 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJie Feng
SA-MixNet: Structure-aware Mixup and Invariance Learning for Scribble-supervised Road Extraction in Remote Sensing Images
Mar 03, 2024
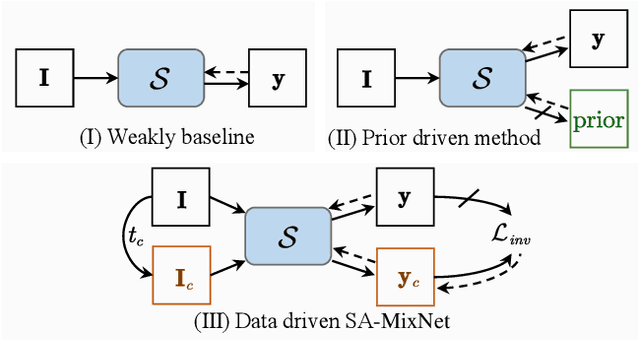
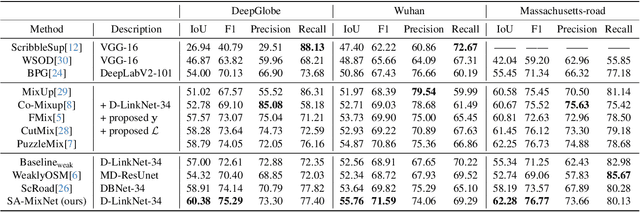
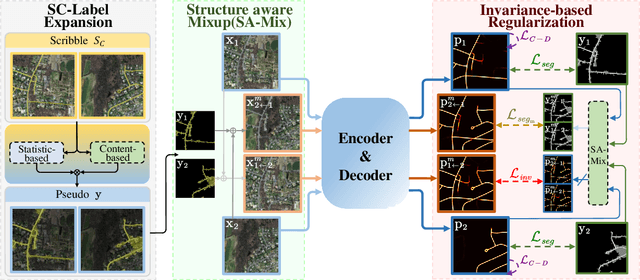
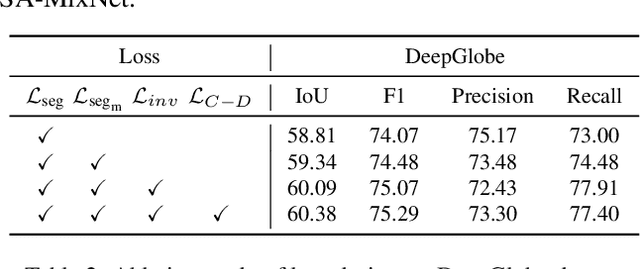
Mainstreamed weakly supervised road extractors rely on highly confident pseudo-labels propagated from scribbles, and their performance often degrades gradually as the image scenes tend various. We argue that such degradation is due to the poor model's invariance to scenes with different complexities, whereas existing solutions to this problem are commonly based on crafted priors that cannot be derived from scribbles. To eliminate the reliance on such priors, we propose a novel Structure-aware Mixup and Invariance Learning framework (SA-MixNet) for weakly supervised road extraction that improves the model invariance in a data-driven manner. Specifically, we design a structure-aware Mixup scheme to paste road regions from one image onto another for creating an image scene with increased complexity while preserving the road's structural integrity. Then an invariance regularization is imposed on the predictions of constructed and origin images to minimize their conflicts, which thus forces the model to behave consistently on various scenes. Moreover, a discriminator-based regularization is designed for enhancing the connectivity meanwhile preserving the structure of roads. Combining these designs, our framework demonstrates superior performance on the DeepGlobe, Wuhan, and Massachusetts datasets outperforming the state-of-the-art techniques by 1.47%, 2.12%, 4.09% respectively in IoU metrics, and showing its potential of plug-and-play. The code will be made publicly available.
UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction
Feb 19, 2024Urban spatio-temporal prediction is crucial for informed decision-making, such as transportation management, resource optimization, and urban planning. Although pretrained foundation models for natural languages have experienced remarkable breakthroughs, wherein one general-purpose model can tackle multiple tasks across various domains, urban spatio-temporal modeling lags behind. Existing approaches for urban prediction are usually tailored for specific spatio-temporal scenarios, requiring task-specific model designs and extensive in-domain training data. In this work, we propose a universal model, UniST, for urban spatio-temporal prediction. Drawing inspiration from large language models, UniST achieves success through: (i) flexibility towards diverse spatio-temporal data characteristics, (ii) effective generative pre-training with elaborated masking strategies to capture complex spatio-temporal relationships, (iii) spatio-temporal knowledge-guided prompts that align and leverage intrinsic and shared knowledge across scenarios. These designs together unlock the potential of a one-for-all model for spatio-temporal prediction with powerful generalization capability. Extensive experiments on 15 cities and 6 domains demonstrate the universality of UniST in advancing state-of-the-art prediction performance, especially in few-shot and zero-shot scenarios.
Global Convergence of Natural Policy Gradient with Hessian-aided Momentum Variance Reduction
Jan 02, 2024Natural policy gradient (NPG) and its variants are widely-used policy search methods in reinforcement learning. Inspired by prior work, a new NPG variant coined NPG-HM is developed in this paper, which utilizes the Hessian-aided momentum technique for variance reduction, while the sub-problem is solved via the stochastic gradient descent method. It is shown that NPG-HM can achieve the global last iterate $\epsilon$-optimality with a sample complexity of $\mathcal{O}(\epsilon^{-2})$, which is the best known result for natural policy gradient type methods under the generic Fisher non-degenerate policy parameterizations. The convergence analysis is built upon a relaxed weak gradient dominance property tailored for NPG under the compatible function approximation framework, as well as a neat way to decompose the error when handling the sub-problem. Moreover, numerical experiments on Mujoco-based environments demonstrate the superior performance of NPG-HM over other state-of-the-art policy gradient methods.
Urban Generative Intelligence (UGI): A Foundational Platform for Agents in Embodied City Environment
Dec 19, 2023Urban environments, characterized by their complex, multi-layered networks encompassing physical, social, economic, and environmental dimensions, face significant challenges in the face of rapid urbanization. These challenges, ranging from traffic congestion and pollution to social inequality, call for advanced technological interventions. Recent developments in big data, artificial intelligence, urban computing, and digital twins have laid the groundwork for sophisticated city modeling and simulation. However, a gap persists between these technological capabilities and their practical implementation in addressing urban challenges in an systemic-intelligent way. This paper proposes Urban Generative Intelligence (UGI), a novel foundational platform integrating Large Language Models (LLMs) into urban systems to foster a new paradigm of urban intelligence. UGI leverages CityGPT, a foundation model trained on city-specific multi-source data, to create embodied agents for various urban tasks. These agents, operating within a textual urban environment emulated by city simulator and urban knowledge graph, interact through a natural language interface, offering an open platform for diverse intelligent and embodied agent development. This platform not only addresses specific urban issues but also simulates complex urban systems, providing a multidisciplinary approach to understand and manage urban complexity. This work signifies a transformative step in city science and urban intelligence, harnessing the power of LLMs to unravel and address the intricate dynamics of urban systems. The code repository with demonstrations will soon be released here https://github.com/tsinghua-fib-lab/UGI.
