 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJieru Zhao
O2V-Mapping: Online Open-Vocabulary Mapping with Neural Implicit Representation
Apr 10, 2024
Online construction of open-ended language scenes is crucial for robotic applications, where open-vocabulary interactive scene understanding is required. Recently, neural implicit representation has provided a promising direction for online interactive mapping. However, implementing open-vocabulary scene understanding capability into online neural implicit mapping still faces three challenges: lack of local scene updating ability, blurry spatial hierarchical semantic segmentation and difficulty in maintaining multi-view consistency. To this end, we proposed O2V-mapping, which utilizes voxel-based language and geometric features to create an open-vocabulary field, thus allowing for local updates during online training process. Additionally, we leverage a foundational model for image segmentation to extract language features on object-level entities, achieving clear segmentation boundaries and hierarchical semantic features. For the purpose of preserving consistency in 3D object properties across different viewpoints, we propose a spatial adaptive voxel adjustment mechanism and a multi-view weight selection method. Extensive experiments on open-vocabulary object localization and semantic segmentation demonstrate that O2V-mapping achieves online construction of language scenes while enhancing accuracy, outperforming the previous SOTA method.
HGS-Mapping: Online Dense Mapping Using Hybrid Gaussian Representation in Urban Scenes
Mar 29, 2024
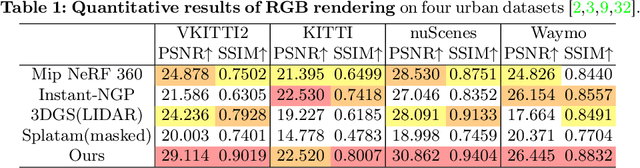


Online dense mapping of urban scenes forms a fundamental cornerstone for scene understanding and navigation of autonomous vehicles. Recent advancements in mapping methods are mainly based on NeRF, whose rendering speed is too slow to meet online requirements. 3D Gaussian Splatting (3DGS), with its rendering speed hundreds of times faster than NeRF, holds greater potential in online dense mapping. However, integrating 3DGS into a street-view dense mapping framework still faces two challenges, including incomplete reconstruction due to the absence of geometric information beyond the LiDAR coverage area and extensive computation for reconstruction in large urban scenes. To this end, we propose HGS-Mapping, an online dense mapping framework in unbounded large-scale scenes. To attain complete construction, our framework introduces Hybrid Gaussian Representation, which models different parts of the entire scene using Gaussians with distinct properties. Furthermore, we employ a hybrid Gaussian initialization mechanism and an adaptive update method to achieve high-fidelity and rapid reconstruction. To the best of our knowledge, we are the first to integrate Gaussian representation into online dense mapping of urban scenes. Our approach achieves SOTA reconstruction accuracy while only employing 66% number of Gaussians, leading to 20% faster reconstruction speed.
Hierarchical Source-to-Post-Route QoR Prediction in High-Level Synthesis with GNNs
Jan 14, 2024High-level synthesis (HLS) notably speeds up the hardware design process by avoiding RTL programming. However, the turnaround time of HLS increases significantly when post-route quality of results (QoR) are considered during optimization. To tackle this issue, we propose a hierarchical post-route QoR prediction approach for FPGA HLS, which features: (1) a modeling flow that directly estimates latency and post-route resource usage from C/C++ programs; (2) a graph construction method that effectively represents the control and data flow graph of source code and effects of HLS pragmas; and (3) a hierarchical GNN training and prediction method capable of capturing the impact of loop hierarchies. Experimental results show that our method presents a prediction error of less than 10% for different types of QoR metrics, which gains tremendous improvement compared with the state-of-the-art GNN methods. By adopting our proposed methodology, the runtime for design space exploration in HLS is shortened to tens of minutes and the achieved ADRS is reduced to 6.91% on average.
