 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaxuan Lu
Hypergraph-based Multi-View Action Recognition using Event Cameras
Mar 28, 2024


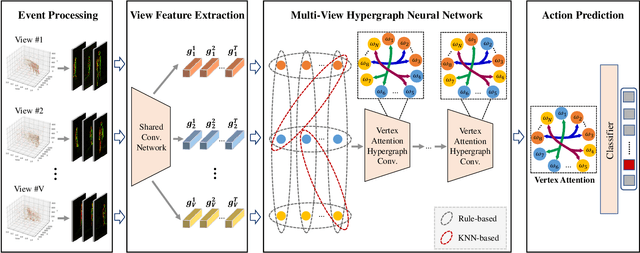

Action recognition from video data forms a cornerstone with wide-ranging applications. Single-view action recognition faces limitations due to its reliance on a single viewpoint. In contrast, multi-view approaches capture complementary information from various viewpoints for improved accuracy. Recently, event cameras have emerged as innovative bio-inspired sensors, leading to advancements in event-based action recognition. However, existing works predominantly focus on single-view scenarios, leaving a gap in multi-view event data exploitation, particularly in challenges like information deficit and semantic misalignment. To bridge this gap, we introduce HyperMV, a multi-view event-based action recognition framework. HyperMV converts discrete event data into frame-like representations and extracts view-related features using a shared convolutional network. By treating segments as vertices and constructing hyperedges using rule-based and KNN-based strategies, a multi-view hypergraph neural network that captures relationships across viewpoint and temporal features is established. The vertex attention hypergraph propagation is also introduced for enhanced feature fusion. To prompt research in this area, we present the largest multi-view event-based action dataset $\text{THU}^{\text{MV-EACT}}\text{-50}$, comprising 50 actions from 6 viewpoints, which surpasses existing datasets by over tenfold. Experimental results show that HyperMV significantly outperforms baselines in both cross-subject and cross-view scenarios, and also exceeds the state-of-the-arts in frame-based multi-view action recognition.
PathoTune: Adapting Visual Foundation Model to Pathological Specialists
Mar 25, 2024As natural image understanding moves towards the pretrain-finetune era, research in pathology imaging is concurrently evolving. Despite the predominant focus on pretraining pathological foundation models, how to adapt foundation models to downstream tasks is little explored. For downstream adaptation, we propose the existence of two domain gaps, i.e., the Foundation-Task Gap and the Task-Instance Gap. To mitigate these gaps, we introduce PathoTune, a framework designed to efficiently adapt pathological or even visual foundation models to pathology-specific tasks via multi-modal prompt tuning. The proposed framework leverages Task-specific Visual Prompts and Task-specific Textual Prompts to identify task-relevant features, along with Instance-specific Visual Prompts for encoding single pathological image features. Results across multiple datasets at both patch-level and WSI-level demonstrate its superior performance over single-modality prompt tuning approaches. Significantly, PathoTune facilitates the direct adaptation of natural visual foundation models to pathological tasks, drastically outperforming pathological foundation models with simple linear probing. The code will be available upon acceptance.
Immersive Text Game and Personality Classification
Mar 20, 2022
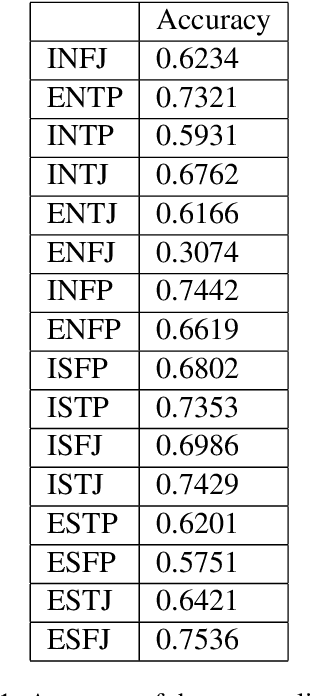
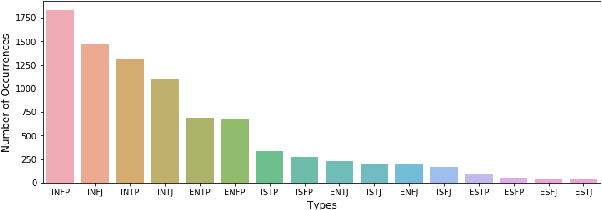
We designed and built a game called \textit{Immersive Text Game}, which allows the player to choose a story and a character, and interact with other characters in the story in an immersive manner of dialogues. The game is based on several latest models, including text generation language model, information extraction model, commonsense reasoning model, and psychology evaluation model. In the past, similar text games usually let players choose from limited actions instead of answering on their own, and not every time what characters said are determined by the player. Through the combination of these models and elaborate game mechanics and modes, the player will find some novel experiences as driven through the storyline.