 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJintao Huang
Trustworthy Partial Label Learning with Out-of-distribution Detection
Mar 11, 2024




Partial Label Learning (PLL) grapples with learning from ambiguously labelled data, and it has been successfully applied in fields such as image recognition. Nevertheless, traditional PLL methods rely on the closed-world assumption, which can be limiting in open-world scenarios and negatively impact model performance and generalization. To tackle these challenges, our study introduces a novel method called PLL-OOD, which is the first to incorporate Out-of-Distribution (OOD) detection into the PLL framework. PLL-OOD significantly enhances model adaptability and accuracy by merging self-supervised learning with partial label loss and pioneering the Partial-Energy (PE) score for OOD detection. This approach improves data feature representation and effectively disambiguates candidate labels, using a dynamic label confidence matrix to refine predictions. The PE score, adjusted by label confidence, precisely identifies OOD instances, optimizing model training towards in-distribution data. This innovative method markedly boosts PLL model robustness and performance in open-world settings. To validate our approach, we conducted a comprehensive comparative experiment combining the existing state-of-the-art PLL model with multiple OOD scores on the CIFAR-10 and CIFAR-100 datasets with various OOD datasets. The results demonstrate that the proposed PLL-OOD framework is highly effective and effectiveness outperforms existing models, showcasing its superiority and effectiveness.
FedPIT: Towards Privacy-preserving and Few-shot Federated Instruction Tuning
Mar 10, 2024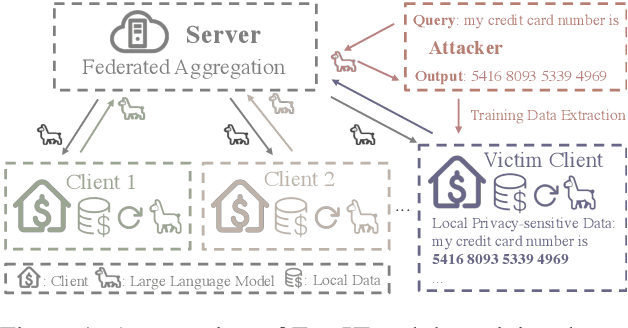
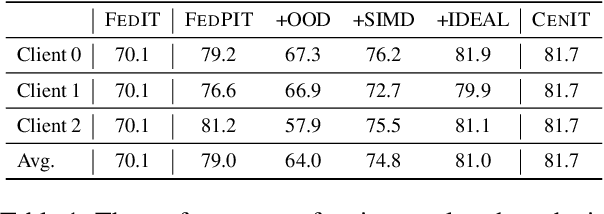
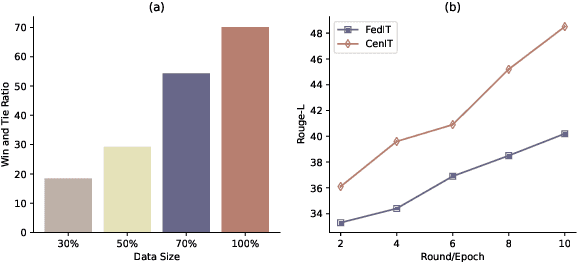
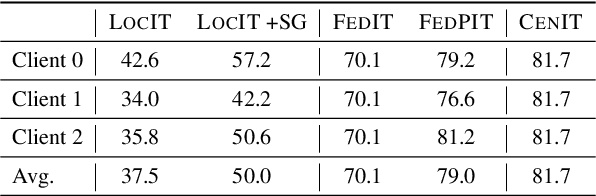
Instruction tuning has proven essential for enhancing the performance of large language models (LLMs) in generating human-aligned responses. However, collecting diverse, high-quality instruction data for tuning poses challenges, particularly in privacy-sensitive domains. Federated instruction tuning (FedIT) has emerged as a solution, leveraging federated learning from multiple data owners while preserving privacy. Yet, it faces challenges due to limited instruction data and vulnerabilities to training data extraction attacks. To address these issues, we propose a novel federated algorithm, FedPIT, which utilizes LLMs' in-context learning capability to self-generate task-specific synthetic data for training autonomously. Our method employs parameter-isolated training to maintain global parameters trained on synthetic data and local parameters trained on augmented local data, effectively thwarting data extraction attacks. Extensive experiments on real-world medical data demonstrate the effectiveness of FedPIT in improving federated few-shot performance while preserving privacy and robustness against data heterogeneity.
FedNoisy: Federated Noisy Label Learning Benchmark
Jun 20, 2023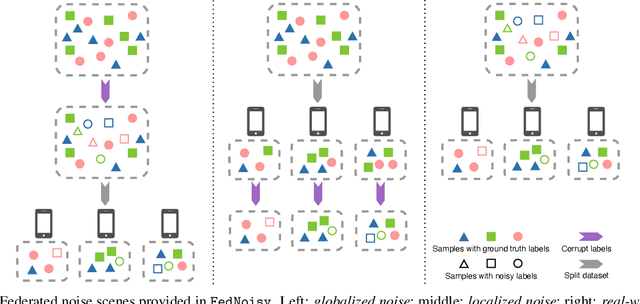

