 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJin Li
Incremental Learning with Concept Drift Detection and Prototype-based Embeddings for Graph Stream Classification
Apr 12, 2024
Data stream mining aims at extracting meaningful knowledge from continually evolving data streams, addressing the challenges posed by nonstationary environments, particularly, concept drift which refers to a change in the underlying data distribution over time. Graph structures offer a powerful modelling tool to represent complex systems, such as, critical infrastructure systems and social networks. Learning from graph streams becomes a necessity to understand the dynamics of graph structures and to facilitate informed decision-making. This work introduces a novel method for graph stream classification which operates under the general setting where a data generating process produces graphs with varying nodes and edges over time. The method uses incremental learning for continual model adaptation, selecting representative graphs (prototypes) for each class, and creating graph embeddings. Additionally, it incorporates a loss-based concept drift detection mechanism to recalculate graph prototypes when drift is detected.
CATP: Cross-Attention Token Pruning for Accuracy Preserved Multimodal Model Inference
Apr 02, 2024In response to the rising interest in large multimodal models, we introduce Cross-Attention Token Pruning (CATP), a precision-focused token pruning method. Our approach leverages cross-attention layers in multimodal models, exemplified by BLIP-2, to extract valuable information for token importance determination. CATP employs a refined voting strategy across model heads and layers. In evaluations, CATP achieves up to 12.1X higher accuracy compared to existing token pruning methods, addressing the trade-off between computational efficiency and model precision.
Open-Vocabulary Scene Text Recognition via Pseudo-Image Labeling and Margin Loss
Mar 12, 2024
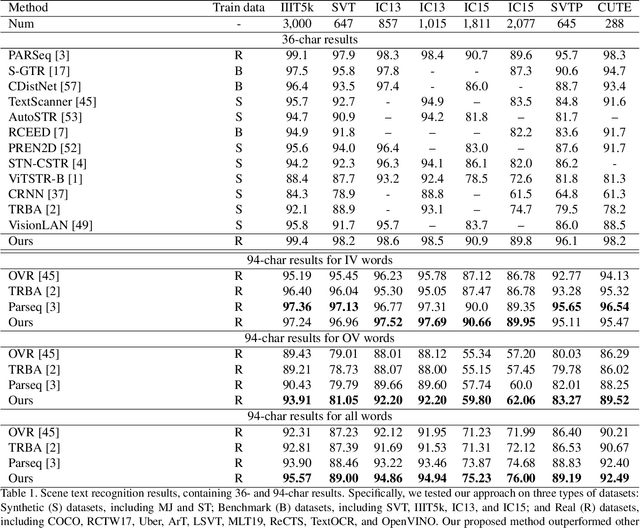
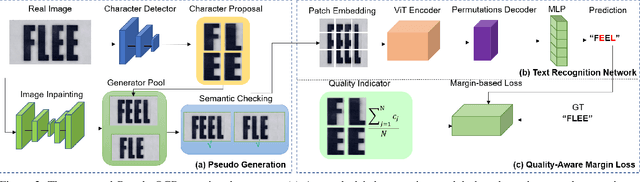
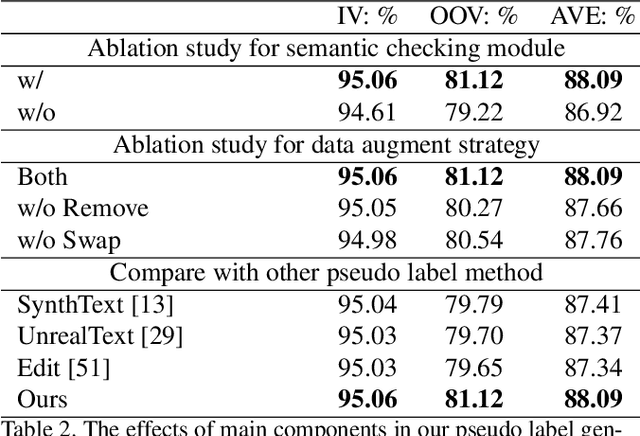
Scene text recognition is an important and challenging task in computer vision. However, most prior works focus on recognizing pre-defined words, while there are various out-of-vocabulary (OOV) words in real-world applications. In this paper, we propose a novel open-vocabulary text recognition framework, Pseudo-OCR, to recognize OOV words. The key challenge in this task is the lack of OOV training data. To solve this problem, we first propose a pseudo label generation module that leverages character detection and image inpainting to produce substantial pseudo OOV training data from real-world images. Unlike previous synthetic data, our pseudo OOV data contains real characters and backgrounds to simulate real-world applications. Secondly, to reduce noises in pseudo data, we present a semantic checking mechanism to filter semantically meaningful data. Thirdly, we introduce a quality-aware margin loss to boost the training with pseudo data. Our loss includes a margin-based part to enhance the classification ability, and a quality-aware part to penalize low-quality samples in both real and pseudo data. Extensive experiments demonstrate that our approach outperforms the state-of-the-art on eight datasets and achieves the first rank in the ICDAR2022 challenge.
