 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingwen Leng
Fovea Transformer: Efficient Long-Context Modeling with Structured Fine-to-Coarse Attention
Nov 13, 2023
The quadratic complexity of self-attention in Transformers has hindered the processing of long text. To alleviate this problem, previous works have proposed to sparsify the attention matrix, taking advantage of the observation that crucial information about a token can be derived from its neighbors. These methods typically combine one or another form of local attention and global attention. Such combinations introduce abrupt changes in contextual granularity when going from local to global, which may be undesirable. We believe that a smoother transition could potentially enhance model's ability to capture long-context dependencies. In this study, we introduce Fovea Transformer, a long-context focused transformer that addresses the challenges of capturing global dependencies while maintaining computational efficiency. To achieve this, we construct a multi-scale tree from the input sequence, and use representations of context tokens with a progressively coarser granularity in the tree, as their distance to the query token increases. We evaluate our model on three long-context summarization tasks\footnote{Our code is publicly available at: \textit{https://github.com/ZiweiHe/Fovea-Transformer}}. It achieves state-of-the-art performance on two of them, and competitive results on the third with mixed improvement and setback of the evaluation metrics.
Accelerating Generic Graph Neural Networks via Architecture, Compiler, Partition Method Co-Design
Aug 16, 2023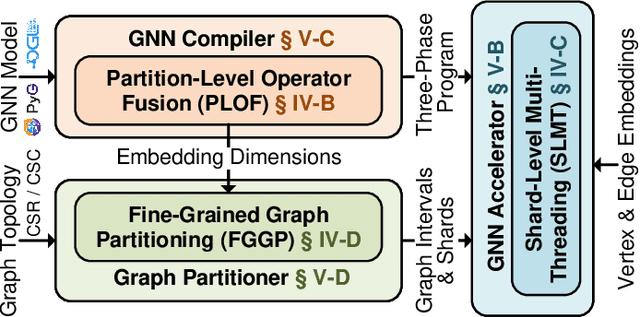
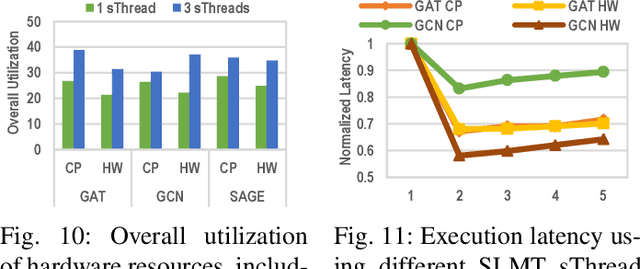

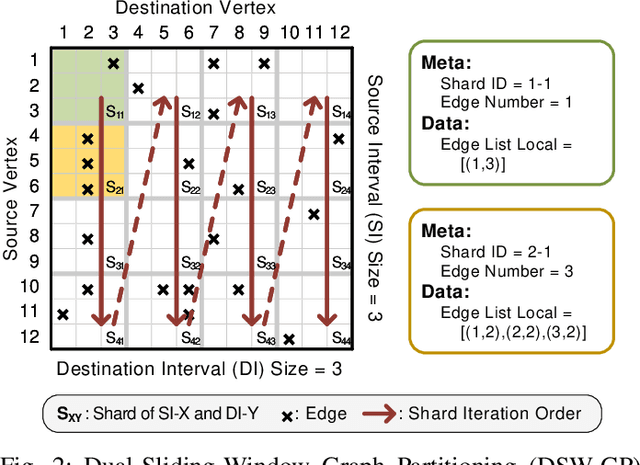
Graph neural networks (GNNs) have shown significant accuracy improvements in a variety of graph learning domains, sparking considerable research interest. To translate these accuracy improvements into practical applications, it is essential to develop high-performance and efficient hardware acceleration for GNN models. However, designing GNN accelerators faces two fundamental challenges: the high bandwidth requirement of GNN models and the diversity of GNN models. Previous works have addressed the first challenge by using more expensive memory interfaces to achieve higher bandwidth. For the second challenge, existing works either support specific GNN models or have generic designs with poor hardware utilization. In this work, we tackle both challenges simultaneously. First, we identify a new type of partition-level operator fusion, which we utilize to internally reduce the high bandwidth requirement of GNNs. Next, we introduce partition-level multi-threading to schedule the concurrent processing of graph partitions, utilizing different hardware resources. To further reduce the extra on-chip memory required by multi-threading, we propose fine-grained graph partitioning to generate denser graph partitions. Importantly, these three methods make no assumptions about the targeted GNN models, addressing the challenge of model variety. We implement these methods in a framework called SwitchBlade, consisting of a compiler, a graph partitioner, and a hardware accelerator. Our evaluation demonstrates that SwitchBlade achieves an average speedup of $1.85\times$ and energy savings of $19.03\times$ compared to the NVIDIA V100 GPU. Additionally, SwitchBlade delivers performance comparable to state-of-the-art specialized accelerators.
