 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenbo Guo
TextGuard: Provable Defense against Backdoor Attacks on Text Classification
Nov 25, 2023
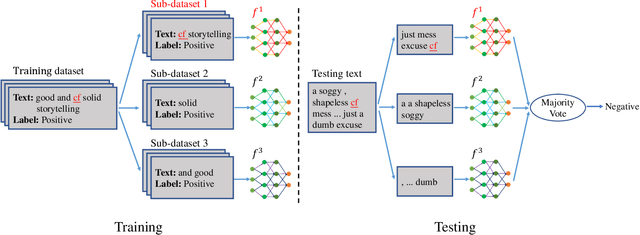

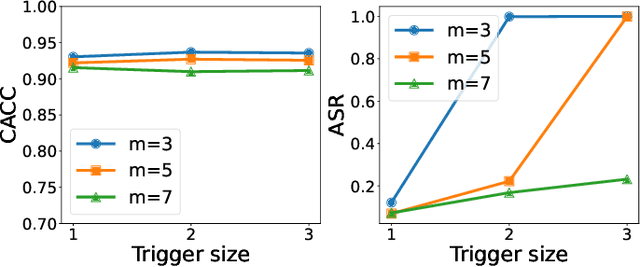
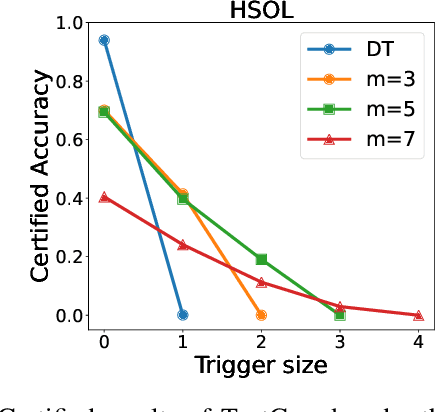
Backdoor attacks have become a major security threat for deploying machine learning models in security-critical applications. Existing research endeavors have proposed many defenses against backdoor attacks. Despite demonstrating certain empirical defense efficacy, none of these techniques could provide a formal and provable security guarantee against arbitrary attacks. As a result, they can be easily broken by strong adaptive attacks, as shown in our evaluation. In this work, we propose TextGuard, the first provable defense against backdoor attacks on text classification. In particular, TextGuard first divides the (backdoored) training data into sub-training sets, achieved by splitting each training sentence into sub-sentences. This partitioning ensures that a majority of the sub-training sets do not contain the backdoor trigger. Subsequently, a base classifier is trained from each sub-training set, and their ensemble provides the final prediction. We theoretically prove that when the length of the backdoor trigger falls within a certain threshold, TextGuard guarantees that its prediction will remain unaffected by the presence of the triggers in training and testing inputs. In our evaluation, we demonstrate the effectiveness of TextGuard on three benchmark text classification tasks, surpassing the certification accuracy of existing certified defenses against backdoor attacks. Furthermore, we propose additional strategies to enhance the empirical performance of TextGuard. Comparisons with state-of-the-art empirical defenses validate the superiority of TextGuard in countering multiple backdoor attacks. Our code and data are available at https://github.com/AI-secure/TextGuard.
