 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinsong Chen
Diversified Node Sampling based Hierarchical Transformer Pooling for Graph Representation Learning
Oct 31, 2023
Graph pooling methods have been widely used on downsampling graphs, achieving impressive results on multiple graph-level tasks like graph classification and graph generation. An important line called node dropping pooling aims at exploiting learnable scoring functions to drop nodes with comparatively lower significance scores. However, existing node dropping methods suffer from two limitations: (1) for each pooled node, these models struggle to capture long-range dependencies since they mainly take GNNs as the backbones; (2) pooling only the highest-scoring nodes tends to preserve similar nodes, thus discarding the affluent information of low-scoring nodes. To address these issues, we propose a Graph Transformer Pooling method termed GTPool, which introduces Transformer to node dropping pooling to efficiently capture long-range pairwise interactions and meanwhile sample nodes diversely. Specifically, we design a scoring module based on the self-attention mechanism that takes both global context and local context into consideration, measuring the importance of nodes more comprehensively. GTPool further utilizes a diversified sampling method named Roulette Wheel Sampling (RWS) that is able to flexibly preserve nodes across different scoring intervals instead of only higher scoring nodes. In this way, GTPool could effectively obtain long-range information and select more representative nodes. Extensive experiments on 11 benchmark datasets demonstrate the superiority of GTPool over existing popular graph pooling methods.
SignGT: Signed Attention-based Graph Transformer for Graph Representation Learning
Oct 17, 2023The emerging graph Transformers have achieved impressive performance for graph representation learning over graph neural networks (GNNs). In this work, we regard the self-attention mechanism, the core module of graph Transformers, as a two-step aggregation operation on a fully connected graph. Due to the property of generating positive attention values, the self-attention mechanism is equal to conducting a smooth operation on all nodes, preserving the low-frequency information. However, only capturing the low-frequency information is inefficient in learning complex relations of nodes on diverse graphs, such as heterophily graphs where the high-frequency information is crucial. To this end, we propose a Signed Attention-based Graph Transformer (SignGT) to adaptively capture various frequency information from the graphs. Specifically, SignGT develops a new signed self-attention mechanism (SignSA) that produces signed attention values according to the semantic relevance of node pairs. Hence, the diverse frequency information between different node pairs could be carefully preserved. Besides, SignGT proposes a structure-aware feed-forward network (SFFN) that introduces the neighborhood bias to preserve the local topology information. In this way, SignGT could learn informative node representations from both long-range dependencies and local topology information. Extensive empirical results on both node-level and graph-level tasks indicate the superiority of SignGT against state-of-the-art graph Transformers as well as advanced GNNs.
Tokenized Graph Transformer with Neighborhood Augmentation for Node Classification in Large Graphs
May 22, 2023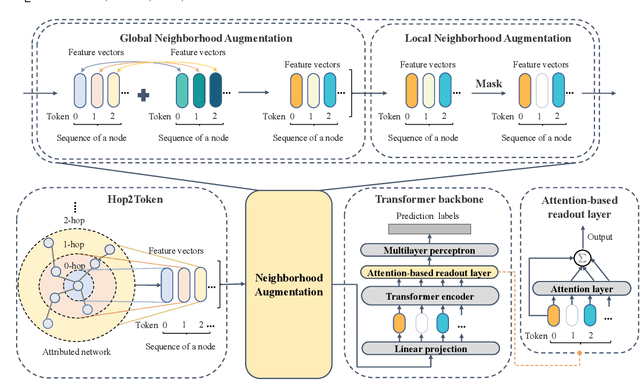
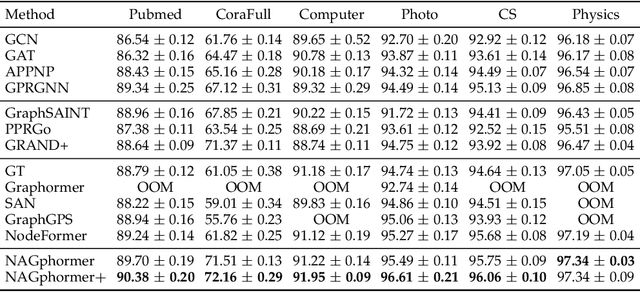

Graph Transformers, emerging as a new architecture for graph representation learning, suffer from the quadratic complexity on the number of nodes when handling large graphs. To this end, we propose a Neighborhood Aggregation Graph Transformer (NAGphormer) that treats each node as a sequence containing a series of tokens constructed by our proposed Hop2Token module. For each node, Hop2Token aggregates the neighborhood features from different hops into different representations, producing a sequence of token vectors as one input. In this way, NAGphormer could be trained in a mini-batch manner and thus could scale to large graphs. Moreover, we mathematically show that compared to a category of advanced Graph Neural Networks (GNNs), called decoupled Graph Convolutional Networks, NAGphormer could learn more informative node representations from multi-hop neighborhoods. In addition, we propose a new data augmentation method called Neighborhood Augmentation (NrAug) based on the output of Hop2Token that augments simultaneously the features of neighborhoods from global as well as local views to strengthen the training effect of NAGphormer. Extensive experiments on benchmark datasets from small to large demonstrate the superiority of NAGphormer against existing graph Transformers and mainstream GNNs, and the effectiveness of NrAug for further boosting NAGphormer.