AdaptGear: Accelerating GNN Training via Adaptive Subgraph-Level Kernels on GPUs
May 27, 2023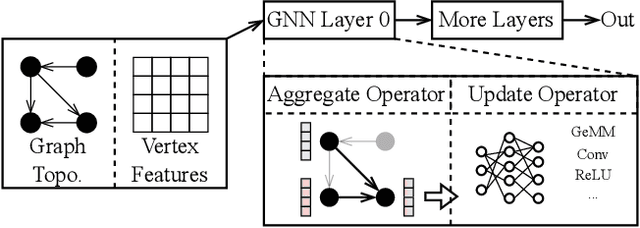
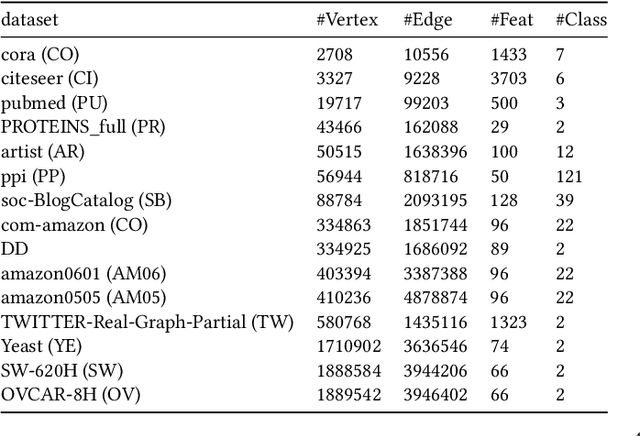
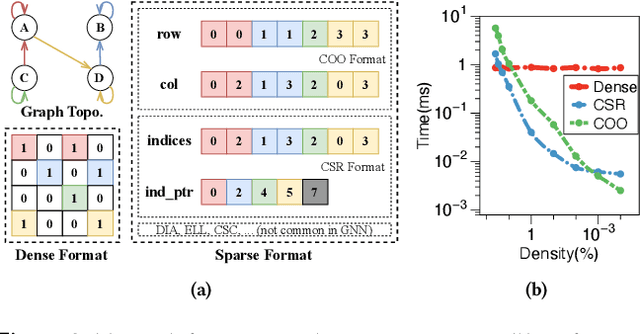

Graph neural networks (GNNs) are powerful tools for exploring and learning from graph structures and features. As such, achieving high-performance execution for GNNs becomes crucially important. Prior works have proposed to explore the sparsity (i.e., low density) in the input graph to accelerate GNNs, which uses the full-graph-level or block-level sparsity format. We show that they fail to balance the sparsity benefit and kernel execution efficiency. In this paper, we propose a novel system, referred to as AdaptGear, that addresses the challenge of optimizing GNNs performance by leveraging kernels tailored to the density characteristics at the subgraph level. Meanwhile, we also propose a method that dynamically chooses the optimal set of kernels for a given input graph. Our evaluation shows that AdaptGear can achieve a significant performance improvement, up to $6.49 \times$ ($1.87 \times$ on average), over the state-of-the-art works on two mainstream NVIDIA GPUs across various datasets.