MARS: Exploiting Multi-Level Parallelism for DNN Workloads on Adaptive Multi-Accelerator Systems
Jul 23, 2023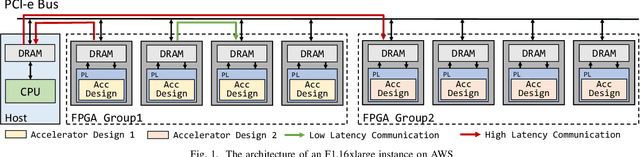
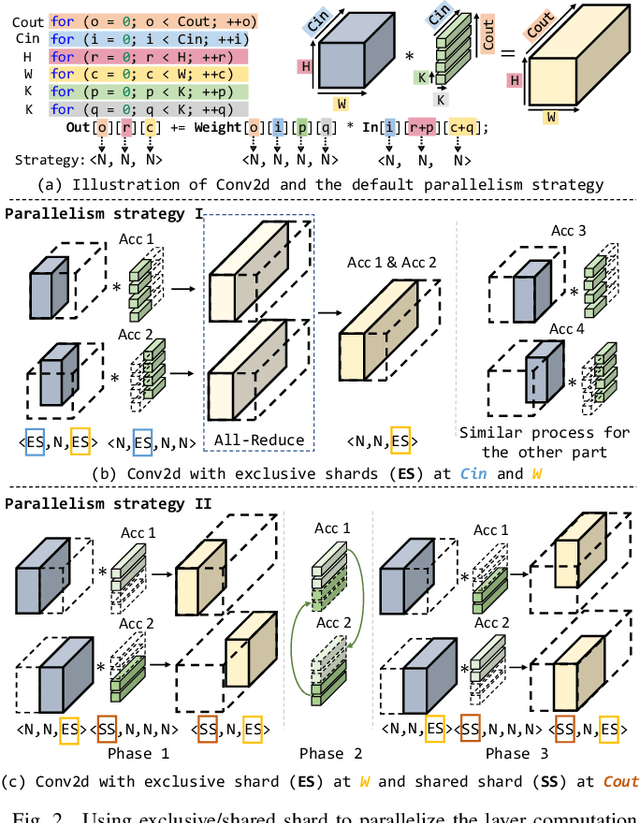
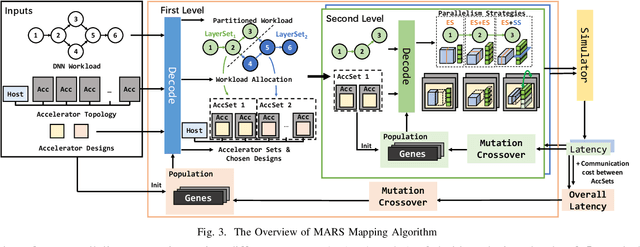
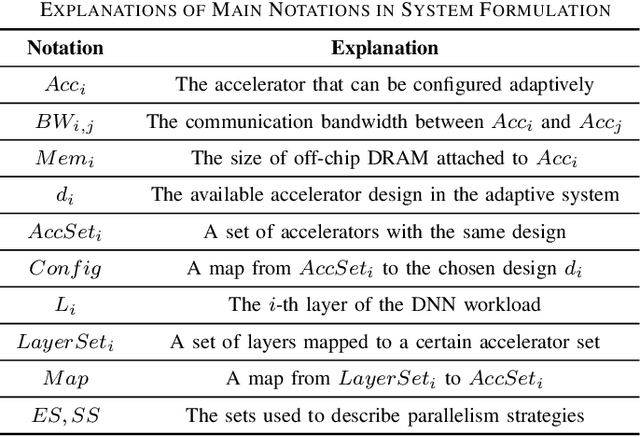
Along with the fast evolution of deep neural networks, the hardware system is also developing rapidly. As a promising solution achieving high scalability and low manufacturing cost, multi-accelerator systems widely exist in data centers, cloud platforms, and SoCs. Thus, a challenging problem arises in multi-accelerator systems: selecting a proper combination of accelerators from available designs and searching for efficient DNN mapping strategies. To this end, we propose MARS, a novel mapping framework that can perform computation-aware accelerator selection, and apply communication-aware sharding strategies to maximize parallelism. Experimental results show that MARS can achieve 32.2% latency reduction on average for typical DNN workloads compared to the baseline, and 59.4% latency reduction on heterogeneous models compared to the corresponding state-of-the-art method.
