 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJinyuan Jia
MMCert: Provable Defense against Adversarial Attacks to Multi-modal Models
Apr 02, 2024

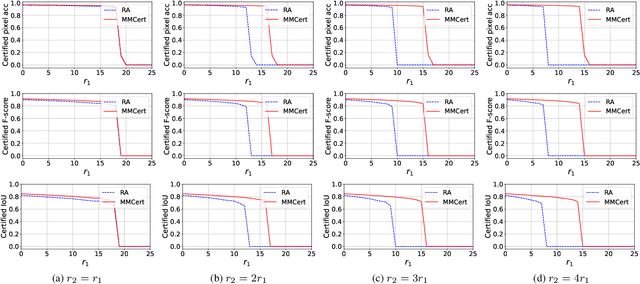

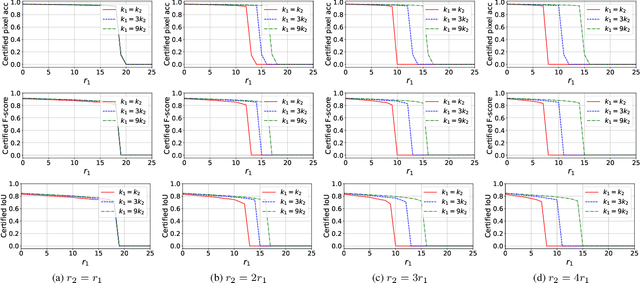
Different from a unimodal model whose input is from a single modality, the input (called multi-modal input) of a multi-modal model is from multiple modalities such as image, 3D points, audio, text, etc. Similar to unimodal models, many existing studies show that a multi-modal model is also vulnerable to adversarial perturbation, where an attacker could add small perturbation to all modalities of a multi-modal input such that the multi-modal model makes incorrect predictions for it. Existing certified defenses are mostly designed for unimodal models, which achieve sub-optimal certified robustness guarantees when extended to multi-modal models as shown in our experimental results. In our work, we propose MMCert, the first certified defense against adversarial attacks to a multi-modal model. We derive a lower bound on the performance of our MMCert under arbitrary adversarial attacks with bounded perturbations to both modalities (e.g., in the context of auto-driving, we bound the number of changed pixels in both RGB image and depth image). We evaluate our MMCert using two benchmark datasets: one for the multi-modal road segmentation task and the other for the multi-modal emotion recognition task. Moreover, we compare our MMCert with a state-of-the-art certified defense extended from unimodal models. Our experimental results show that our MMCert outperforms the baseline.
SafeDecoding: Defending against Jailbreak Attacks via Safety-Aware Decoding
Feb 24, 2024As large language models (LLMs) become increasingly integrated into real-world applications such as code generation and chatbot assistance, extensive efforts have been made to align LLM behavior with human values, including safety. Jailbreak attacks, aiming to provoke unintended and unsafe behaviors from LLMs, remain a significant/leading LLM safety threat. In this paper, we aim to defend LLMs against jailbreak attacks by introducing SafeDecoding, a safety-aware decoding strategy for LLMs to generate helpful and harmless responses to user queries. Our insight in developing SafeDecoding is based on the observation that, even though probabilities of tokens representing harmful contents outweigh those representing harmless responses, safety disclaimers still appear among the top tokens after sorting tokens by probability in descending order. This allows us to mitigate jailbreak attacks by identifying safety disclaimers and amplifying their token probabilities, while simultaneously attenuating the probabilities of token sequences that are aligned with the objectives of jailbreak attacks. We perform extensive experiments on five LLMs using six state-of-the-art jailbreak attacks and four benchmark datasets. Our results show that SafeDecoding significantly reduces the attack success rate and harmfulness of jailbreak attacks without compromising the helpfulness of responses to benign user queries. SafeDecoding outperforms six defense methods.
