 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiuzhen Zhang
FairGT: A Fairness-aware Graph Transformer
Apr 26, 2024
The design of Graph Transformers (GTs) generally neglects considerations for fairness, resulting in biased outcomes against certain sensitive subgroups. Since GTs encode graph information without relying on message-passing mechanisms, conventional fairness-aware graph learning methods cannot be directly applicable to address these issues. To tackle this challenge, we propose FairGT, a Fairness-aware Graph Transformer explicitly crafted to mitigate fairness concerns inherent in GTs. FairGT incorporates a meticulous structural feature selection strategy and a multi-hop node feature integration method, ensuring independence of sensitive features and bolstering fairness considerations. These fairness-aware graph information encodings seamlessly integrate into the Transformer framework for downstream tasks. We also prove that the proposed fair structural topology encoding with adjacency matrix eigenvector selection and multi-hop integration are theoretically effective. Empirical evaluations conducted across five real-world datasets demonstrate FairGT's superiority in fairness metrics over existing graph transformers, graph neural networks, and state-of-the-art fairness-aware graph learning approaches.
CMA-R:Causal Mediation Analysis for Explaining Rumour Detection
Feb 13, 2024We apply causal mediation analysis to explain the decision-making process of neural models for rumour detection on Twitter. Interventions at the input and network level reveal the causal impacts of tweets and words in the model output. We find that our approach CMA-R -- Causal Mediation Analysis for Rumour detection -- identifies salient tweets that explain model predictions and show strong agreement with human judgements for critical tweets determining the truthfulness of stories. CMA-R can further highlight causally impactful words in the salient tweets, providing another layer of interpretability and transparency into these blackbox rumour detection systems. Code is available at: https://github.com/ltian678/cma-r.
Causal Learning for Trustworthy Recommender Systems: A Survey
Feb 13, 2024Recommender Systems (RS) have significantly advanced online content discovery and personalized decision-making. However, emerging vulnerabilities in RS have catalyzed a paradigm shift towards Trustworthy RS (TRS). Despite numerous progress on TRS, most of them focus on data correlations while overlooking the fundamental causal nature in recommendation. This drawback hinders TRS from identifying the cause in addressing trustworthiness issues, leading to limited fairness, robustness, and explainability. To bridge this gap, causal learning emerges as a class of promising methods to augment TRS. These methods, grounded in reliable causality, excel in mitigating various biases and noises while offering insightful explanations for TRS. However, there lacks a timely survey in this vibrant area. This paper creates an overview of TRS from the perspective of causal learning. We begin by presenting the advantages and common procedures of Causality-oriented TRS (CTRS). Then, we identify potential trustworthiness challenges at each stage and link them to viable causal solutions, followed by a classification of CTRS methods. Finally, we discuss several future directions for advancing this field.
Bias in Opinion Summarisation from Pre-training to Adaptation: A Case Study in Political Bias
Feb 01, 2024Opinion summarisation aims to summarise the salient information and opinions presented in documents such as product reviews, discussion forums, and social media texts into short summaries that enable users to effectively understand the opinions therein. Generating biased summaries has the risk of potentially swaying public opinion. Previous studies focused on studying bias in opinion summarisation using extractive models, but limited research has paid attention to abstractive summarisation models. In this study, using political bias as a case study, we first establish a methodology to quantify bias in abstractive models, then trace it from the pre-trained models to the task of summarising social media opinions using different models and adaptation methods. We find that most models exhibit intrinsic bias. Using a social media text summarisation dataset and contrasting various adaptation methods, we find that tuning a smaller number of parameters is less biased compared to standard fine-tuning; however, the diversity of topics in training data used for fine-tuning is critical.
Harnessing Network Effect for Fake News Mitigation: Selecting Debunkers via Self-Imitation Learning
Jan 28, 2024This study aims to minimize the influence of fake news on social networks by deploying debunkers to propagate true news. This is framed as a reinforcement learning problem, where, at each stage, one user is selected to propagate true news. A challenging issue is episodic reward where the "net" effect of selecting individual debunkers cannot be discerned from the interleaving information propagation on social networks, and only the collective effect from mitigation efforts can be observed. Existing Self-Imitation Learning (SIL) methods have shown promise in learning from episodic rewards, but are ill-suited to the real-world application of fake news mitigation because of their poor sample efficiency. To learn a more effective debunker selection policy for fake news mitigation, this study proposes NAGASIL - Negative sampling and state Augmented Generative Adversarial Self-Imitation Learning, which consists of two improvements geared towards fake news mitigation: learning from negative samples, and an augmented state representation to capture the "real" environment state by integrating the current observed state with the previous state-action pairs from the same campaign. Experiments on two social networks show that NAGASIL yields superior performance to standard GASIL and state-of-the-art fake news mitigation models.