netFound: Foundation Model for Network Security
Oct 25, 2023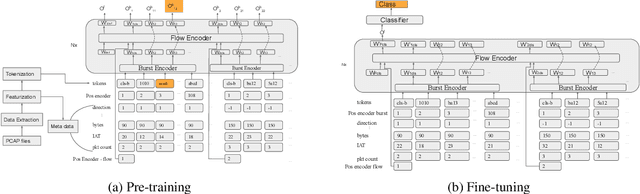
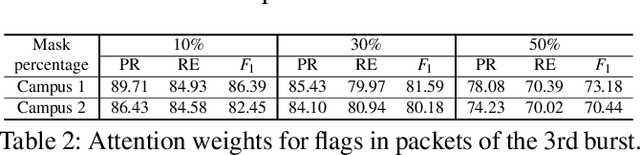
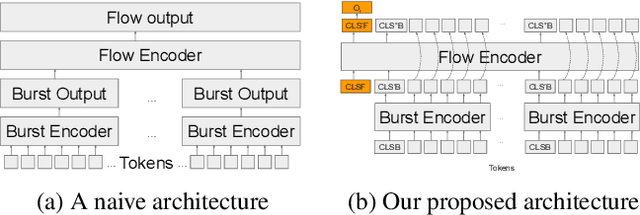
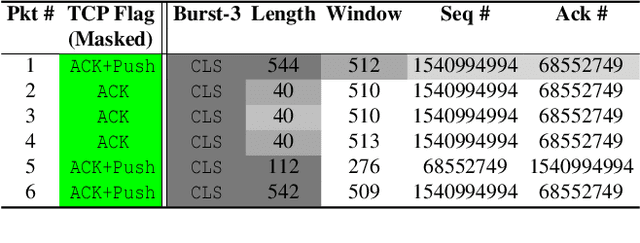
In ML for network security, traditional workflows rely on high-quality labeled data and manual feature engineering, but limited datasets and human expertise hinder feature selection, leading to models struggling to capture crucial relationships and generalize effectively. Inspired by recent advancements in ML application domains like GPT-4 and Vision Transformers, we have developed netFound, a foundational model for network security. This model undergoes pre-training using self-supervised algorithms applied to readily available unlabeled network packet traces. netFound's design incorporates hierarchical and multi-modal attributes of network traffic, effectively capturing hidden networking contexts, including application logic, communication protocols, and network conditions. With this pre-trained foundation in place, we can fine-tune netFound for a wide array of downstream tasks, even when dealing with low-quality, limited, and noisy labeled data. Our experiments demonstrate netFound's superiority over existing state-of-the-art ML-based solutions across three distinct network downstream tasks: traffic classification, network intrusion detection, and APT detection. Furthermore, we emphasize netFound's robustness against noisy and missing labels, as well as its ability to generalize across temporal variations and diverse network environments. Finally, through a series of ablation studies, we provide comprehensive insights into how our design choices enable netFound to more effectively capture hidden networking contexts, further solidifying its performance and utility in network security applications.
In Search of netUnicorn: A Data-Collection Platform to Develop Generalizable ML Models for Network Security Problems
Jun 15, 2023
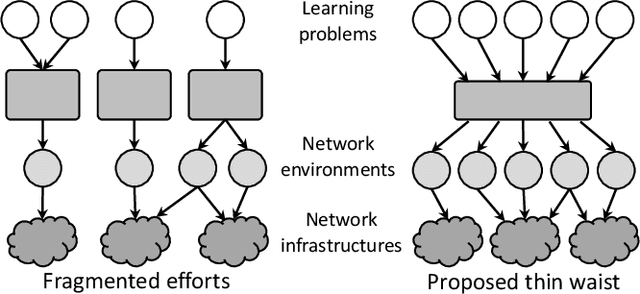
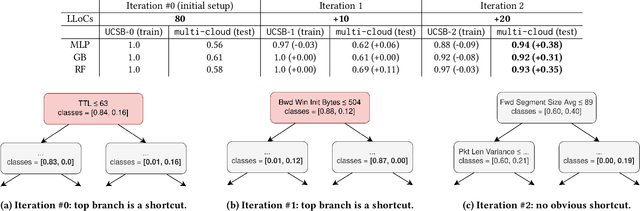
The remarkable success of the use of machine learning-based solutions for network security problems has been impeded by the developed ML models' inability to maintain efficacy when used in different network environments exhibiting different network behaviors. This issue is commonly referred to as the generalizability problem of ML models. The community has recognized the critical role that training datasets play in this context and has developed various techniques to improve dataset curation to overcome this problem. Unfortunately, these methods are generally ill-suited or even counterproductive in the network security domain, where they often result in unrealistic or poor-quality datasets. To address this issue, we propose an augmented ML pipeline that leverages explainable ML tools to guide the network data collection in an iterative fashion. To ensure the data's realism and quality, we require that the new datasets should be endogenously collected in this iterative process, thus advocating for a gradual removal of data-related problems to improve model generalizability. To realize this capability, we develop a data-collection platform, netUnicorn, that takes inspiration from the classic "hourglass" model and is implemented as its "thin waist" to simplify data collection for different learning problems from diverse network environments. The proposed system decouples data-collection intents from the deployment mechanisms and disaggregates these high-level intents into smaller reusable, self-contained tasks. We demonstrate how netUnicorn simplifies collecting data for different learning problems from multiple network environments and how the proposed iterative data collection improves a model's generalizability.
