the OpenForensics dataset demonstrate our method outperforms other counterparts by a large margin (~18.5%) and shows great potential for integration into various architectures.
ForensicsForest Family: A Series of Multi-scale Hierarchical Cascade Forests for Detecting GAN-generated Faces
Aug 02, 2023
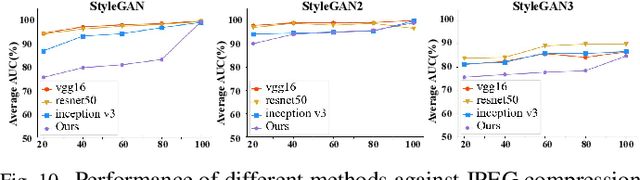
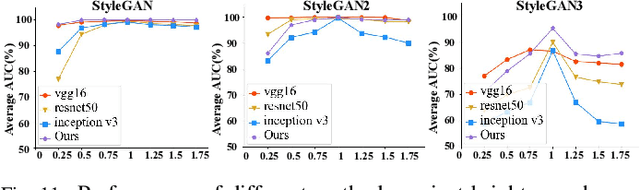

The prominent progress in generative models has significantly improved the reality of generated faces, bringing serious concerns to society. Since recent GAN-generated faces are in high realism, the forgery traces have become more imperceptible, increasing the forensics challenge. To combat GAN-generated faces, many countermeasures based on Convolutional Neural Networks (CNNs) have been spawned due to their strong learning ability. In this paper, we rethink this problem and explore a new approach based on forest models instead of CNNs. Specifically, we describe a simple and effective forest-based method set called {\em ForensicsForest Family} to detect GAN-generate faces. The proposed ForensicsForest family is composed of three variants, which are {\em ForensicsForest}, {\em Hybrid ForensicsForest} and {\em Divide-and-Conquer ForensicsForest} respectively. ForenscisForest is a newly proposed Multi-scale Hierarchical Cascade Forest, which takes semantic, frequency and biology features as input, hierarchically cascades different levels of features for authenticity prediction, and then employs a multi-scale ensemble scheme that can comprehensively consider different levels of information to improve the performance further. Based on ForensicsForest, we develop Hybrid ForensicsForest, an extended version that integrates the CNN layers into models, to further refine the effectiveness of augmented features. Moreover, to reduce the memory cost in training, we propose Divide-and-Conquer ForensicsForest, which can construct a forest model using only a portion of training samplings. In the training stage, we train several candidate forest models using the subsets of training samples. Then a ForensicsForest is assembled by picking the suitable components from these candidate forest models...
FakeTracer: Proactively Defending Against Face-swap DeepFakes via Implanting Traces in Training
Jul 27, 2023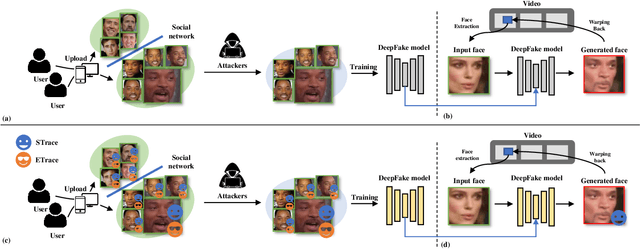