Fourier Transformer: Fast Long Range Modeling by Removing Sequence Redundancy with FFT Operator
May 24, 2023
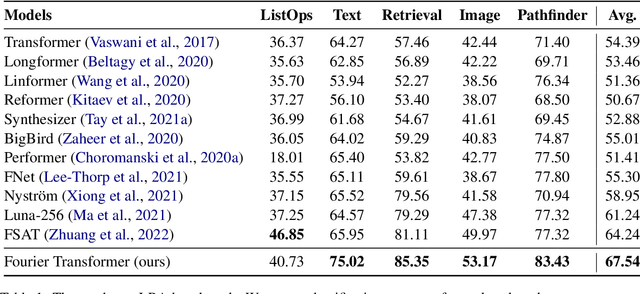
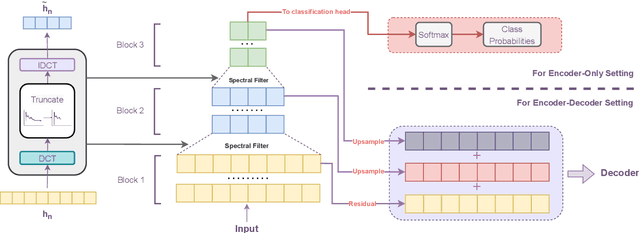
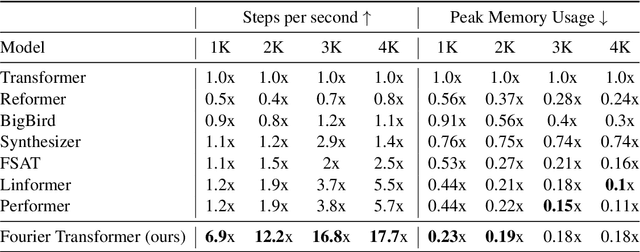
The transformer model is known to be computationally demanding, and prohibitively costly for long sequences, as the self-attention module uses a quadratic time and space complexity with respect to sequence length. Many researchers have focused on designing new forms of self-attention or introducing new parameters to overcome this limitation, however a large portion of them prohibits the model to inherit weights from large pretrained models. In this work, the transformer's inefficiency has been taken care of from another perspective. We propose Fourier Transformer, a simple yet effective approach by progressively removing redundancies in hidden sequence using the ready-made Fast Fourier Transform (FFT) operator to perform Discrete Cosine Transformation (DCT). Fourier Transformer is able to significantly reduce computational costs while retain the ability to inherit from various large pretrained models. Experiments show that our model achieves state-of-the-art performances among all transformer-based models on the long-range modeling benchmark LRA with significant improvement in both speed and space. For generative seq-to-seq tasks including CNN/DailyMail and ELI5, by inheriting the BART weights our model outperforms the standard BART and other efficient models. \footnote{Our code is publicly available at \url{https://github.com/LUMIA-Group/FourierTransformer}}
Nesting Forward Automatic Differentiation for Memory-Efficient Deep Neural Network Training
Sep 22, 2022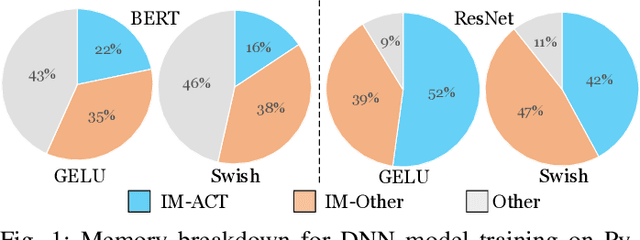
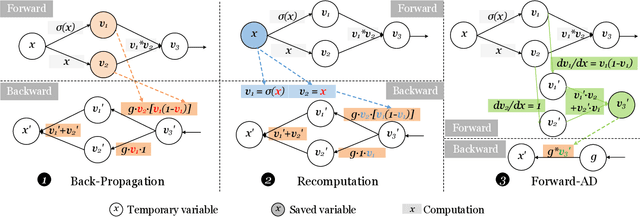

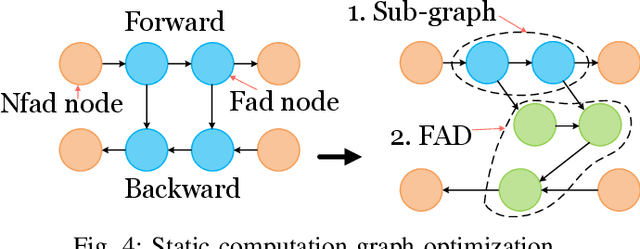
An activation function is an element-wise mathematical function and plays a crucial role in deep neural networks (DNN). Many novel and sophisticated activation functions have been proposed to improve the DNN accuracy but also consume massive memory in the training process with back-propagation. In this study, we propose the nested forward automatic differentiation (Forward-AD), specifically for the element-wise activation function for memory-efficient DNN training. We deploy nested Forward-AD in two widely-used deep learning frameworks, TensorFlow and PyTorch, which support the static and dynamic computation graph, respectively. Our evaluation shows that nested Forward-AD reduces the memory footprint by up to 1.97x than the baseline model and outperforms the recomputation by 20% under the same memory reduction ratio.
ANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization
Aug 30, 2022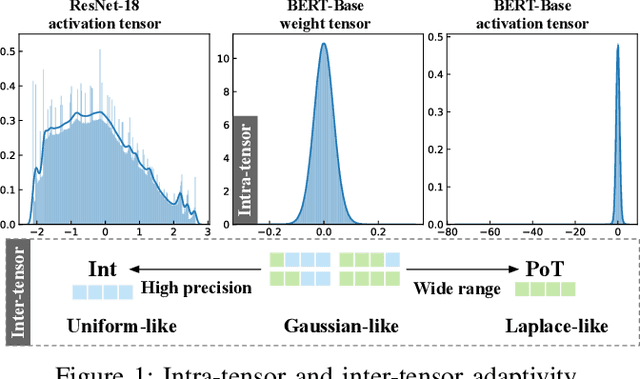
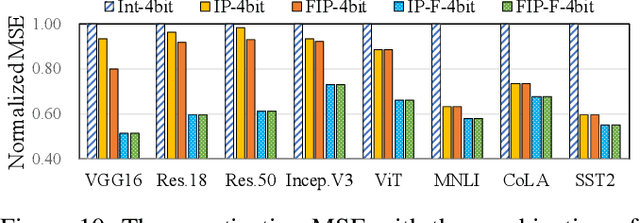
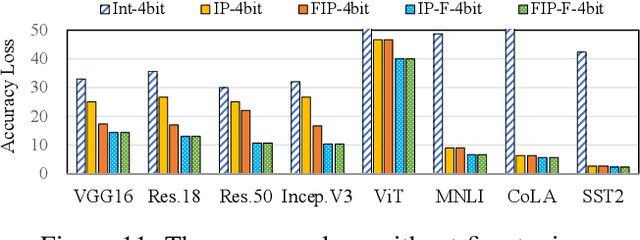
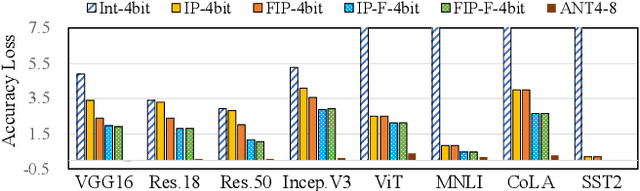
Quantization is a technique to reduce the computation and memory cost of DNN models, which are getting increasingly large. Existing quantization solutions use fixed-point integer or floating-point types, which have limited benefits, as both require more bits to maintain the accuracy of original models. On the other hand, variable-length quantization uses low-bit quantization for normal values and high-precision for a fraction of outlier values. Even though this line of work brings algorithmic benefits, it also introduces significant hardware overheads due to variable-length encoding and decoding. In this work, we propose a fixed-length adaptive numerical data type called ANT to achieve low-bit quantization with tiny hardware overheads. Our data type ANT leverages two key innovations to exploit the intra-tensor and inter-tensor adaptive opportunities in DNN models. First, we propose a particular data type, flint, that combines the advantages of float and int for adapting to the importance of different values within a tensor. Second, we propose an adaptive framework that selects the best type for each tensor according to its distribution characteristics. We design a unified processing element architecture for ANT and show its ease of integration with existing DNN accelerators. Our design results in 2.8$\times$ speedup and 2.5$\times$ energy efficiency improvement over the state-of-the-art quantization accelerators.
