 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiedong Hao
DeepFirearm: Learning Discriminative Feature Representation for Fine-grained Firearm Retrieval
Jun 11, 2018

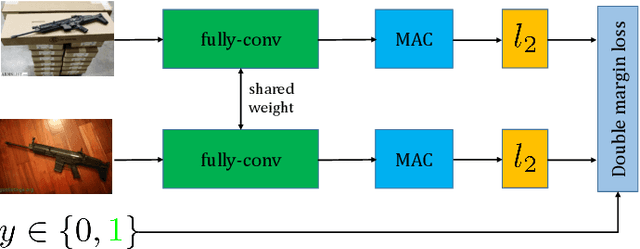
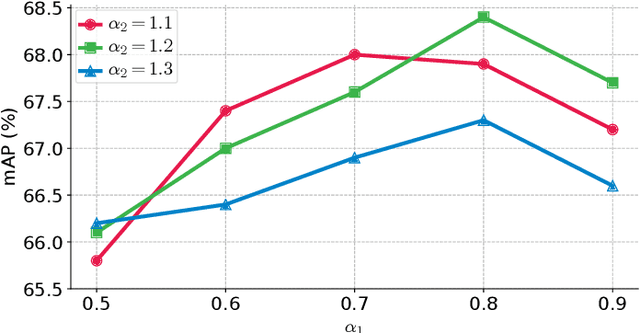
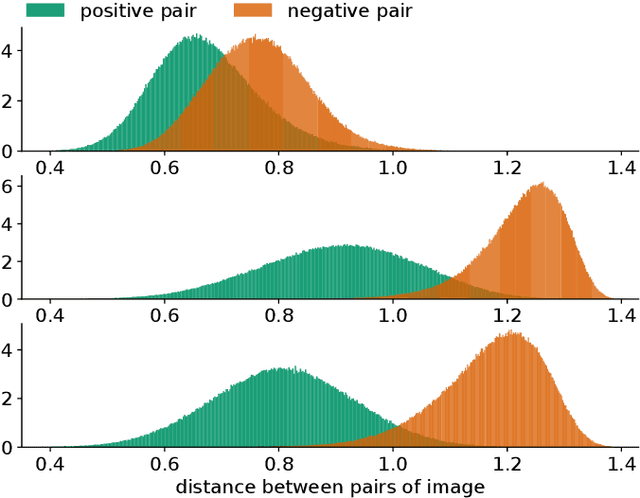
There are great demands for automatically regulating inappropriate appearance of shocking firearm images in social media or identifying firearm types in forensics. Image retrieval techniques have great potential to solve these problems. To facilitate research in this area, we introduce Firearm 14k, a large dataset consisting of over 14,000 images in 167 categories. It can be used for both fine-grained recognition and retrieval of firearm images. Recent advances in image retrieval are mainly driven by fine-tuning state-of-the-art convolutional neural networks for retrieval task. The conventional single margin contrastive loss, known for its simplicity and good performance, has been widely used. We find that it performs poorly on the Firearm 14k dataset due to: (1) Loss contributed by positive and negative image pairs is unbalanced during training process. (2) A huge domain gap exists between this dataset and ImageNet. We propose to deal with the unbalanced loss by employing a double margin contrastive loss. We tackle the domain gap issue with a two-stage training strategy, where we first fine-tune the network for classification, and then fine-tune it for retrieval. Experimental results show that our approach outperforms the conventional single margin approach by a large margin (up to 88.5% relative improvement) and even surpasses the strong triplet-loss-based approach.
What Is the Best Practice for CNNs Applied to Visual Instance Retrieval?
Nov 05, 2016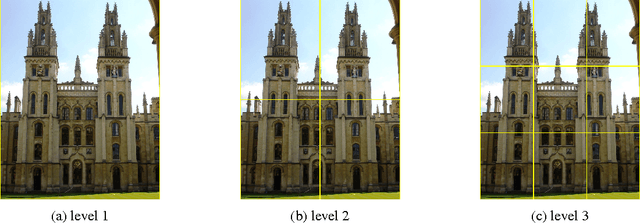

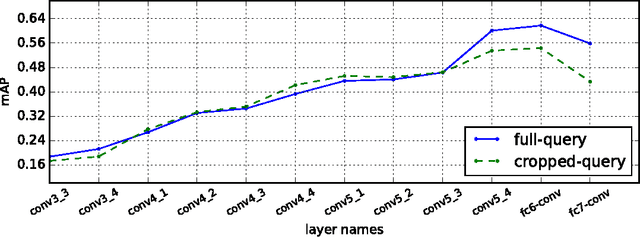
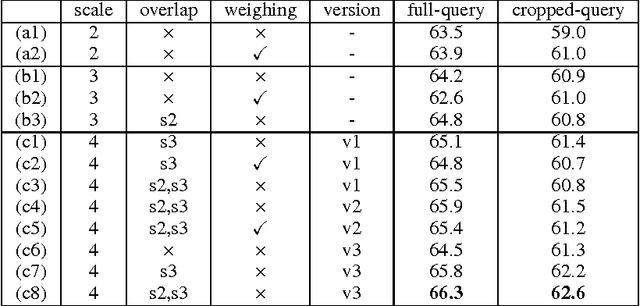
Previous work has shown that feature maps of deep convolutional neural networks (CNNs) can be interpreted as feature representation of a particular image region. Features aggregated from these feature maps have been exploited for image retrieval tasks and achieved state-of-the-art performances in recent years. The key to the success of such methods is the feature representation. However, the different factors that impact the effectiveness of features are still not explored thoroughly. There are much less discussion about the best combination of them. The main contribution of our paper is the thorough evaluations of the various factors that affect the discriminative ability of the features extracted from CNNs. Based on the evaluation results, we also identify the best choices for different factors and propose a new multi-scale image feature representation method to encode the image effectively. Finally, we show that the proposed method generalises well and outperforms the state-of-the-art methods on four typical datasets used for visual instance retrieval.