Understanding Missingness in Time-series Electronic Health Records for Individualized Representation
Feb 24, 2024With the widespread of machine learning models for healthcare applications, there is increased interest in building applications for personalized medicine. Despite the plethora of proposed research for personalized medicine, very few focus on representing missingness and learning from the missingness patterns in time-series Electronic Health Records (EHR) data. The lack of focus on missingness representation in an individualized way limits the full utilization of machine learning applications towards true personalization. In this brief communication, we highlight new insights into patterns of missingness with real-world examples and implications of missingness in EHRs. The insights in this work aim to bridge the gap between theoretical assumptions and practical observations in real-world EHRs. We hope this work will open new doors for exploring directions for better representation in predictive modelling for true personalization.
Causal Learning for Trustworthy Recommender Systems: A Survey
Feb 13, 2024Recommender Systems (RS) have significantly advanced online content discovery and personalized decision-making. However, emerging vulnerabilities in RS have catalyzed a paradigm shift towards Trustworthy RS (TRS). Despite numerous progress on TRS, most of them focus on data correlations while overlooking the fundamental causal nature in recommendation. This drawback hinders TRS from identifying the cause in addressing trustworthiness issues, leading to limited fairness, robustness, and explainability. To bridge this gap, causal learning emerges as a class of promising methods to augment TRS. These methods, grounded in reliable causality, excel in mitigating various biases and noises while offering insightful explanations for TRS. However, there lacks a timely survey in this vibrant area. This paper creates an overview of TRS from the perspective of causal learning. We begin by presenting the advantages and common procedures of Causality-oriented TRS (CTRS). Then, we identify potential trustworthiness challenges at each stage and link them to viable causal solutions, followed by a classification of CTRS methods. Finally, we discuss several future directions for advancing this field.
UMG-CLIP: A Unified Multi-Granularity Vision Generalist for Open-World Understanding
Jan 18, 2024Vision-language foundation models, represented by Contrastive language-image pre-training (CLIP), have gained increasing attention for jointly understanding both vision and textual tasks. However, existing approaches primarily focus on training models to match global image representations with textual descriptions, thereby overlooking the critical alignment between local regions and corresponding text tokens. This paper extends CLIP with multi-granularity alignment. Notably, we deliberately construct a new dataset comprising pseudo annotations at various levels of granularities, encompassing image-level, region-level, and pixel-level captions/tags. Accordingly, we develop a unified multi-granularity learning framework, named UMG-CLIP, that simultaneously empowers the model with versatile perception abilities across different levels of detail. Equipped with parameter efficient tuning, UMG-CLIP surpasses current widely used CLIP models and achieves state-of-the-art performance on diverse image understanding benchmarks, including open-world recognition, retrieval, semantic segmentation, and panoptic segmentation tasks. We hope UMG-CLIP can serve as a valuable option for advancing vision-language foundation models.