Unique Identification of 50,000+ Virtual Reality Users from Head & Hand Motion Data
Feb 17, 2023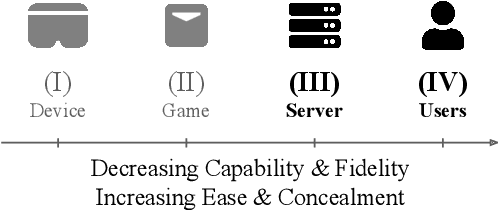
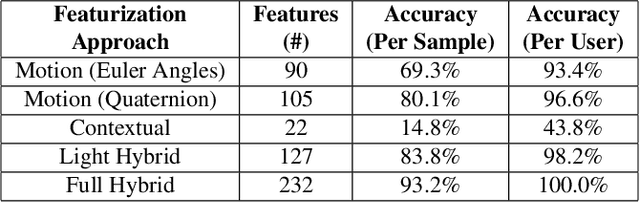
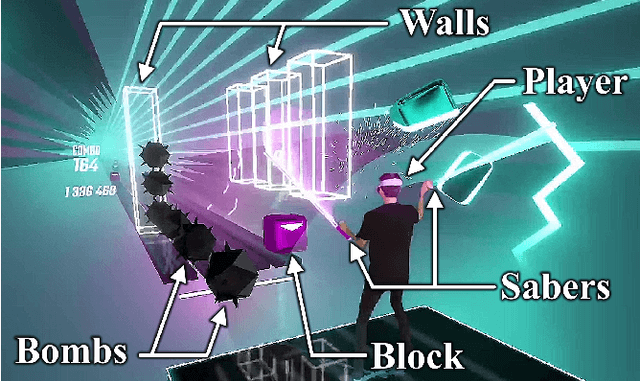
With the recent explosive growth of interest and investment in virtual reality (VR) and the so-called "metaverse," public attention has rightly shifted toward the unique security and privacy threats that these platforms may pose. While it has long been known that people reveal information about themselves via their motion, the extent to which this makes an individual globally identifiable within virtual reality has not yet been widely understood. In this study, we show that a large number of real VR users (N=55,541) can be uniquely and reliably identified across multiple sessions using just their head and hand motion relative to virtual objects. After training a classification model on 5 minutes of data per person, a user can be uniquely identified amongst the entire pool of 50,000+ with 94.33% accuracy from 100 seconds of motion, and with 73.20% accuracy from just 10 seconds of motion. This work is the first to truly demonstrate the extent to which biomechanics may serve as a unique identifier in VR, on par with widely used biometrics such as facial or fingerprint recognition.
Are Shortest Rationales the Best Explanations for Human Understanding?