FlowMap: Path Generation for Automated Vehicles in Open Space Using Traffic Flow
May 11, 2023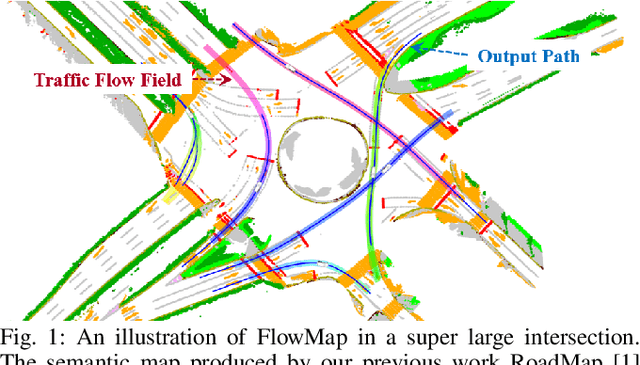
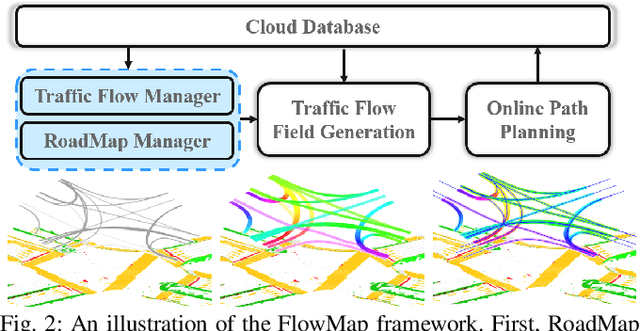

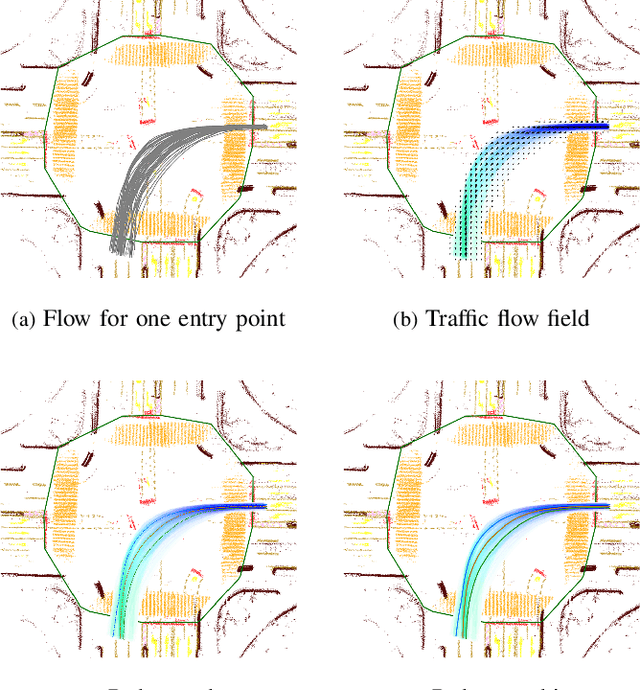
There is extensive literature on perceiving road structures by fusing various sensor inputs such as lidar point clouds and camera images using deep neural nets. Leveraging the latest advance of neural architects (such as transformers) and bird-eye-view (BEV) representation, the road cognition accuracy keeps improving. However, how to cognize the ``road'' for automated vehicles where there is no well-defined ``roads'' remains an open problem. For example, how to find paths inside intersections without HD maps is hard since there is neither an explicit definition for ``roads'' nor explicit features such as lane markings. The idea of this paper comes from a proverb: it becomes a way when people walk on it. Although there are no ``roads'' from sensor readings, there are ``roads'' from tracks of other vehicles. In this paper, we propose FlowMap, a path generation framework for automated vehicles based on traffic flows. FlowMap is built by extending our previous work RoadMap, a light-weight semantic map, with an additional traffic flow layer. A path generation algorithm on traffic flow fields (TFFs) is proposed to generate human-like paths. The proposed framework is validated using real-world driving data and is amenable to generating paths for super complicated intersections without using HD maps.