Adaptive Multi-Neighborhood Attention based Transformer for Graph Representation Learning
Nov 15, 2022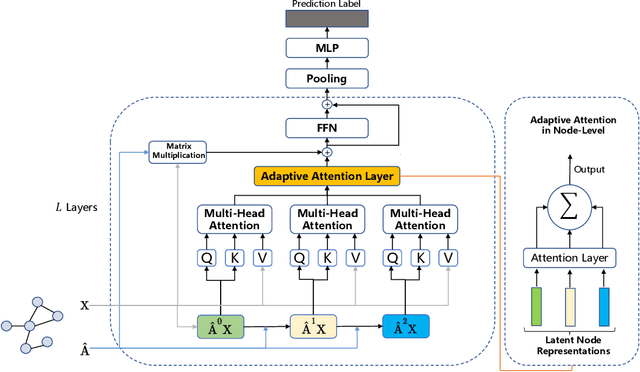
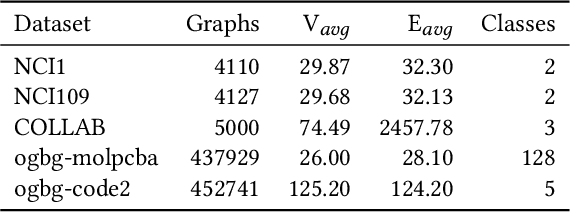
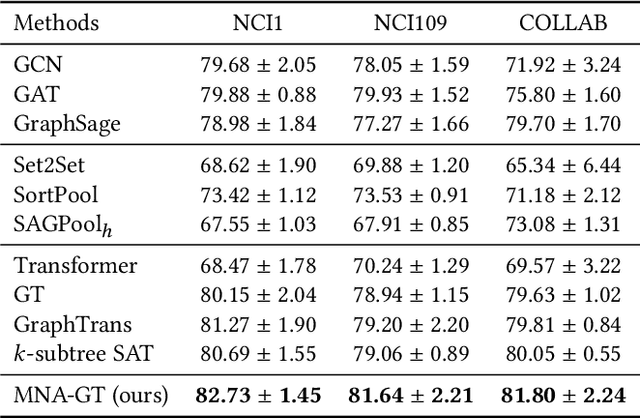
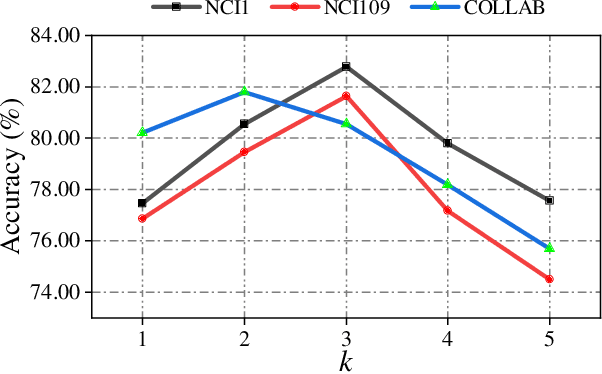
By incorporating the graph structural information into Transformers, graph Transformers have exhibited promising performance for graph representation learning in recent years. Existing graph Transformers leverage specific strategies, such as Laplacian eigenvectors and shortest paths of the node pairs, to preserve the structural features of nodes and feed them into the vanilla Transformer to learn the representations of nodes. It is hard for such predefined rules to extract informative graph structural features for arbitrary graphs whose topology structure varies greatly, limiting the learning capacity of the models. To this end, we propose an adaptive graph Transformer, termed Multi-Neighborhood Attention based Graph Transformer (MNA-GT), which captures the graph structural information for each node from the multi-neighborhood attention mechanism adaptively. By defining the input to perform scaled-dot product as an attention kernel, MNA-GT constructs multiple attention kernels based on different hops of neighborhoods such that each attention kernel can capture specific graph structural information of the corresponding neighborhood for each node pair. In this way, MNA-GT can preserve the graph structural information efficiently by incorporating node representations learned by different attention kernels. MNA-GT further employs an attention layer to learn the importance of different attention kernels to enable the model to adaptively capture the graph structural information for different nodes. Extensive experiments are conducted on a variety of graph benchmarks, and the empirical results show that MNA-GT outperforms many strong baselines.