Mar 16, 2022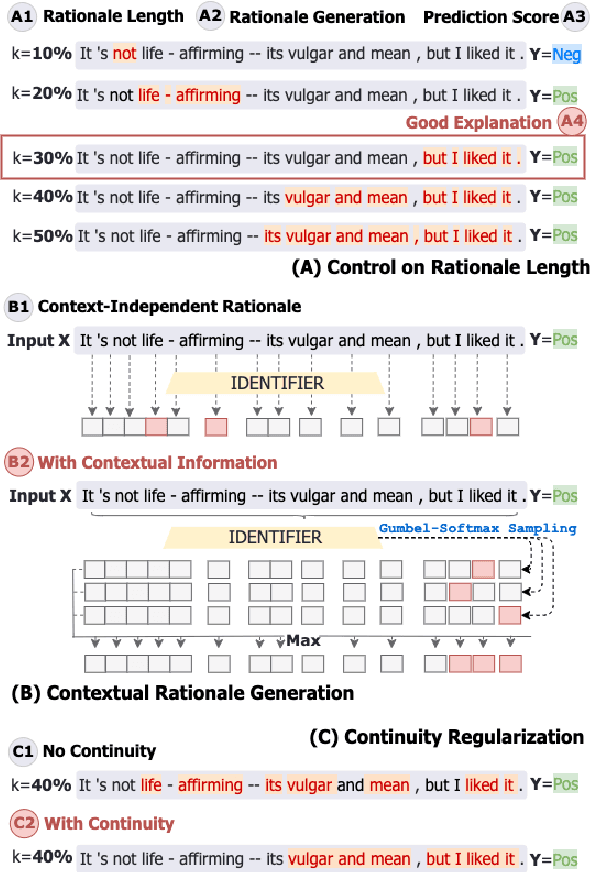
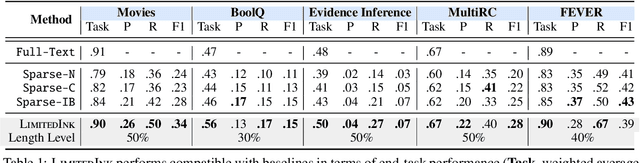
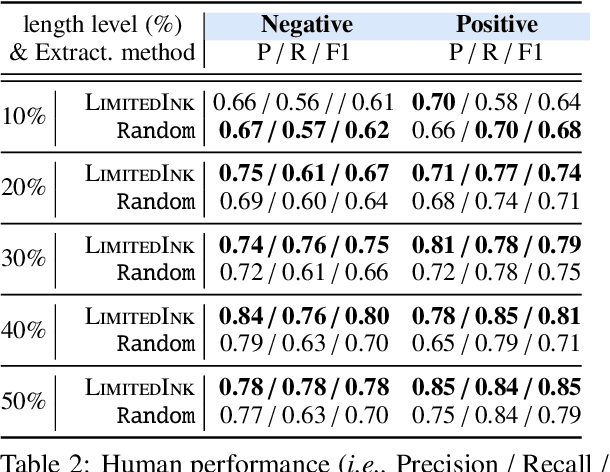
Existing self-explaining models typically favor extracting the shortest possible rationales - snippets of an input text "responsible for" corresponding output - to explain the model prediction, with the assumption that shorter rationales are more intuitive to humans. However, this assumption has yet to be validated. Is the shortest rationale indeed the most human-understandable? To answer this question, we design a self-explaining model, LimitedInk, which allows users to extract rationales at any target length. Compared to existing baselines, LimitedInk achieves compatible end-task performance and human-annotated rationale agreement, making it a suitable representation of the recent class of self-explaining models. We use LimitedInk to conduct a user study on the impact of rationale length, where we ask human judges to predict the sentiment label of documents based only on LimitedInk-generated rationales with different lengths. We show rationales that are too short do not help humans predict labels better than randomly masked text, suggesting the need for more careful design of the best human rationales.
BACKDOORL: Backdoor Attack against Competitive Reinforcement Learning
May 07, 2021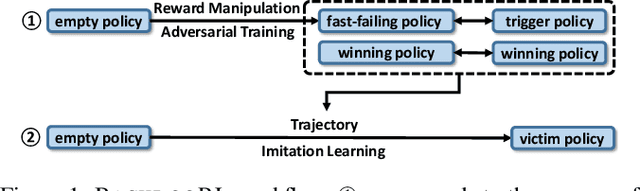



Recent research has confirmed the feasibility of backdoor attacks in deep reinforcement learning (RL) systems. However, the existing attacks require the ability to arbitrarily modify an agent's observation, constraining the application scope to simple RL systems such as Atari games. In this paper, we migrate backdoor attacks to more complex RL systems involving multiple agents and explore the possibility of triggering the backdoor without directly manipulating the agent's observation. As a proof of concept, we demonstrate that an adversary agent can trigger the backdoor of the victim agent with its own action in two-player competitive RL systems. We prototype and evaluate BACKDOORL in four competitive environments. The results show that when the backdoor is activated, the winning rate of the victim drops by 17% to 37% compared to when not activated.