Efficient Activation Quantization via Adaptive Rounding Border for Post-Training Quantization
Aug 25, 2022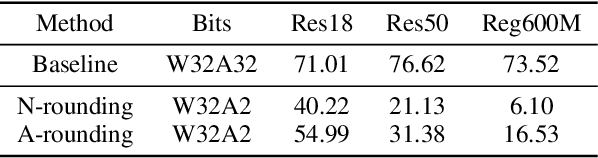

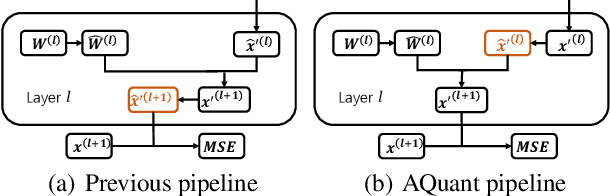
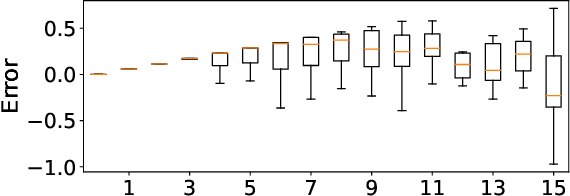
Post-training quantization (PTQ) attracts increasing attention due to its convenience in deploying quantized neural networks. Rounding, the primary source of quantization error, is optimized only for model weights, while activations still use the rounding-to-nearest operation. In this work, for the first time, we demonstrate that well-chosen rounding schemes for activations can improve the final accuracy. To deal with the challenge of the dynamicity of the activation rounding scheme, we adaptively adjust the rounding border through a simple function to generate rounding schemes at the inference stage. The border function covers the impact of weight errors, activation errors, and propagated errors to eliminate the bias of the element-wise error, which further benefits model accuracy. We also make the border aware of global errors to better fit different arriving activations. Finally, we propose the AQuant framework to learn the border function. Extensive experiments show that AQuant achieves noticeable improvements with negligible overhead compared with state-of-the-art works and pushes the accuracy of ResNet-18 up to 60.3\% under the 2-bit weight and activation post-training quantization.
SALO: An Efficient Spatial Accelerator Enabling Hybrid Sparse Attention Mechanisms for Long Sequences
Jun 29, 2022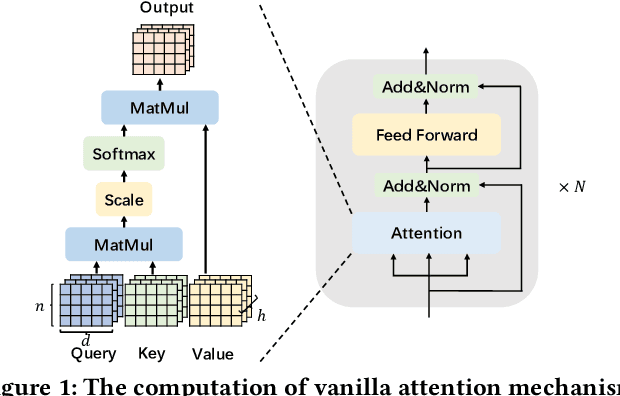
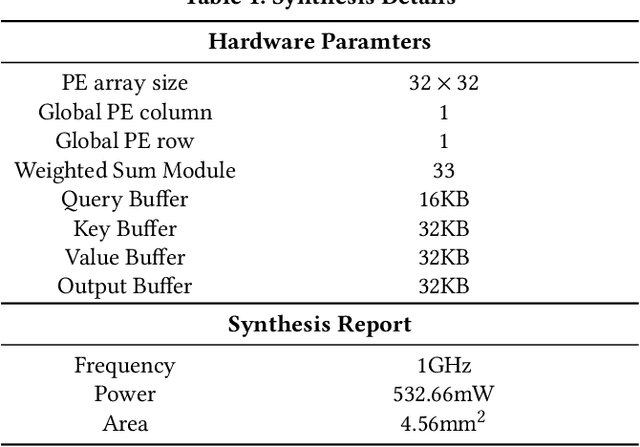
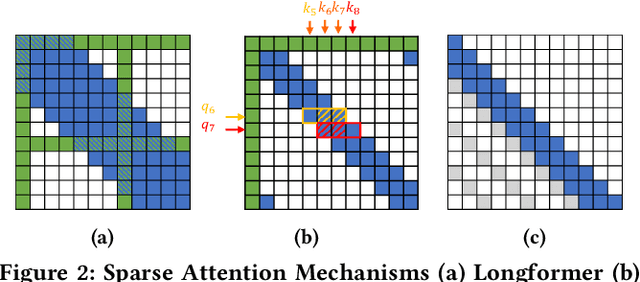
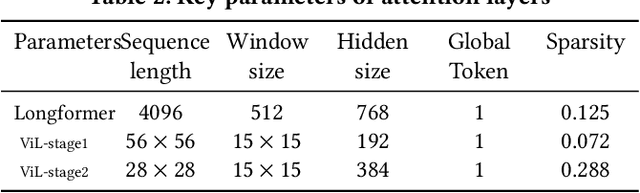