Neighborhood Convolutional Network: A New Paradigm of Graph Neural Networks for Node Classification
Nov 15, 2022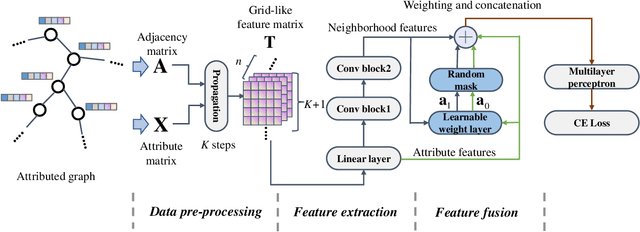
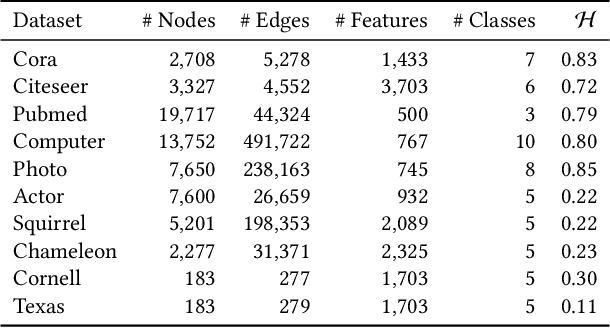
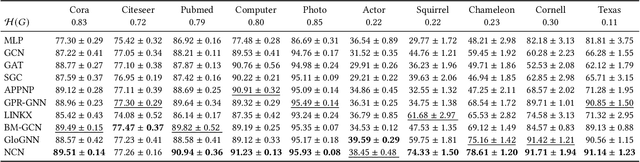
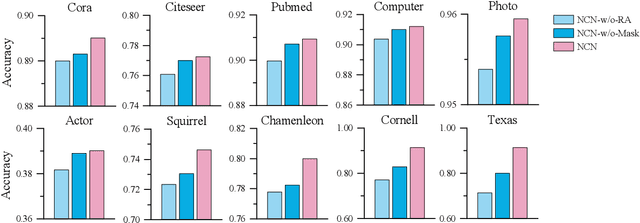
The decoupled Graph Convolutional Network (GCN), a recent development of GCN that decouples the neighborhood aggregation and feature transformation in each convolutional layer, has shown promising performance for graph representation learning. Existing decoupled GCNs first utilize a simple neural network (e.g., MLP) to learn the hidden features of the nodes, then propagate the learned features on the graph with fixed steps to aggregate the information of multi-hop neighborhoods. Despite effectiveness, the aggregation operation, which requires the whole adjacency matrix as the input, is involved in the model training, causing high training cost that hinders its potential on larger graphs. On the other hand, due to the independence of node attributes as the input, the neural networks used in decoupled GCNs are very simple, and advanced techniques cannot be applied to the modeling. To this end, we further liberate the aggregation operation from the decoupled GCN and propose a new paradigm of GCN, termed Neighborhood Convolutional Network (NCN), that utilizes the neighborhood aggregation result as the input, followed by a special convolutional neural network tailored for extracting expressive node representations from the aggregation input. In this way, the model could inherit the merit of decoupled GCN for aggregating neighborhood information, at the same time, develop much more powerful feature learning modules. A training strategy called mask training is incorporated to further boost the model performance. Extensive results demonstrate the effectiveness of our model for the node classification task on diverse homophilic graphs and heterophilic graphs.