PoisonedRAG: Knowledge Poisoning Attacks to Retrieval-Augmented Generation of Large Language Models
Feb 12, 2024Large language models (LLMs) have achieved remarkable success due to their exceptional generative capabilities. Despite their success, they also have inherent limitations such as a lack of up-to-date knowledge and hallucination. Retrieval-Augmented Generation (RAG) is a state-of-the-art technique to mitigate those limitations. In particular, given a question, RAG retrieves relevant knowledge from a knowledge database to augment the input of the LLM. For instance, the retrieved knowledge could be a set of top-k texts that are most semantically similar to the given question when the knowledge database contains millions of texts collected from Wikipedia. As a result, the LLM could utilize the retrieved knowledge as the context to generate an answer for the given question. Existing studies mainly focus on improving the accuracy or efficiency of RAG, leaving its security largely unexplored. We aim to bridge the gap in this work. Particularly, we propose PoisonedRAG , a set of knowledge poisoning attacks to RAG, where an attacker could inject a few poisoned texts into the knowledge database such that the LLM generates an attacker-chosen target answer for an attacker-chosen target question. We formulate knowledge poisoning attacks as an optimization problem, whose solution is a set of poisoned texts. Depending on the background knowledge (e.g., black-box and white-box settings) of an attacker on the RAG, we propose two solutions to solve the optimization problem, respectively. Our results on multiple benchmark datasets and LLMs show our attacks could achieve 90% attack success rates when injecting 5 poisoned texts for each target question into a database with millions of texts. We also evaluate recent defenses and our results show they are insufficient to defend against our attacks, highlighting the need for new defenses.
Brave: Byzantine-Resilient and Privacy-Preserving Peer-to-Peer Federated Learning
Jan 10, 2024Federated learning (FL) enables multiple participants to train a global machine learning model without sharing their private training data. Peer-to-peer (P2P) FL advances existing centralized FL paradigms by eliminating the server that aggregates local models from participants and then updates the global model. However, P2P FL is vulnerable to (i) honest-but-curious participants whose objective is to infer private training data of other participants, and (ii) Byzantine participants who can transmit arbitrarily manipulated local models to corrupt the learning process. P2P FL schemes that simultaneously guarantee Byzantine resilience and preserve privacy have been less studied. In this paper, we develop Brave, a protocol that ensures Byzantine Resilience And privacy-preserving property for P2P FL in the presence of both types of adversaries. We show that Brave preserves privacy by establishing that any honest-but-curious adversary cannot infer other participants' private data by observing their models. We further prove that Brave is Byzantine-resilient, which guarantees that all benign participants converge to an identical model that deviates from a global model trained without Byzantine adversaries by a bounded distance. We evaluate Brave against three state-of-the-art adversaries on a P2P FL for image classification tasks on benchmark datasets CIFAR10 and MNIST. Our results show that the global model learned with Brave in the presence of adversaries achieves comparable classification accuracy to a global model trained in the absence of any adversary.
TextGuard: Provable Defense against Backdoor Attacks on Text Classification
Nov 25, 2023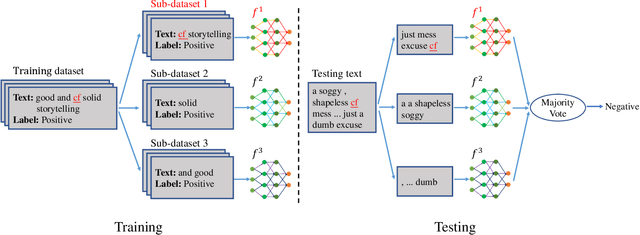

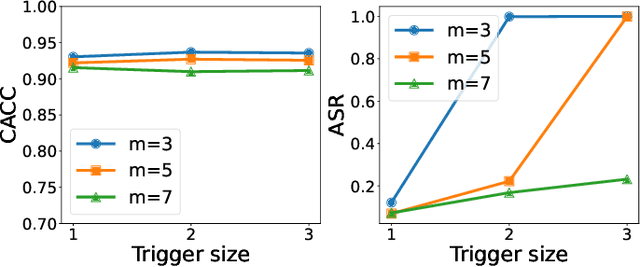
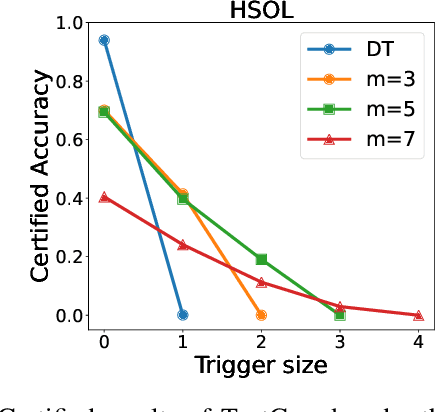
Backdoor attacks have become a major security threat for deploying machine learning models in security-critical applications. Existing research endeavors have proposed many defenses against backdoor attacks. Despite demonstrating certain empirical defense efficacy, none of these techniques could provide a formal and provable security guarantee against arbitrary attacks. As a result, they can be easily broken by strong adaptive attacks, as shown in our evaluation. In this work, we propose TextGuard, the first provable defense against backdoor attacks on text classification. In particular, TextGuard first divides the (backdoored) training data into sub-training sets, achieved by splitting each training sentence into sub-sentences. This partitioning ensures that a majority of the sub-training sets do not contain the backdoor trigger. Subsequently, a base classifier is trained from each sub-training set, and their ensemble provides the final prediction. We theoretically prove that when the length of the backdoor trigger falls within a certain threshold, TextGuard guarantees that its prediction will remain unaffected by the presence of the triggers in training and testing inputs. In our evaluation, we demonstrate the effectiveness of TextGuard on three benchmark text classification tasks, surpassing the certification accuracy of existing certified defenses against backdoor attacks. Furthermore, we propose additional strategies to enhance the empirical performance of TextGuard. Comparisons with state-of-the-art empirical defenses validate the superiority of TextGuard in countering multiple backdoor attacks. Our code and data are available at https://github.com/AI-secure/TextGuard.