The attention mechanisms of transformers effectively extract pertinent information from the input sequence. However, the quadratic complexity of self-attention w.r.t the sequence length incurs heavy computational and memory burdens, especially for tasks with long sequences. Existing accelerators face performance degradation in these tasks. To this end, we propose SALO to enable hybrid sparse attention mechanisms for long sequences. SALO contains a data scheduler to map hybrid sparse attention patterns onto hardware and a spatial accelerator to perform the efficient attention computation. We show that SALO achieves 17.66x and 89.33x speedup on average compared to GPU and CPU implementations, respectively, on typical workloads, i.e., Longformer and ViL.
Transkimmer: Transformer Learns to Layer-wise Skim
May 15, 2022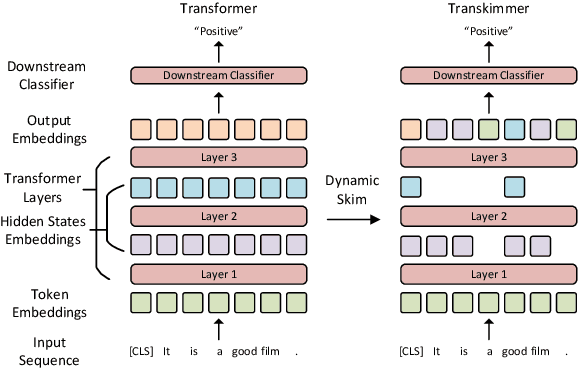
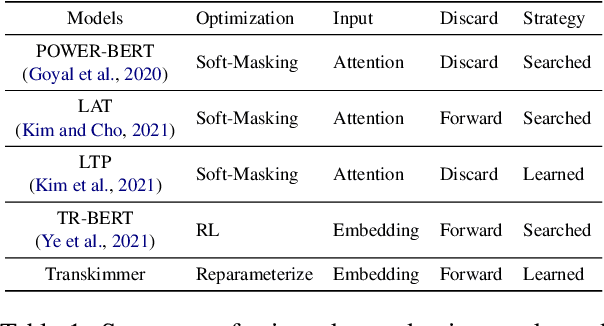
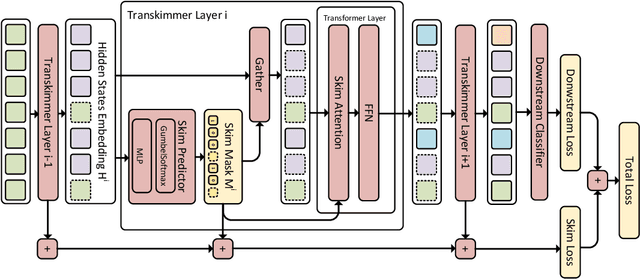

Transformer architecture has become the de-facto model for many machine learning tasks from natural language processing and computer vision. As such, improving its computational efficiency becomes paramount. One of the major computational inefficiency of Transformer-based models is that they spend the identical amount of computation throughout all layers. Prior works have proposed to augment the Transformer model with the capability of skimming tokens to improve its computational efficiency. However, they suffer from not having effectual and end-to-end optimization of the discrete skimming predictor. To address the above limitations, we propose the Transkimmer architecture, which learns to identify hidden state tokens that are not required by each layer. The skimmed tokens are then forwarded directly to the final output, thus reducing the computation of the successive layers. The key idea in Transkimmer is to add a parameterized predictor before each layer that learns to make the skimming decision. We also propose to adopt reparameterization trick and add skim loss for the end-to-end training of Transkimmer. Transkimmer achieves 10.97x average speedup on GLUE benchmark compared with vanilla BERT-base baseline with less than 1% accuracy degradation.