SALO: An Efficient Spatial Accelerator Enabling Hybrid Sparse Attention Mechanisms for Long Sequences
Jun 29, 2022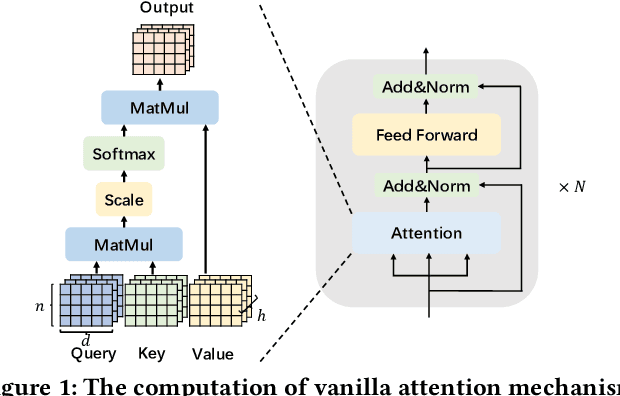
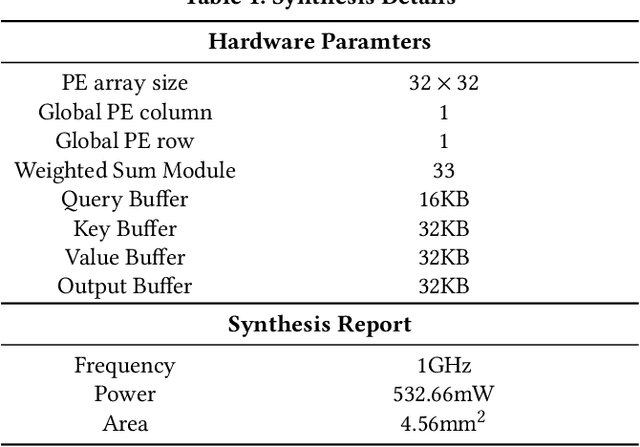
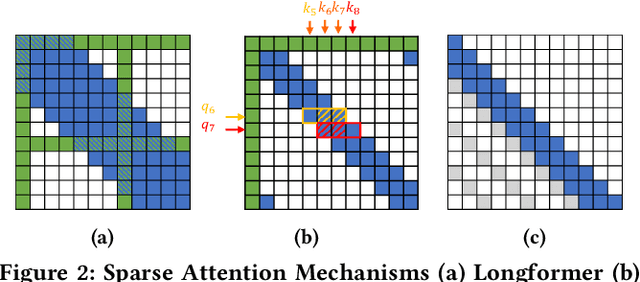
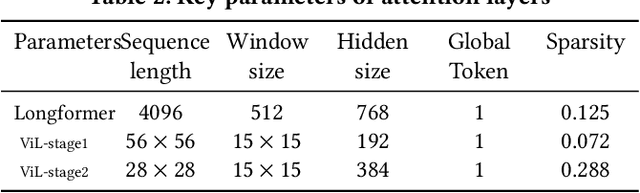
The attention mechanisms of transformers effectively extract pertinent information from the input sequence. However, the quadratic complexity of self-attention w.r.t the sequence length incurs heavy computational and memory burdens, especially for tasks with long sequences. Existing accelerators face performance degradation in these tasks. To this end, we propose SALO to enable hybrid sparse attention mechanisms for long sequences. SALO contains a data scheduler to map hybrid sparse attention patterns onto hardware and a spatial accelerator to perform the efficient attention computation. We show that SALO achieves 17.66x and 89.33x speedup on average compared to GPU and CPU implementations, respectively, on typical workloads, i.e., Longformer and ViL.
PowerGear: Early-Stage Power Estimation in FPGA HLS via Heterogeneous Edge-Centric GNNs
Jan 25, 2022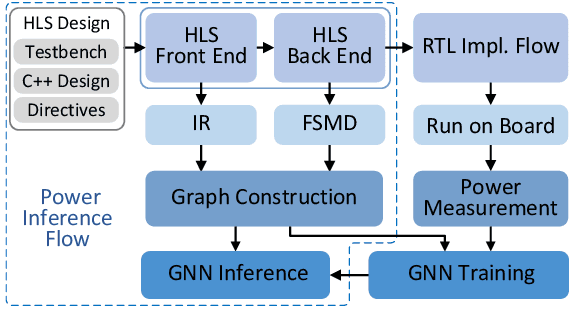
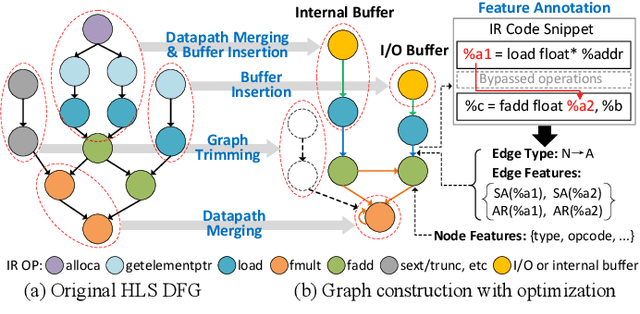

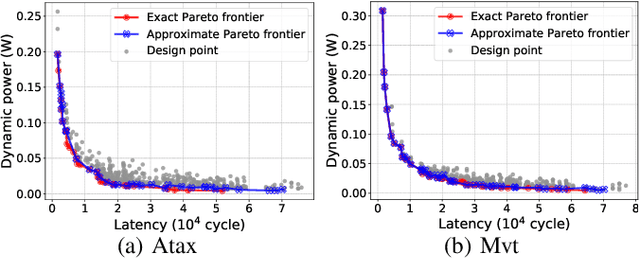
Power estimation is the basis of many hardware optimization strategies. However, it is still challenging to offer accurate power estimation at an early stage such as high-level synthesis (HLS). In this paper, we propose PowerGear, a graph-learning-assisted power estimation approach for FPGA HLS, which features high accuracy, efficiency and transferability. PowerGear comprises two main components: a graph construction flow and a customized graph neural network (GNN) model. Specifically, in the graph construction flow, we introduce buffer insertion, datapath merging, graph trimming and feature annotation techniques to transform HLS designs into graph-structured data, which encode both intra-operation micro-architectures and inter-operation interconnects annotated with switching activities. Furthermore, we propose a novel power-aware heterogeneous edge-centric GNN model which effectively learns heterogeneous edge semantics and structural properties of the