IGNITE: Individualized GeNeration of Imputations in Time-series Electronic health records
Jan 09, 2024Electronic Health Records present a valuable modality for driving personalized medicine, where treatment is tailored to fit individual-level differences. For this purpose, many data-driven machine learning and statistical models rely on the wealth of longitudinal EHRs to study patients' physiological and treatment effects. However, longitudinal EHRs tend to be sparse and highly missing, where missingness could also be informative and reflect the underlying patient's health status. Therefore, the success of data-driven models for personalized medicine highly depends on how the EHR data is represented from physiological data, treatments, and the missing values in the data. To this end, we propose a novel deep-learning model that learns the underlying patient dynamics over time across multivariate data to generate personalized realistic values conditioning on an individual's demographic characteristics and treatments. Our proposed model, IGNITE (Individualized GeNeration of Imputations in Time-series Electronic health records), utilises a conditional dual-variational autoencoder augmented with dual-stage attention to generate missing values for an individual. In IGNITE, we further propose a novel individualized missingness mask (IMM), which helps our model generate values based on the individual's observed data and missingness patterns. We further extend the use of IGNITE from imputing missingness to a personalized data synthesizer, where it generates missing EHRs that were never observed prior or even generates new patients for various applications. We validate our model on three large publicly available datasets and show that IGNITE outperforms state-of-the-art approaches in missing data reconstruction and task prediction.
GanFinger: GAN-Based Fingerprint Generation for Deep Neural Network Ownership Verification
Dec 25, 2023Deep neural networks (DNNs) are extensively employed in a wide range of application scenarios. Generally, training a commercially viable neural network requires significant amounts of data and computing resources, and it is easy for unauthorized users to use the networks illegally. Therefore, network ownership verification has become one of the most crucial steps in safeguarding digital assets. To verify the ownership of networks, the existing network fingerprinting approaches perform poorly in the aspects of efficiency, stealthiness, and discriminability. To address these issues, we propose a network fingerprinting approach, named as GanFinger, to construct the network fingerprints based on the network behavior, which is characterized by network outputs of pairs of original examples and conferrable adversarial examples. Specifically, GanFinger leverages Generative Adversarial Networks (GANs) to effectively generate conferrable adversarial examples with imperceptible perturbations. These examples can exhibit identical outputs on copyrighted and pirated networks while producing different results on irrelevant networks. Moreover, to enhance the accuracy of fingerprint ownership verification, the network similarity is computed based on the accuracy-robustness distance of fingerprint examples'outputs. To evaluate the performance of GanFinger, we construct a comprehensive benchmark consisting of 186 networks with five network structures and four popular network post-processing techniques. The benchmark experiments demonstrate that GanFinger significantly outperforms the state-of-the-arts in efficiency, stealthiness, and discriminability. It achieves a remarkable 6.57 times faster in fingerprint generation and boosts the ARUC value by 0.175, resulting in a relative improvement of about 26%.
Curriculum-Enhanced Residual Soft An-Isotropic Normalization for Over-smoothness in Deep GNNs
Dec 14, 2023Despite Graph neural networks' significant performance gain over many classic techniques in various graph-related downstream tasks, their successes are restricted in shallow models due to over-smoothness and the difficulties of optimizations among many other issues. In this paper, to alleviate the over-smoothing issue, we propose a soft graph normalization method to preserve the diversities of node embeddings and prevent indiscrimination due to possible over-closeness. Combined with residual connections, we analyze the reason why the method can effectively capture the knowledge in both input graph structures and node features even with deep networks. Additionally, inspired by Curriculum Learning that learns easy examples before the hard ones, we propose a novel label-smoothing-based learning framework to enhance the optimization of deep GNNs, which iteratively smooths labels in an auxiliary graph and constructs many gradual non-smooth tasks for extracting increasingly complex knowledge and gradually discriminating nodes from coarse to fine. The method arguably reduces the risk of overfitting and generalizes better results. Finally, extensive experiments are carried out to demonstrate the effectiveness and potential of the proposed model and learning framework through comparison with twelve existing baselines including the state-of-the-art methods on twelve real-world node classification benchmarks.