Explainable History Distillation by Marked Temporal Point Process
Nov 13, 2023Explainability of machine learning models is mandatory when researchers introduce these commonly believed black boxes to real-world tasks, especially high-stakes ones. In this paper, we build a machine learning system to automatically generate explanations of happened events from history by \gls{ca} based on the \acrfull{tpp}. Specifically, we propose a new task called \acrfull{ehd}. This task requires a model to distill as few events as possible from observed history. The target is that the event distribution conditioned on left events predicts the observed future noticeably worse. We then regard distilled events as the explanation for the future. To efficiently solve \acrshort{ehd}, we rewrite the task into a \gls{01ip} and directly estimate the solution to the program by a model called \acrfull{model}. This work fills the gap between our task and existing works, which only spot the difference between factual and counterfactual worlds after applying a predefined modification to the environment. Experiment results on Retweet and StackOverflow datasets prove that \acrshort{model} significantly outperforms other \acrshort{ehd} baselines and can reveal the rationale underpinning real-world processes.
Utilising a Large Language Model to Annotate Subject Metadata: A Case Study in an Australian National Research Data Catalogue
Oct 17, 2023
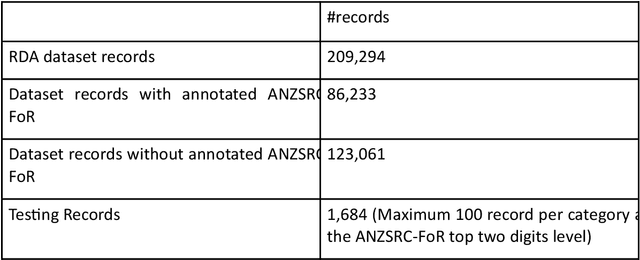


In support of open and reproducible research, there has been a rapidly increasing number of datasets made available for research. As the availability of datasets increases, it becomes more important to have quality metadata for discovering and reusing them. Yet, it is a common issue that datasets often lack quality metadata due to limited resources for data curation. Meanwhile, technologies such as artificial intelligence and large language models (LLMs) are progressing rapidly. Recently, systems based on these technologies, such as ChatGPT, have demonstrated promising capabilities for certain data curation tasks. This paper proposes to leverage LLMs for cost-effective annotation of subject metadata through the LLM-based in-context learning. Our method employs GPT-3.5 with prompts designed for annotating subject metadata, demonstrating promising performance in automatic metadata annotation. However, models based on in-context learning cannot acquire discipline-specific rules, resulting in lower performance in several categories. This limitation arises from the limited contextual information available for subject inference. To the best of our knowledge, we are introducing, for the first time, an in-context learning method that harnesses large language models for automated subject metadata annotation.
Intensity-free Integral-based Learning of Marked Temporal Point Processes
Aug 07, 2023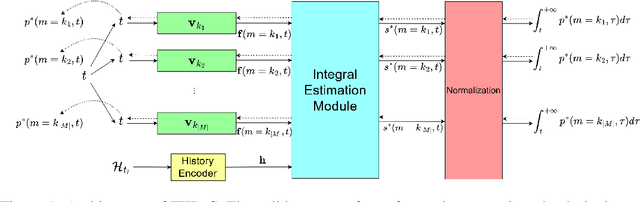
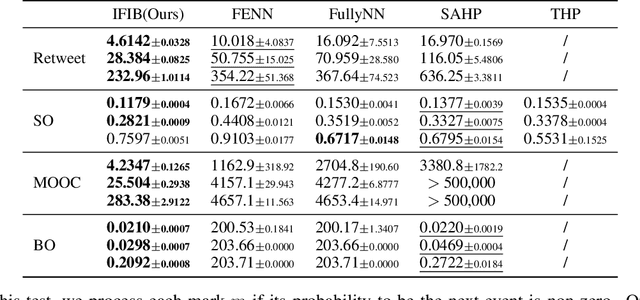
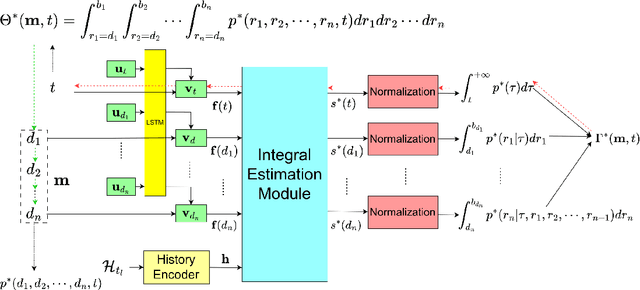

In the marked temporal point processes (MTPP), a core problem is to parameterize the conditional joint PDF (probability distribution function) $p^*(m,t)$ for inter-event time $t$ and mark $m$, conditioned on the history. The majority of existing studies predefine intensity functions. Their utility is challenged by specifying the intensity function's proper form, which is critical to balance expressiveness and processing efficiency. Recently, there are studies moving away from predefining the intensity function -- one models $p^*(t)$ and $p^*(m)$ separately, while the other focuses on temporal point processes (TPPs), which do not consider marks. This study aims to develop high-fidelity $p^*(m,t)$ for discrete events where the event marks are either categorical or numeric in a multi-dimensional continuous space. We propose a solution framework IFIB (\underline{I}ntensity-\underline{f}ree \underline{I}ntegral-\underline{b}ased process) that models conditional joint PDF $p^*(m,t)$ directly without intensity functions. It remarkably simplifies the process to compel the essential mathematical restrictions. We show the desired properties of IFIB and the superior experimental results of IFIB on real-world and synthetic datasets. The code is available at \url{https://github.com/StepinSilence/IFIB}.