IMJENSE: Scan-specific Implicit Representation for Joint Coil Sensitivity and Image Estimation in Parallel MRI
Nov 21, 2023Parallel imaging is a commonly used technique to accelerate magnetic resonance imaging (MRI) data acquisition. Mathematically, parallel MRI reconstruction can be formulated as an inverse problem relating the sparsely sampled k-space measurements to the desired MRI image. Despite the success of many existing reconstruction algorithms, it remains a challenge to reliably reconstruct a high-quality image from highly reduced k-space measurements. Recently, implicit neural representation has emerged as a powerful paradigm to exploit the internal information and the physics of partially acquired data to generate the desired object. In this study, we introduced IMJENSE, a scan-specific implicit neural representation-based method for improving parallel MRI reconstruction. Specifically, the underlying MRI image and coil sensitivities were modeled as continuous functions of spatial coordinates, parameterized by neural networks and polynomials, respectively. The weights in the networks and coefficients in the polynomials were simultaneously learned directly from sparsely acquired k-space measurements, without fully sampled ground truth data for training. Benefiting from the powerful continuous representation and joint estimation of the MRI image and coil sensitivities, IMJENSE outperforms conventional image or k-space domain reconstruction algorithms. With extremely limited calibration data, IMJENSE is more stable than supervised calibrationless and calibration-based deep-learning methods. Results show that IMJENSE robustly reconstructs the images acquired at 5$\mathbf{\times}$ and 6$\mathbf{\times}$ accelerations with only 4 or 8 calibration lines in 2D Cartesian acquisitions, corresponding to 22.0% and 19.5% undersampling rates. The high-quality results and scanning specificity make the proposed method hold the potential for further accelerating the data acquisition of parallel MRI.
Spatiotemporal implicit neural representation for unsupervised dynamic MRI reconstruction
Dec 31, 2022


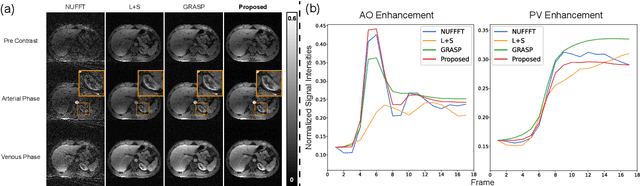
Supervised Deep-Learning (DL)-based reconstruction algorithms have shown state-of-the-art results for highly-undersampled dynamic Magnetic Resonance Imaging (MRI) reconstruction. However, the requirement of excessive high-quality ground-truth data hinders their applications due to the generalization problem. Recently, Implicit Neural Representation (INR) has appeared as a powerful DL-based tool for solving the inverse problem by characterizing the attributes of a signal as a continuous function of corresponding coordinates in an unsupervised manner. In this work, we proposed an INR-based method to improve dynamic MRI reconstruction from highly undersampled k-space data, which only takes spatiotemporal coordinates as inputs. Specifically, the proposed INR represents the dynamic MRI images as an implicit function and encodes them into neural networks. The weights of the network are learned from sparsely-acquired (k, t)-space data itself only, without external training datasets or prior images. Benefiting from the strong implicit continuity regularization of INR together with explicit regularization for low-rankness and sparsity, our proposed method outperforms the compared scan-specific methods at various acceleration factors. E.g., experiments on retrospective cardiac cine datasets show an improvement of 5.5 ~ 7.1 dB in PSNR for extremely high accelerations (up to 41.6-fold). The high-quality and inner continuity of the images provided by INR has great potential to further improve the spatiotemporal resolution of dynamic MRI, without the need of any training data.