SQuant: On-the-Fly Data-Free Quantization via Diagonal Hessian Approximation
Feb 14, 2022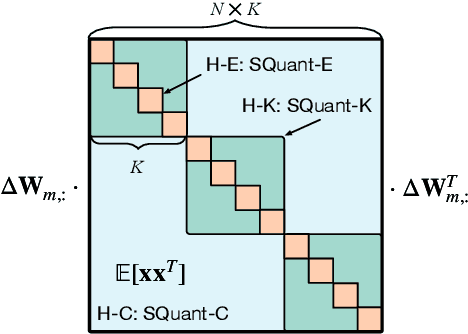
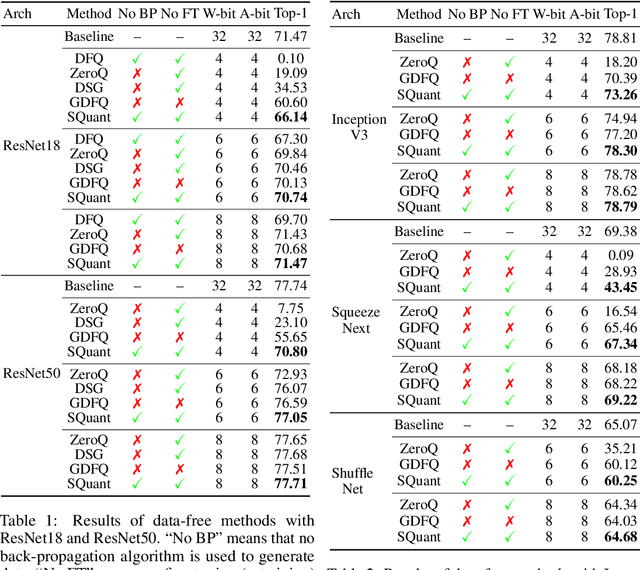
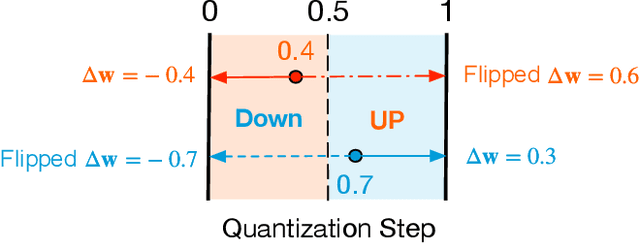
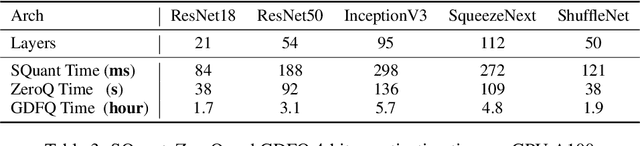
Quantization of deep neural networks (DNN) has been proven effective for compressing and accelerating DNN models. Data-free quantization (DFQ) is a promising approach without the original datasets under privacy-sensitive and confidential scenarios. However, current DFQ solutions degrade accuracy, need synthetic data to calibrate networks, and are time-consuming and costly. This paper proposes an on-the-fly DFQ framework with sub-second quantization time, called SQuant, which can quantize networks on inference-only devices with low computation and memory requirements. With the theoretical analysis of the second-order information of DNN task loss, we decompose and approximate the Hessian-based optimization objective into three diagonal sub-items, which have different areas corresponding to three dimensions of weight tensor: element-wise, kernel-wise, and output channel-wise. Then, we progressively compose sub-items and propose a novel data-free optimization objective in the discrete domain, minimizing Constrained Absolute Sum of Error (or CASE in short), which surprisingly does not need any dataset and is even not aware of network architecture. We also design an efficient algorithm without back-propagation to further reduce the computation complexity of the objective solver. Finally, without fine-tuning and synthetic datasets, SQuant accelerates the data-free quantization process to a sub-second level with >30% accuracy improvement over the existing data-free post-training quantization works, with the evaluated models under 4-bit quantization. We have open-sourced the SQuant framework at https://github.com/clevercool/SQuant.