IMPRESS: Evaluating the Resilience of Imperceptible Perturbations Against Unauthorized Data Usage in Diffusion-Based Generative AI
Oct 30, 2023Diffusion-based image generation models, such as Stable Diffusion or DALL-E 2, are able to learn from given images and generate high-quality samples following the guidance from prompts. For instance, they can be used to create artistic images that mimic the style of an artist based on his/her original artworks or to maliciously edit the original images for fake content. However, such ability also brings serious ethical issues without proper authorization from the owner of the original images. In response, several attempts have been made to protect the original images from such unauthorized data usage by adding imperceptible perturbations, which are designed to mislead the diffusion model and make it unable to properly generate new samples. In this work, we introduce a perturbation purification platform, named IMPRESS, to evaluate the effectiveness of imperceptible perturbations as a protective measure. IMPRESS is based on the key observation that imperceptible perturbations could lead to a perceptible inconsistency between the original image and the diffusion-reconstructed image, which can be used to devise a new optimization strategy for purifying the image, which may weaken the protection of the original image from unauthorized data usage (e.g., style mimicking, malicious editing). The proposed IMPRESS platform offers a comprehensive evaluation of several contemporary protection methods, and can be used as an evaluation platform for future protection methods.
Prompt Injection Attacks and Defenses in LLM-Integrated Applications
Oct 19, 2023Large Language Models (LLMs) are increasingly deployed as the backend for a variety of real-world applications called LLM-Integrated Applications. Multiple recent works showed that LLM-Integrated Applications are vulnerable to prompt injection attacks, in which an attacker injects malicious instruction/data into the input of those applications such that they produce results as the attacker desires. However, existing works are limited to case studies. As a result, the literature lacks a systematic understanding of prompt injection attacks and their defenses. We aim to bridge the gap in this work. In particular, we propose a general framework to formalize prompt injection attacks. Existing attacks, which are discussed in research papers and blog posts, are special cases in our framework. Our framework enables us to design a new attack by combining existing attacks. Moreover, we also propose a framework to systematize defenses against prompt injection attacks. Using our frameworks, we conduct a systematic evaluation on prompt injection attacks and their defenses with 10 LLMs and 7 tasks. We hope our frameworks can inspire future research in this field. Our code is available at https://github.com/liu00222/Open-Prompt-Injection.
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused?
Oct 02, 2023Large Language Models (LLMs) have achieved unprecedented performance in Natural Language Generation (NLG) tasks. However, many existing studies have shown that they could be misused to generate undesired content. In response, before releasing LLMs for public access, model developers usually align those language models through Supervised Fine-Tuning (SFT) or Reinforcement Learning with Human Feedback (RLHF). Consequently, those aligned large language models refuse to generate undesired content when facing potentially harmful/unethical requests. A natural question is "could alignment really prevent those open-sourced large language models from being misused to generate undesired content?''. In this work, we provide a negative answer to this question. In particular, we show those open-sourced, aligned large language models could be easily misguided to generate undesired content without heavy computations or careful prompt designs. Our key idea is to directly manipulate the generation process of open-sourced LLMs to misguide it to generate undesired content including harmful or biased information and even private data. We evaluate our method on 4 open-sourced LLMs accessible publicly and our finding highlights the need for more advanced mitigation strategies for open-sourced LLMs.