Propagation with Adaptive Mask then Training for Node Classification on Attributed Networks
Jun 23, 2022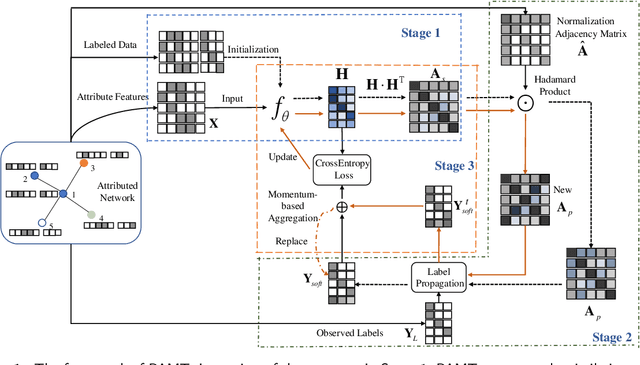
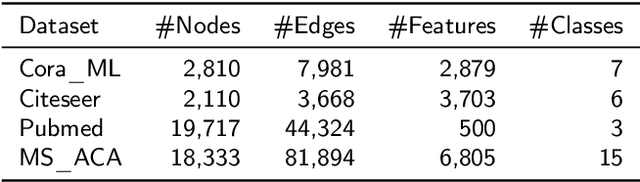
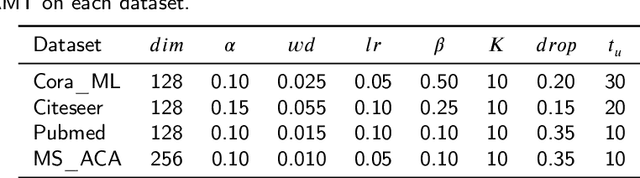
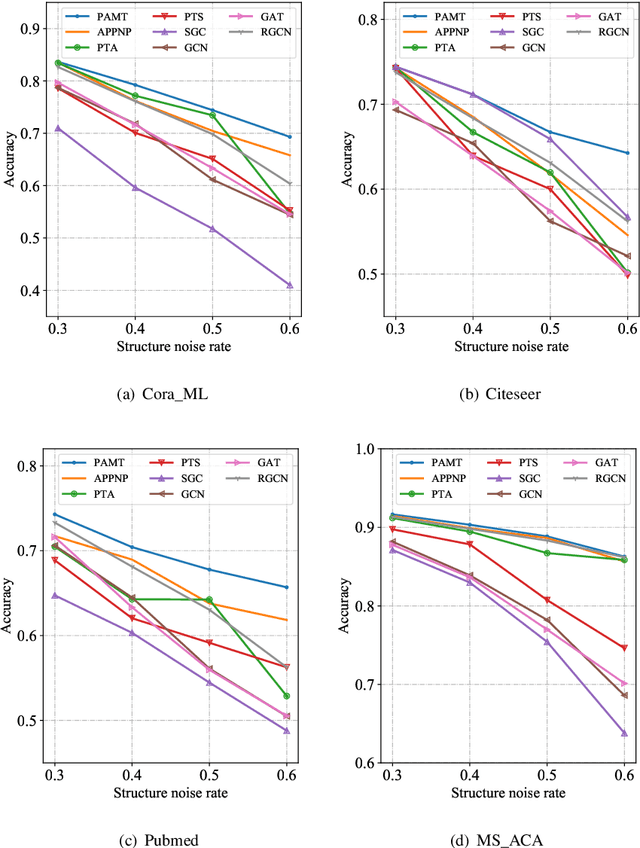
Node classification on attributed networks is a semi-supervised task that is crucial for network analysis. By decoupling two critical operations in Graph Convolutional Networks (GCNs), namely feature transformation and neighborhood aggregation, some recent works of decoupled GCNs could support the information to propagate deeper and achieve advanced performance. However, they follow the traditional structure-aware propagation strategy of GCNs, making it hard to capture the attribute correlation of nodes and sensitive to the structure noise described by edges whose two endpoints belong to different categories. To address these issues, we propose a new method called the itshape Propagation with Adaptive Mask then Training (PAMT). The key idea is to integrate the attribute similarity mask into the structure-aware propagation process. In this way, PAMT could preserve the attribute correlation of adjacent nodes during the propagation and effectively reduce the influence of structure noise. Moreover, we develop an iterative refinement mechanism to update the similarity mask during the training process for improving the training performance. Extensive experiments on four real-world datasets demonstrate the superior performance and robustness of PAMT.