Two-stage Contextual Transformer-based Convolutional Neural Network for Airway Extraction from CT Images
Dec 15, 2022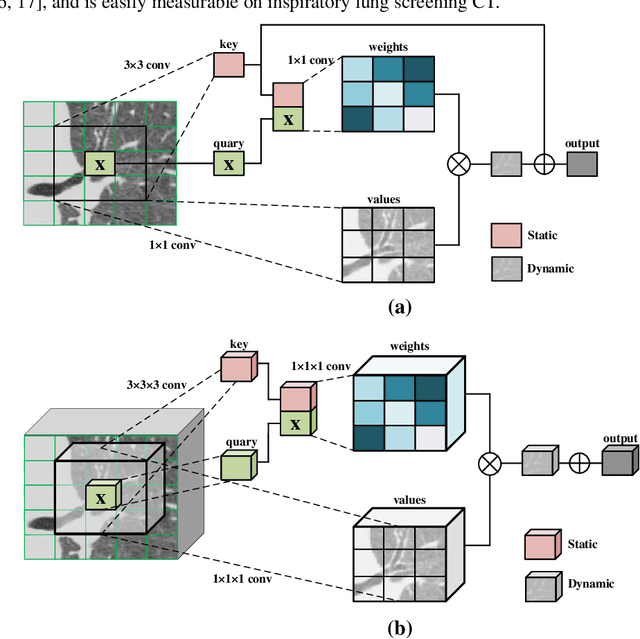



Accurate airway extraction from computed tomography (CT) images is a critical step for planning navigation bronchoscopy and quantitative assessment of airway-related chronic obstructive pulmonary disease (COPD). The existing methods are challenging to sufficiently segment the airway, especially the high-generation airway, with the constraint of the limited label and cannot meet the clinical use in COPD. We propose a novel two-stage 3D contextual transformer-based U-Net for airway segmentation using CT images. The method consists of two stages, performing initial and refined airway segmentation. The two-stage model shares the same subnetwork with different airway masks as input. Contextual transformer block is performed both in the encoder and decoder path of the subnetwork to finish high-quality airway segmentation effectively. In the first stage, the total airway mask and CT images are provided to the subnetwork, and the intrapulmonary airway mask and corresponding CT scans to the subnetwork in the second stage. Then the predictions of the two-stage method are merged as the final prediction. Extensive experiments were performed on in-house and multiple public datasets. Quantitative and qualitative analysis demonstrate that our proposed method extracted much more branches and lengths of the tree while accomplishing state-of-the-art airway segmentation performance. The code is available at https://github.com/zhaozsq/airway_segmentation.
SparseDet: Towards End-to-End 3D Object Detection
Jun 02, 2022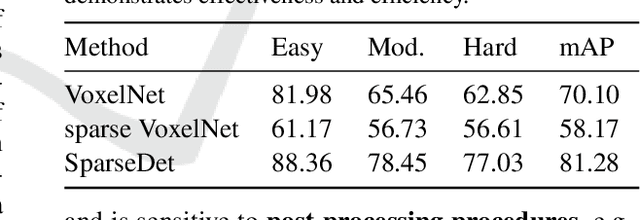

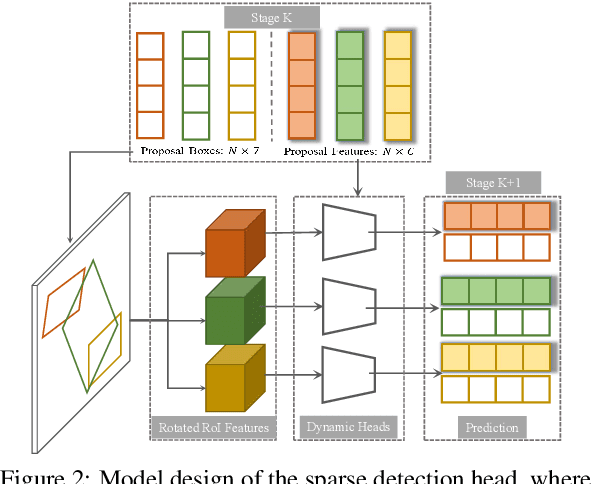
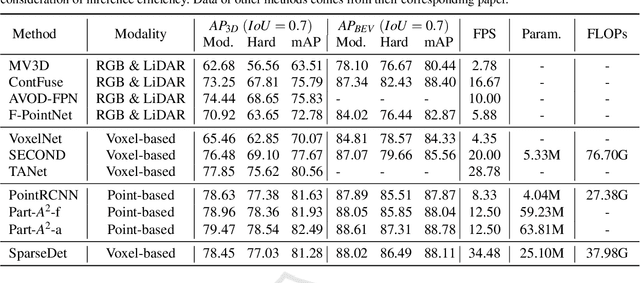
In this paper, we propose SparseDet for end-to-end 3D object detection from point cloud. Existing works on 3D object detection rely on dense object candidates over all locations in a 3D or 2D grid following the mainstream methods for object detection in 2D images. However, this dense paradigm requires expertise in data to fulfill the gap between label and detection. As a new detection paradigm, SparseDet maintains a fixed set of learnable proposals to represent latent candidates and directly perform classification and localization for 3D objects through stacked transformers. It demonstrates that effective 3D object detection can be achieved with none of post-processing such as redundant removal and non-maximum suppression. With a properly designed network, SparseDet achieves highly competitive detection accuracy while running with a more efficient speed of 34.5 FPS. We believe this end-to-end paradigm of SparseDet will inspire new thinking on the sparsity of 3D object detection.