AiluRus: A Scalable ViT Framework for Dense Prediction
Nov 02, 2023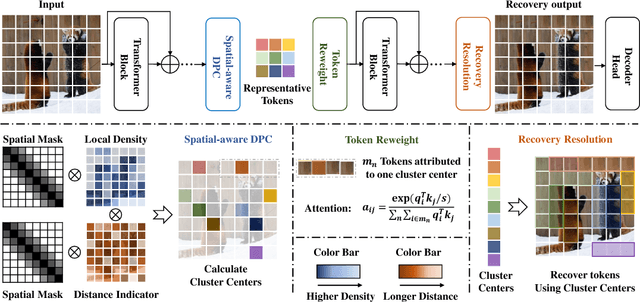
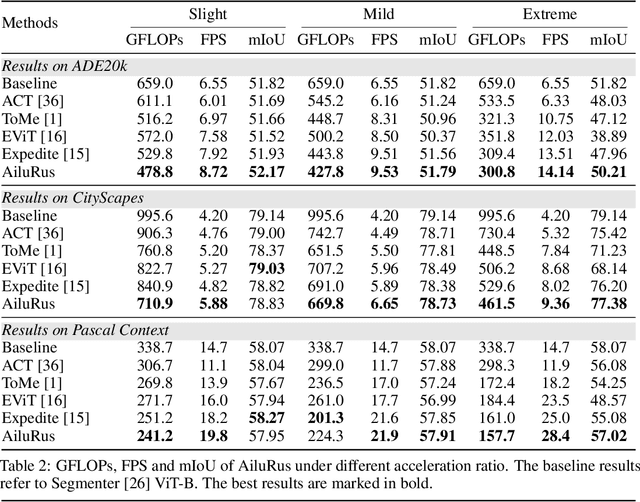
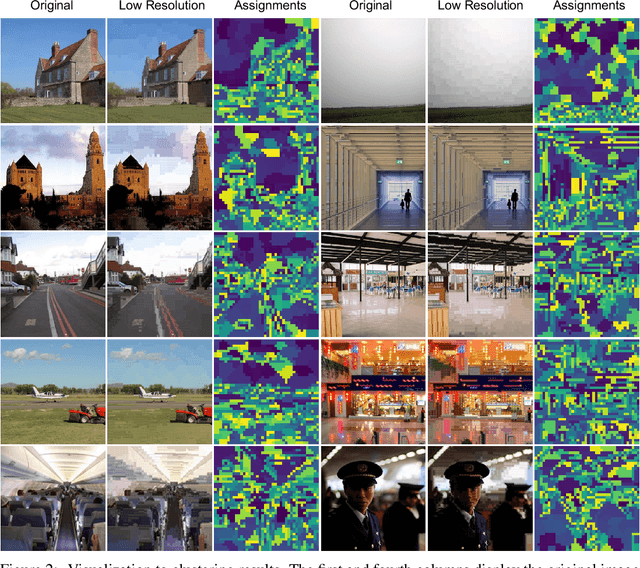
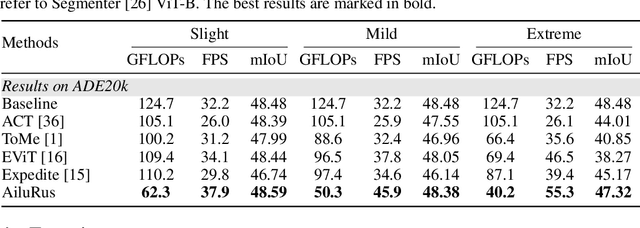
Vision transformers (ViTs) have emerged as a prevalent architecture for vision tasks owing to their impressive performance. However, when it comes to handling long token sequences, especially in dense prediction tasks that require high-resolution input, the complexity of ViTs increases significantly. Notably, dense prediction tasks, such as semantic segmentation or object detection, emphasize more on the contours or shapes of objects, while the texture inside objects is less informative. Motivated by this observation, we propose to apply adaptive resolution for different regions in the image according to their importance. Specifically, at the intermediate layer of the ViT, we utilize a spatial-aware density-based clustering algorithm to select representative tokens from the token sequence. Once the representative tokens are determined, we proceed to merge other tokens into their closest representative token. Consequently, semantic similar tokens are merged together to form low-resolution regions, while semantic irrelevant tokens are preserved independently as high-resolution regions. This strategy effectively reduces the number of tokens, allowing subsequent layers to handle a reduced token sequence and achieve acceleration. We evaluate our proposed method on three different datasets and observe promising performance. For example, the "Segmenter ViT-L" model can be accelerated by 48% FPS without fine-tuning, while maintaining the performance. Additionally, our method can be applied to accelerate fine-tuning as well. Experimental results demonstrate that we can save 52% training time while accelerating 2.46 times FPS with only a 0.09% performance drop. The code is available at https://github.com/caddyless/ailurus/tree/main.