NAGphormer: Neighborhood Aggregation Graph Transformer for Node Classification in Large Graphs
Jun 10, 2022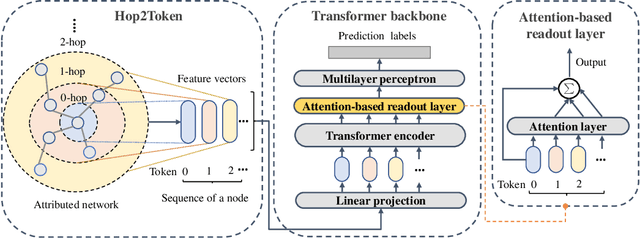
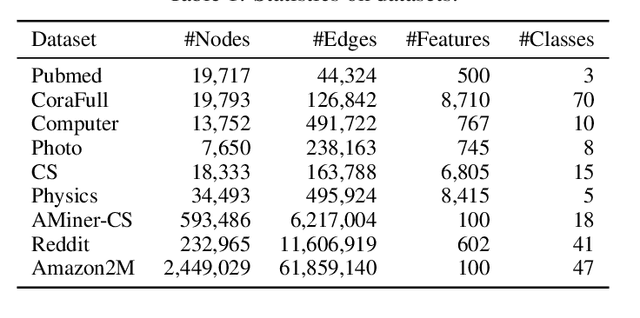
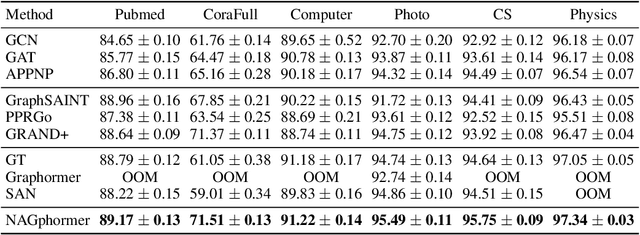
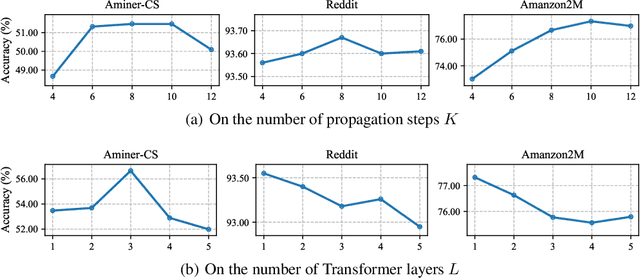
Graph Transformers have demonstrated superiority on various graph learning tasks in recent years. However, the complexity of existing Graph Transformers scales quadratically with the number of nodes, making it hard to scale to graphs with thousands of nodes. To this end, we propose a Neighborhood Aggregation Graph Transformer (NAGphormer) that is scalable to large graphs with millions of nodes. Before feeding the node features into the Transformer model, NAGphormer constructs tokens for each node by a neighborhood aggregation module called Hop2Token. For each node, Hop2Token aggregates neighborhood features from each hop into a representation, and thereby produces a sequence of token vectors. Subsequently, the resulting sequence of different hop information serves as input to the Transformer model. By considering each node as a sequence, NAGphormer could be trained in a mini-batch manner and thus could scale to large graphs. NAGphormer further develops an attention-based readout function so as to learn the importance of each hop adaptively. We conduct extensive experiments on various popular benchmarks, including six small datasets and three large datasets. The results demonstrate that NAGphormer consistently outperforms existing Graph Transformers and mainstream Graph Neural Networks.