One-shot Transfer Learning for Population Mapping
Aug 17, 2021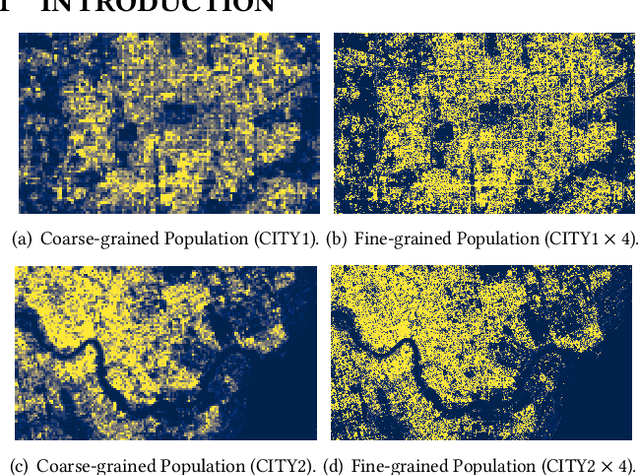
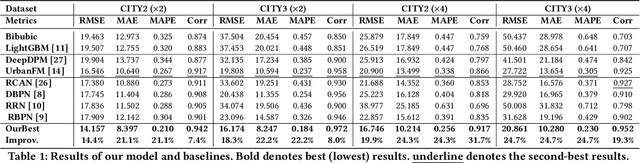

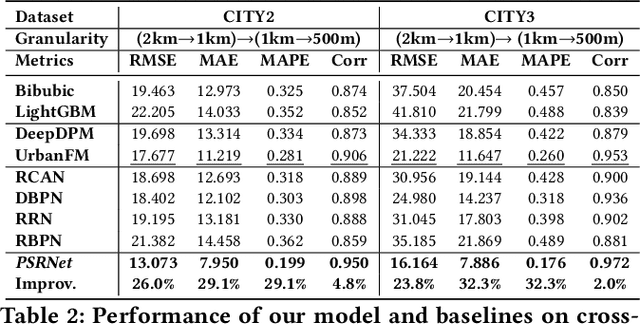
Fine-grained population distribution data is of great importance for many applications, e.g., urban planning, traffic scheduling, epidemic modeling, and risk control. However, due to the limitations of data collection, including infrastructure density, user privacy, and business security, such fine-grained data is hard to collect and usually, only coarse-grained data is available. Thus, obtaining fine-grained population distribution from coarse-grained distribution becomes an important problem. To tackle this problem, existing methods mainly rely on sufficient fine-grained ground truth for training, which is not often available for the majority of cities. That limits the applications of these methods and brings the necessity to transfer knowledge between data-sufficient source cities to data-scarce target cities. In knowledge transfer scenario, we employ single reference fine-grained ground truth in target city, which is easy to obtain via remote sensing or questionnaire, as the ground truth to inform the large-scale urban structure and support the knowledge transfer in target city. By this approach, we transform the fine-grained population mapping problem into a one-shot transfer learning problem. In this paper, we propose a novel one-shot transfer learning framework PSRNet to transfer spatial-temporal knowledge across cities from the view of network structure, the view of data, and the view of optimization. Experiments on real-life datasets of 4 cities demonstrate that PSRNet has significant advantages over 8 state-of-the-art baselines by reducing RMSE and MAE by more than 25%. Our code and datasets are released in Github (https://github.com/erzhuoshao/PSRNet-CIKM).