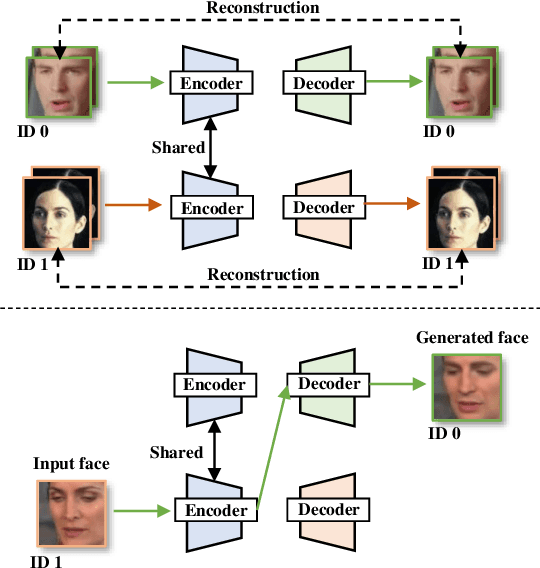
Face-swap DeepFake is an emerging AI-based face forgery technique that can replace the original face in a video with a generated face of the target identity while retaining consistent facial attributes such as expression and orientation. Due to the high privacy of faces, the misuse of this technique can raise severe social concerns, drawing tremendous attention to defend against DeepFakes recently. In this paper, we describe a new proactive defense method called FakeTracer to expose face-swap DeepFakes via implanting traces in training. Compared to general face-synthesis DeepFake, the face-swap DeepFake is more complex as it involves identity change, is subjected to the encoding-decoding process, and is trained unsupervised, increasing the difficulty of implanting traces into the training phase. To effectively defend against face-swap DeepFake, we design two types of traces, sustainable trace (STrace) and erasable trace (ETrace), to be added to training faces. During the training, these manipulated faces affect the learning of the face-swap DeepFake model, enabling it to generate faces that only contain sustainable traces. In light of these two traces, our method can effectively expose DeepFakes by identifying them. Extensive experiments are conducted on the Celeb-DF dataset, compared with recent passive and proactive defense methods, and are studied thoroughly regarding various factors, corroborating the efficacy of our method on defending against face-swap DeepFake.
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022
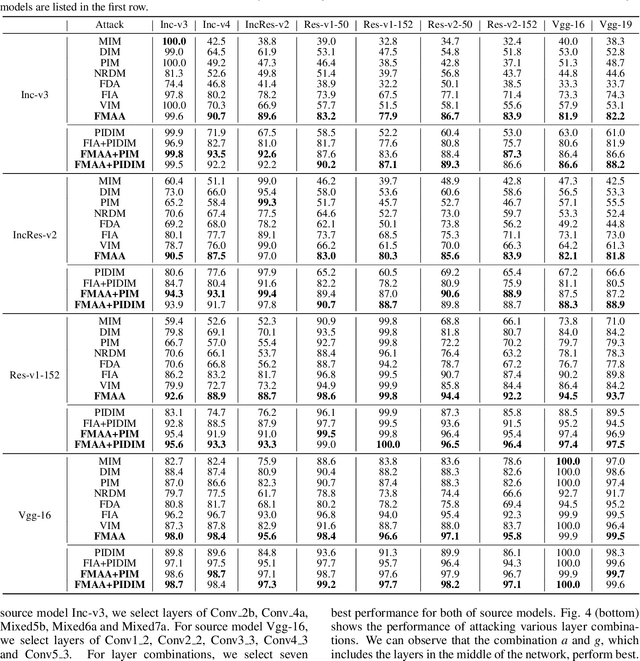

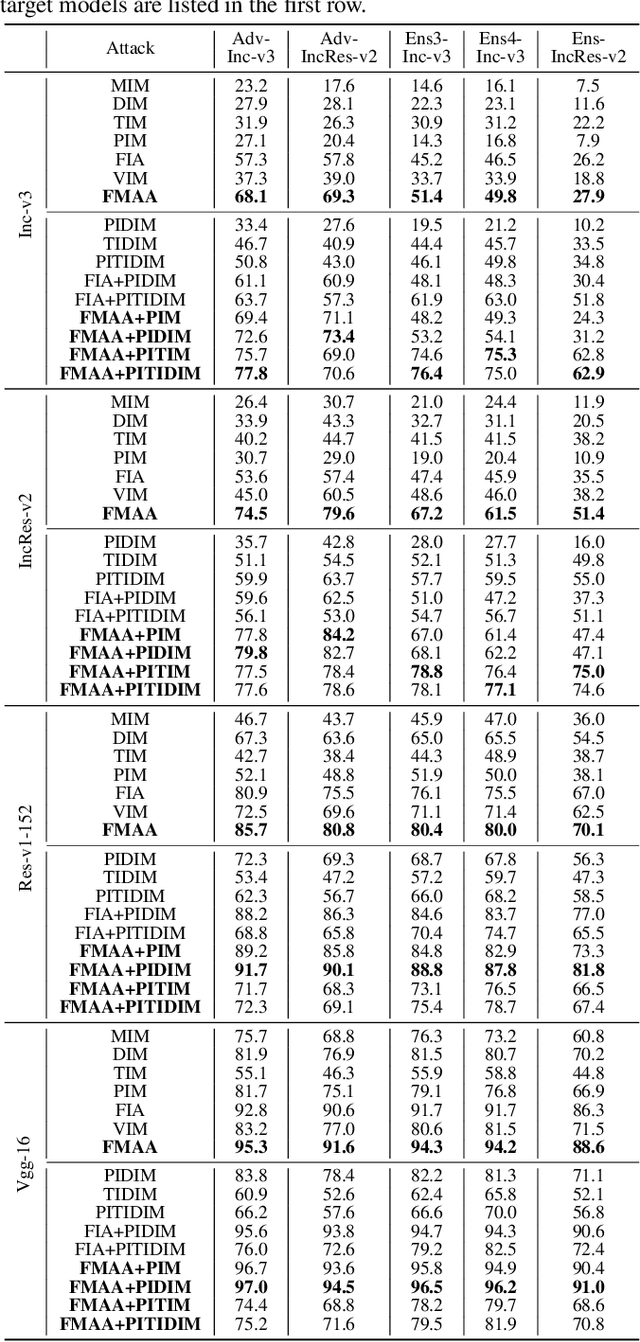
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.
Imperceptible Adversarial Examples for Fake Image Detection
Jun 03, 2021
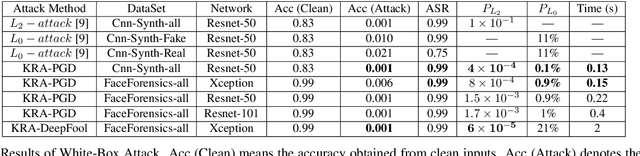