Spectral Mixture Kernels with Time and Phase Delay Dependencies
Oct 14, 2018
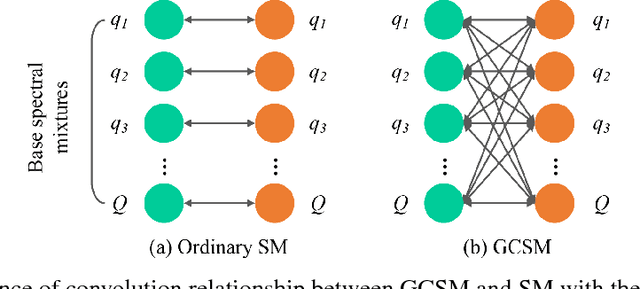
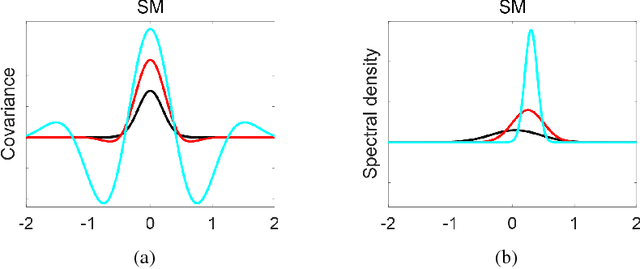
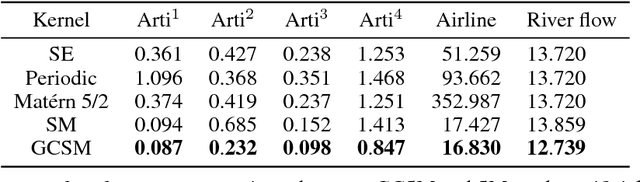
Spectral Mixture (SM) kernels form a powerful class of kernels for Gaussian processes, capable to discover patterns, extrapolate, and model negative co-variances. In SM kernels, spectral mixture components are linearly combined to construct a final flexible kernel. As a consequence SM kernels does not explicitly model correlations between components and dependencies related to time and phase delays between components, because only the auto-convolution of base components are used. To address these drawbacks we introduce Generalized Convolution Spectral Mixture (GCSM) kernels. We incorporate time and phase delay into the base spectral mixture and use cross-convolution between a base component and the complex conjugate of another base component to construct a complex-valued and positive definite kernel representing correlations between base components. In this way the total number of components in GCSM becomes quadratic. We perform a thorough comparative experimental analysis of GCSM on synthetic and real-life datasets. Results indicate the beneficial effect of the extra features of GCSM. This is illustrated in the problem of forecasting the long range trend of a river flow to monitor environment evolution, where GCSM is capable of discovering correlated patterns that SM cannot and improving patterns recognition ability of SM.
Multi-Output Convolution Spectral Mixture for Gaussian Processes
Oct 14, 2018
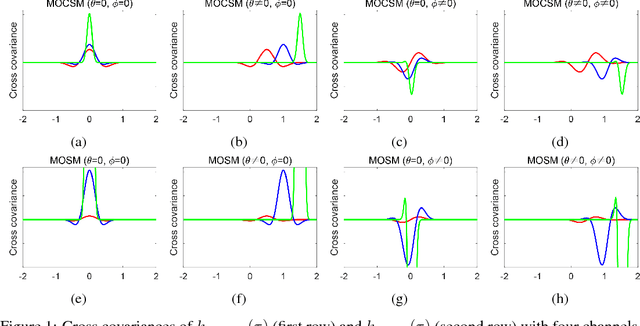
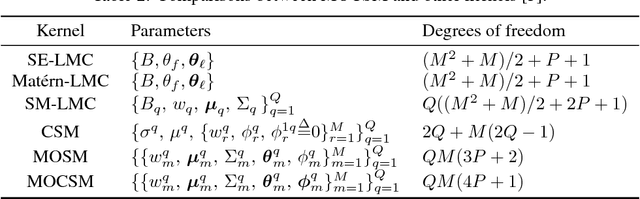
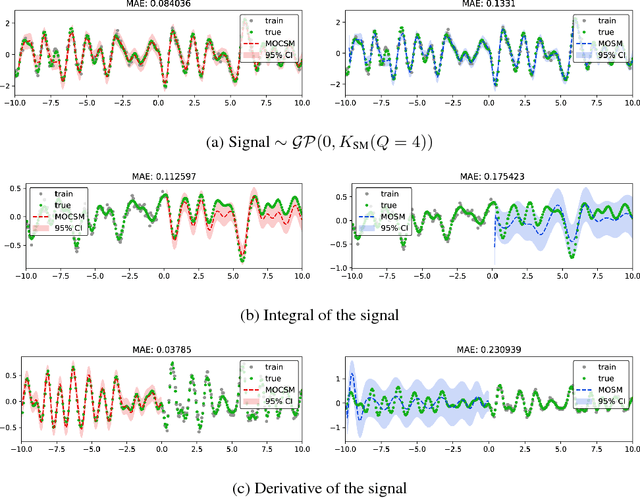
Multi-output Gaussian processes (MOGPs) are recently extended by using spectral mixture kernel, which enables expressively pattern extrapolation with a strong interpretation. In particular, Multi-Output Spectral Mixture kernel (MOSM) is a recent, powerful state of the art method. However, MOSM cannot reduce to the ordinary spectral mixture kernel (SM) when using a single channel. Moreover, when the spectral density of different channels is either very close or very far from each other in the frequency domain, MOSM generates unreasonable scale effects on cross weights which produces an incorrect description of the channel correlation structure. In this paper, we tackle these drawbacks and introduce a principled multi-output convolution spectral mixture kernel (MOCSM) framework. In our framework, we model channel dependencies through convolution of time and phase delayed spectral mixtures between different channels. Results of extensive experiments on synthetic and real datasets demontrate the advantages of MOCSM and its state of the art performance.