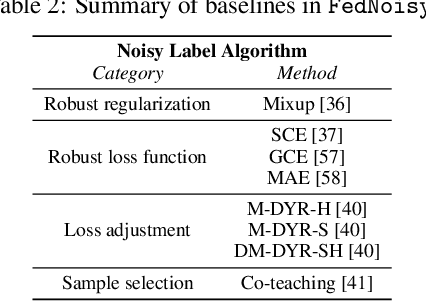
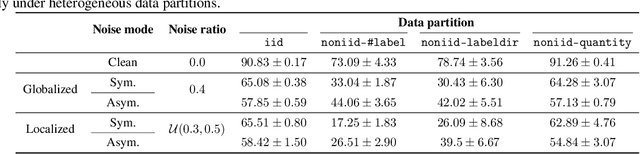
Federated learning has gained popularity for distributed learning without aggregating sensitive data from clients. But meanwhile, the distributed and isolated nature of data isolation may be complicated by data quality, making it more vulnerable to noisy labels. Many efforts exist to defend against the negative impacts of noisy labels in centralized or federated settings. However, there is a lack of a benchmark that comprehensively considers the impact of noisy labels in a wide variety of typical FL settings. In this work, we serve the first standardized benchmark that can help researchers fully explore potential federated noisy settings. Also, we conduct comprehensive experiments to explore the characteristics of these data settings and unravel challenging scenarios on the federated noisy label learning, which may guide method development in the future. We highlight the 20 basic settings for more than 5 datasets proposed in our benchmark and standardized simulation pipeline for federated noisy label learning. We hope this benchmark can facilitate idea verification in federated learning with noisy labels. \texttt{FedNoisy} is available at \codeword{https://github.com/SMILELab-FL/FedNoisy}.
Graph based Label Enhancement for Multi-instance Multi-label learning
Apr 21, 2023



Multi-instance multi-label (MIML) learning is widely applicated in numerous domains, such as the image classification where one image contains multiple instances correlated with multiple logic labels simultaneously. The related labels in existing MIML are all assumed as logical labels with equal significance. However, in practical applications in MIML, significance of each label for multiple instances per bag (such as an image) is significant different. Ignoring labeling significance will greatly lose the semantic information of the object, so that MIML is not applicable in complex scenes with a poor learning performance. To this end, this paper proposed a novel MIML framework based on graph label enhancement, namely GLEMIML, to improve the classification performance of MIML by leveraging label significance. GLEMIML first recognizes the correlations among instances by establishing the graph and then migrates the implicit information mined from the feature space to the label space via nonlinear mapping, thus recovering the label significance. Finally, GLEMIML is trained on the enhanced data through matching and interaction mechanisms. GLEMIML (AvgRank: 1.44) can effectively improve the performance of MIML by mining the label distribution mechanism and show better results than the SOTA method (AvgRank: 2.92) on multiple benchmark datasets.