PAM: Understanding Product Images in Cross Product Category Attribute Extraction
Jun 08, 2021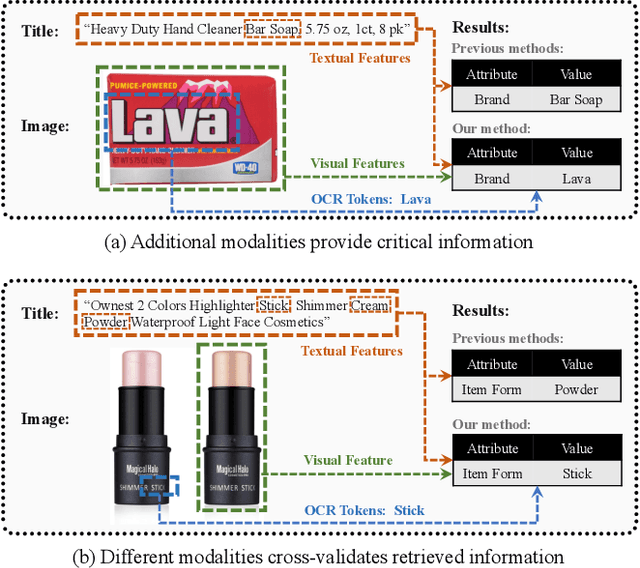
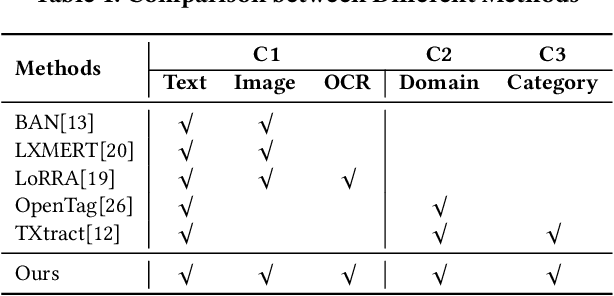

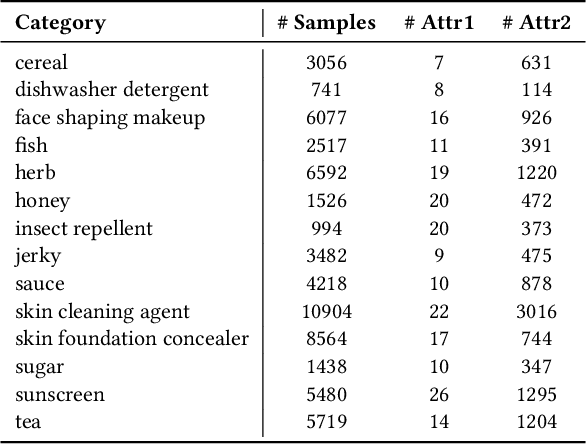
Understanding product attributes plays an important role in improving online shopping experience for customers and serves as an integral part for constructing a product knowledge graph. Most existing methods focus on attribute extraction from text description or utilize visual information from product images such as shape and color. Compared to the inputs considered in prior works, a product image in fact contains more information, represented by a rich mixture of words and visual clues with a layout carefully designed to impress customers. This work proposes a more inclusive framework that fully utilizes these different modalities for attribute extraction. Inspired by recent works in visual question answering, we use a transformer based sequence to sequence model to fuse representations of product text, Optical Character Recognition (OCR) tokens and visual objects detected in the product image. The framework is further extended with the capability to extract attribute value across multiple product categories with a single model, by training the decoder to predict both product category and attribute value and conditioning its output on product category. The model provides a unified attribute extraction solution desirable at an e-commerce platform that offers numerous product categories with a diverse body of product attributes. We evaluated the model on two product attributes, one with many possible values and one with a small set of possible values, over 14 product categories and found the model could achieve 15% gain on the Recall and 10% gain on the F1 score compared to existing methods using text-only features.