Examining Bias in Opinion Summarisation Through the Perspective of Opinion Diversity
Jun 07, 2023



Opinion summarisation is a task that aims to condense the information presented in the source documents while retaining the core message and opinions. A summary that only represents the majority opinions will leave the minority opinions unrepresented in the summary. In this paper, we use the stance towards a certain target as an opinion. We study bias in opinion summarisation from the perspective of opinion diversity, which measures whether the model generated summary can cover a diverse set of opinions. In addition, we examine opinion similarity, a measure of how closely related two opinions are in terms of their stance on a given topic, and its relationship with opinion diversity. Through the lens of stances towards a topic, we examine opinion diversity and similarity using three debatable topics under COVID-19. Experimental results on these topics revealed that a higher degree of similarity of opinions did not indicate good diversity or fairly cover the various opinions originally presented in the source documents. We found that BART and ChatGPT can better capture diverse opinions presented in the source documents.
MetaTroll: Few-shot Detection of State-Sponsored Trolls with Transformer Adapters
Mar 13, 2023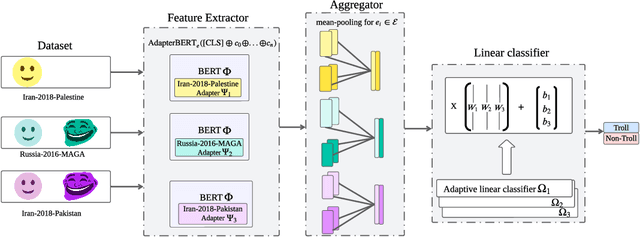
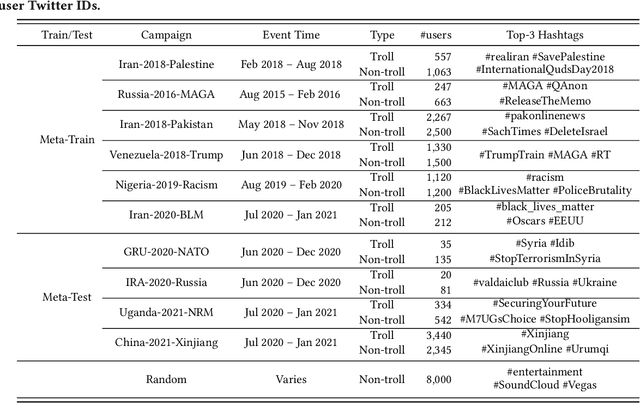
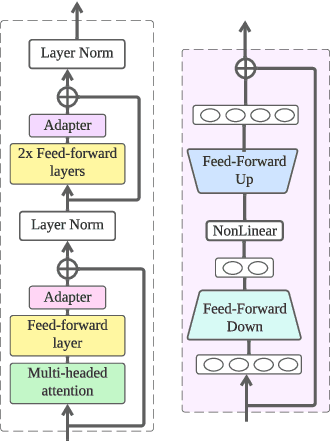
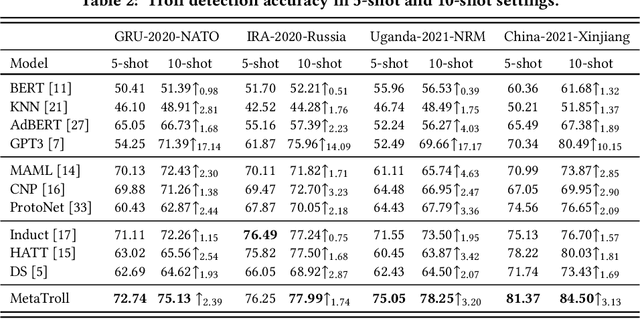
State-sponsored trolls are the main actors of influence campaigns on social media and automatic troll detection is important to combat misinformation at scale. Existing troll detection models are developed based on training data for known campaigns (e.g.\ the influence campaign by Russia's Internet Research Agency on the 2016 US Election), and they fall short when dealing with {\em novel} campaigns with new targets. We propose MetaTroll, a text-based troll detection model based on the meta-learning framework that enables high portability and parameter-efficient adaptation to new campaigns using only a handful of labelled samples for few-shot transfer. We introduce \textit{campaign-specific} transformer adapters to MetaTroll to ``memorise'' campaign-specific knowledge so as to tackle catastrophic forgetting, where a model ``forgets'' how to detect trolls from older campaigns due to continual adaptation. Our experiments demonstrate that MetaTroll substantially outperforms baselines and state-of-the-art few-shot text classification models. Lastly, we explore simple approaches to extend MetaTroll to multilingual and multimodal detection. Source code for MetaTroll is available at: https://github.com/ltian678/metatroll-code.git.