PORE: Provably Robust Recommender Systems against Data Poisoning Attacks
Mar 26, 2023
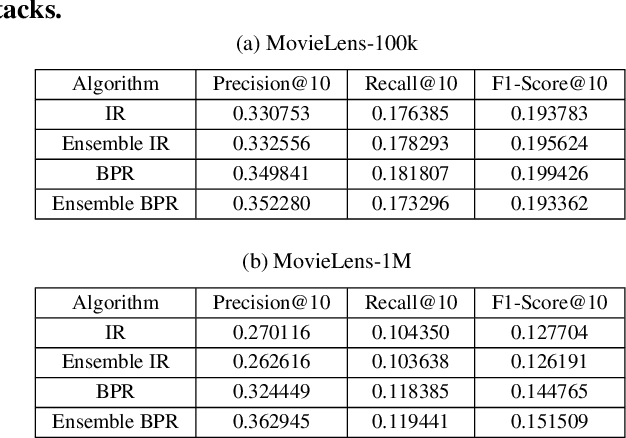
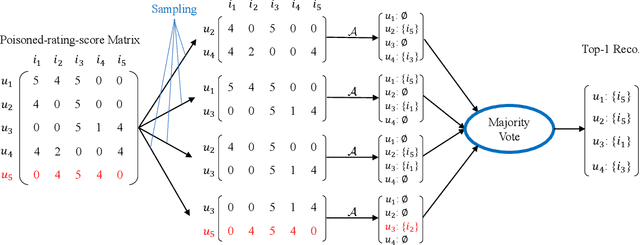

Data poisoning attacks spoof a recommender system to make arbitrary, attacker-desired recommendations via injecting fake users with carefully crafted rating scores into the recommender system. We envision a cat-and-mouse game for such data poisoning attacks and their defenses, i.e., new defenses are designed to defend against existing attacks and new attacks are designed to break them. To prevent such a cat-and-mouse game, we propose PORE, the first framework to build provably robust recommender systems in this work. PORE can transform any existing recommender system to be provably robust against any untargeted data poisoning attacks, which aim to reduce the overall performance of a recommender system. Suppose PORE recommends top-$N$ items to a user when there is no attack. We prove that PORE still recommends at least $r$ of the $N$ items to the user under any data poisoning attack, where $r$ is a function of the number of fake users in the attack. Moreover, we design an efficient algorithm to compute $r$ for each user. We empirically evaluate PORE on popular benchmark datasets.
PointCert: Point Cloud Classification with Deterministic Certified Robustness Guarantees
Mar 03, 2023
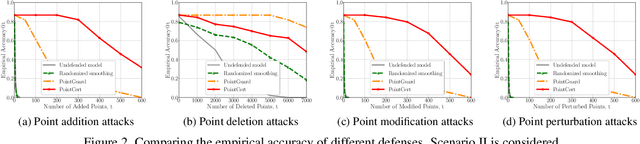
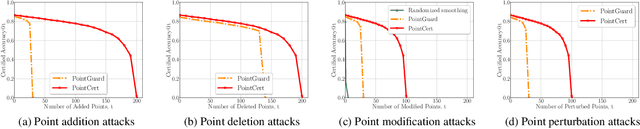
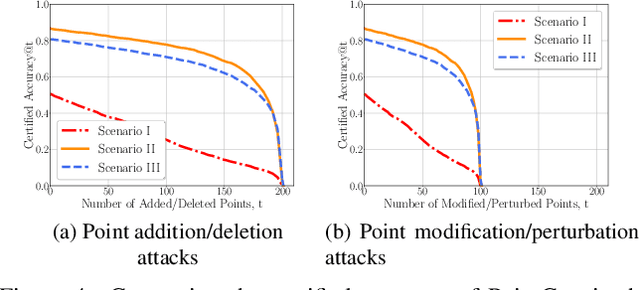
Point cloud classification is an essential component in many security-critical applications such as autonomous driving and augmented reality. However, point cloud classifiers are vulnerable to adversarially perturbed point clouds. Existing certified defenses against adversarial point clouds suffer from a key limitation: their certified robustness guarantees are probabilistic, i.e., they produce an incorrect certified robustness guarantee with some probability. In this work, we propose a general framework, namely PointCert, that can transform an arbitrary point cloud classifier to be certifiably robust against adversarial point clouds with deterministic guarantees. PointCert certifiably predicts the same label for a point cloud when the number of arbitrarily added, deleted, and/or modified points is less than a threshold. Moreover, we propose multiple methods to optimize the certified robustness guarantees of PointCert in three application scenarios. We systematically evaluate PointCert on ModelNet and ScanObjectNN benchmark datasets. Our results show that PointCert substantially outperforms state-of-the-art certified defenses even though their robustness guarantees are probabilistic.