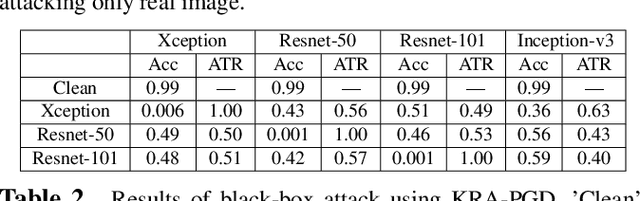
Fooling people with highly realistic fake images generated with Deepfake or GANs brings a great social disturbance to our society. Many methods have been proposed to detect fake images, but they are vulnerable to adversarial perturbations -- intentionally designed noises that can lead to the wrong prediction. Existing methods of attacking fake image detectors usually generate adversarial perturbations to perturb almost the entire image. This is redundant and increases the perceptibility of perturbations. In this paper, we propose a novel method to disrupt the fake image detection by determining key pixels to a fake image detector and attacking only the key pixels, which results in the $L_0$ and the $L_2$ norms of adversarial perturbations much less than those of existing works. Experiments on two public datasets with three fake image detectors indicate that our proposed method achieves state-of-the-art performance in both white-box and black-box attacks.
DFGC 2021: A DeepFake Game Competition
Jun 02, 2021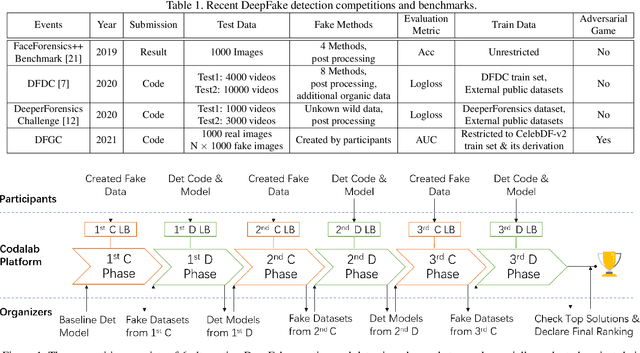
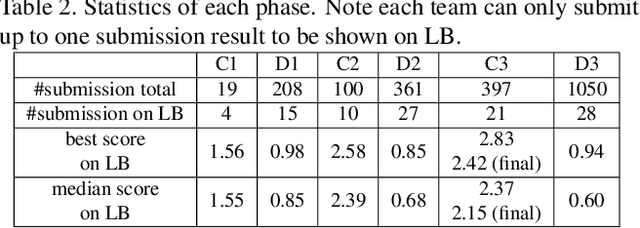

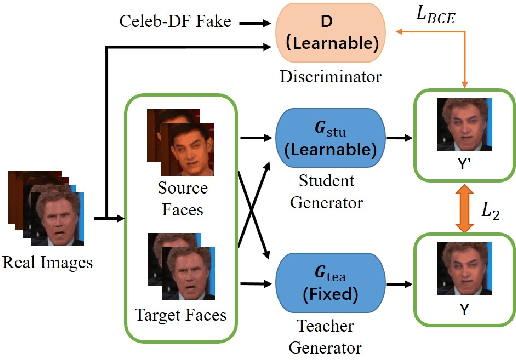
This paper presents a summary of the DFGC 2021 competition. DeepFake technology is developing fast, and realistic face-swaps are increasingly deceiving and hard to detect. At the same time, DeepFake detection methods are also improving. There is a two-party game between DeepFake creators and detectors. This competition provides a common platform for benchmarking the adversarial game between current state-of-the-art DeepFake creation and detection methods. In this paper, we present the organization, results and top solutions of this competition and also share our insights obtained during this event. We also release the DFGC-21 testing dataset collected from our participants to further benefit the research community.