Generalized Spectral Mixture Kernels for Multi-Task Gaussian Processes
Oct 14, 2018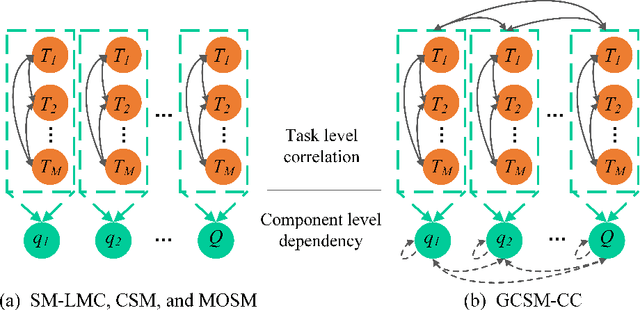

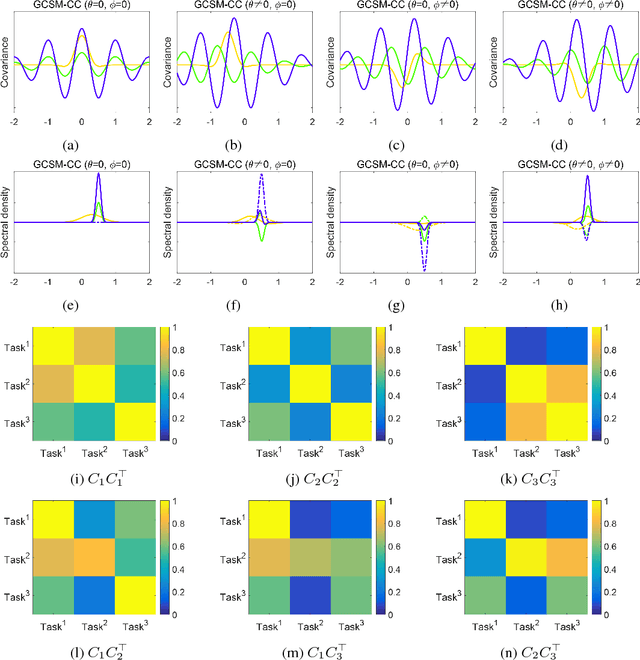

Multi-Task Gaussian processes (MTGPs) have shown a significant progress both in expressiveness and interpretation of the relatedness between different tasks: from linear combinations of independent single-output Gaussian processes (GPs), through the direct modeling of the cross-covariances such as spectral mixture kernels with phase shift, to the design of multivariate covariance functions based on spectral mixture kernels which model delays among tasks in addition to phase differences, and which provide a parametric interpretation of the relatedness across tasks. In this paper we further extend expressiveness and interpretability of MTGPs models and introduce a new family of kernels capable to model nonlinear correlations between tasks as well as dependencies between spectral mixtures, including time and phase delay. Specifically, we use generalized convolution spectral mixture kernels for modeling dependencies at spectral mixture level, and coupling coregionalization for discovering task level correlations. The proposed kernels for MTGP are validated on artificial data and compared with existing MTGPs methods on three real-world experiments. Results indicate the benefits of our more expressive representation with respect to performance and interpretability.