constructed graphs via edge-centric neighborhood aggregation, and fits the formulation of dynamic power. Compared with on-board measurement, PowerGear estimates total and dynamic power for new HLS designs with errors of 3.60% and 8.81%, respectively, which outperforms the prior arts in research and the commercial product Vivado. In addition, PowerGear demonstrates a speedup of 4x over Vivado power estimator. Finally, we present a case study in which PowerGear is exploited to facilitate design space exploration for FPGA HLS, leading to a performance gain of up to 11.2%, compared with methods using state-of-the-art predictive models.
FP-Stereo: Hardware-Efficient Stereo Vision for Embedded Applications
Jul 01, 2020
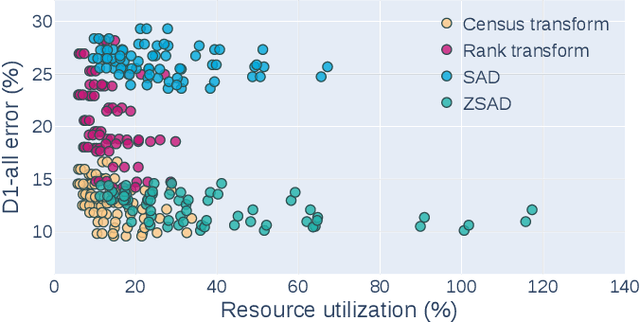
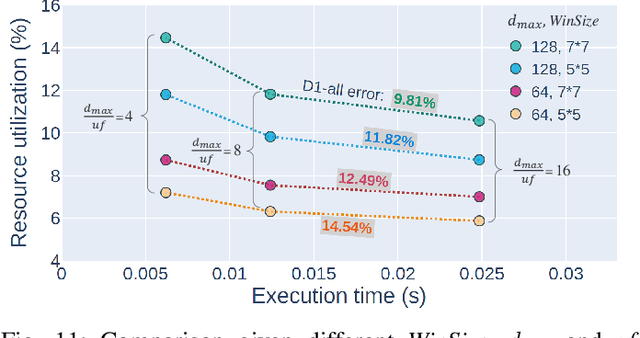
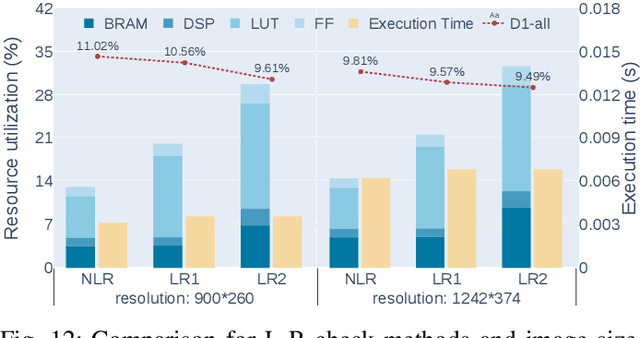
Fast and accurate depth estimation, or stereo matching, is essential in embedded stereo vision systems, requiring substantial design effort to achieve an appropriate balance among accuracy, speed and hardware cost. To reduce the design effort and achieve the right balance, we propose FP-Stereo for building high-performance stereo matching pipelines on FPGAs automatically. FP-Stereo consists of an open-source hardware-efficient library, allowing designers to obtain the desired implementation instantly. Diverse methods are supported in our library for each stage of the stereo matching pipeline and a series of techniques are developed to exploit the parallelism and reduce the resource overhead. To improve the usability, FP-Stereo can generate synthesizable C code of the FPGA accelerator with our optimized HLS templates automatically. To guide users for the right design choice meeting specific application requirements, detailed comparisons are performed on various configurations of our library to investigate the accuracy/speed/cost trade-off. Experimental results also show that FP-Stereo outperforms the state-of-the-art FPGA design from all aspects, including 6.08% lower error, 2x faster speed, 30% less resource usage and 40% less energy consumption. Compared to GPU designs, FP-Stereo achieves the same accuracy at a competitive speed while consuming much less energy.
Machine Learning Based Routing Congestion Prediction in FPGA High-Level Synthesis
May 06, 2019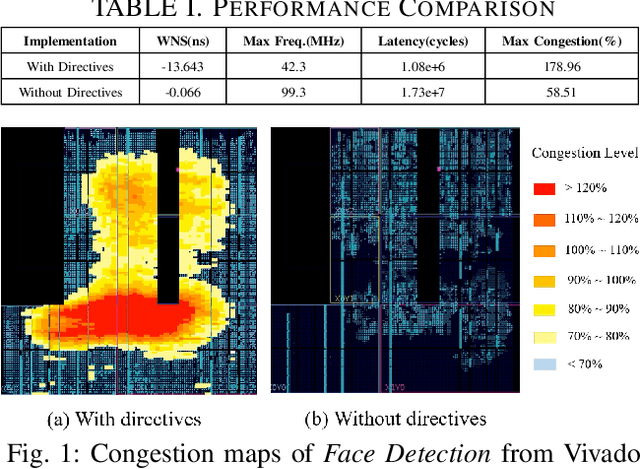
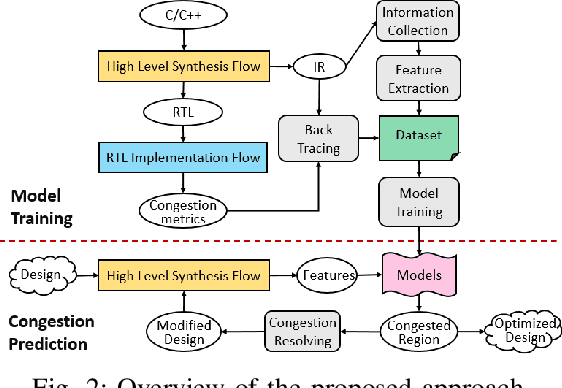
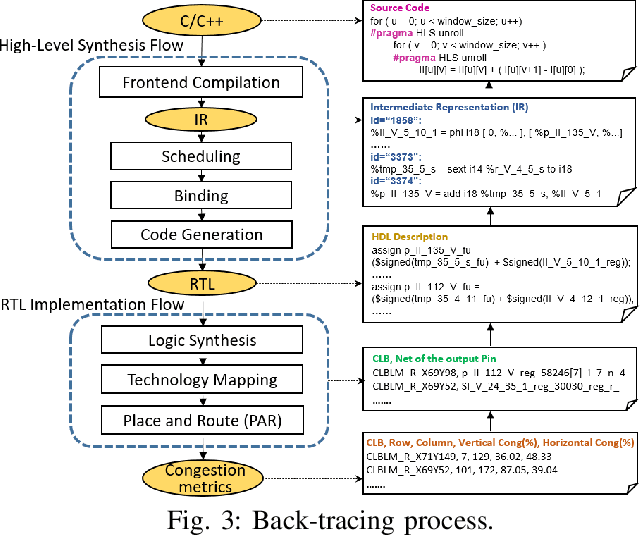

High-level synthesis (HLS) shortens the development time of hardware designs and enables faster design space exploration at a higher abstraction level. Optimization of complex applications in HLS is challenging due to the effects of implementation issues such as routing congestion. Routing congestion estimation is absent or inaccurate in existing HLS design methods and tools. Early and accurate congestion estimation is of great benefit to guide the optimization in HLS and improve the efficiency of implementation. However, routability, a serious concern in FPGA designs, has been difficult to evaluate in HLS without analyzing post-implementation details after Place and Route. To this end, we propose a novel method to predict routing congestion in HLS using machine learning and map the expected congested regions in the design to the relevant high-level source code. This is greatly beneficial in early identification of routability oriented bottlenecks in the high-level source code without running time-consuming register-transfer level (RTL) implementation flow. Experiments demonstrate that our approach accurately estimates vertical and horizontal routing congestion with errors of 6.71% and 10.05% respectively. By presenting Face Detection application as a case study, we show that by discovering the bottlenecks in high-level source code, routing congestion can be easily and quickly resolved compared to the efforts involved in RTL implementation and design feedback.