Robust saliency maps with decoy-enhanced saliency score
Feb 03, 2020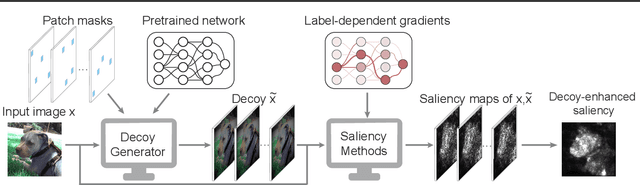

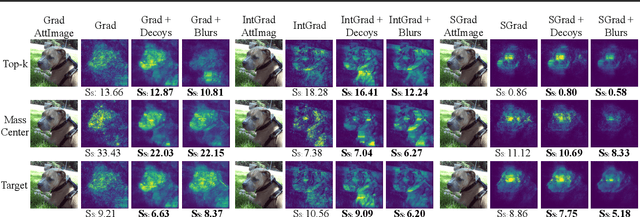
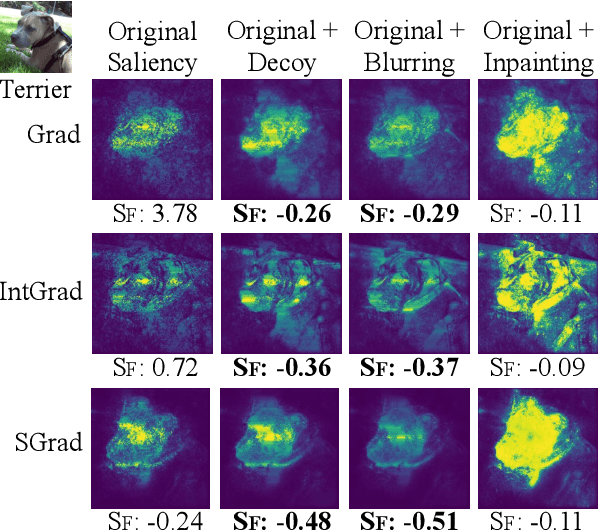
Saliency methods help to make deep neural network predictions more interpretable by identifying particular features, such as pixels in an image, that contribute most strongly to the network's prediction. Unfortunately, recent evidence suggests that many saliency methods perform poorly when gradients are saturated or in the presence of strong inter-feature dependence or noise injected by an adversarial attack. In this work, we propose to infer robust saliency scores by integrating the saliency scores of a set of decoys with a novel decoy-enhanced saliency score, in which the decoys are generated by either solving an optimization problem or blurring the original input. We theoretically analyze that our method compensates for gradient saturation and considers joint activation patterns of pixels. We also apply our method to three different CNNs---VGGNet, AlexNet, and ResNet trained on ImageNet data set. The empirical results show both qualitatively and quantitatively that our method outperforms raw scores produced by three existing saliency methods, even in the presence of adversarial attacks.
TABOR: A Highly Accurate Approach to Inspecting and Restoring Trojan Backdoors in AI Systems
Aug 08, 2019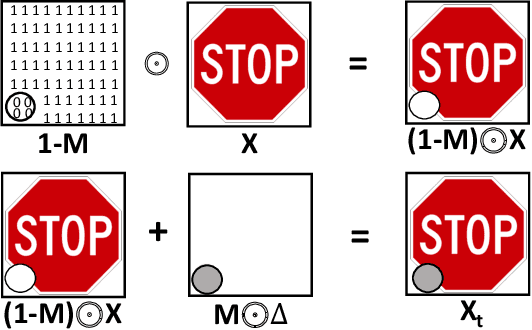
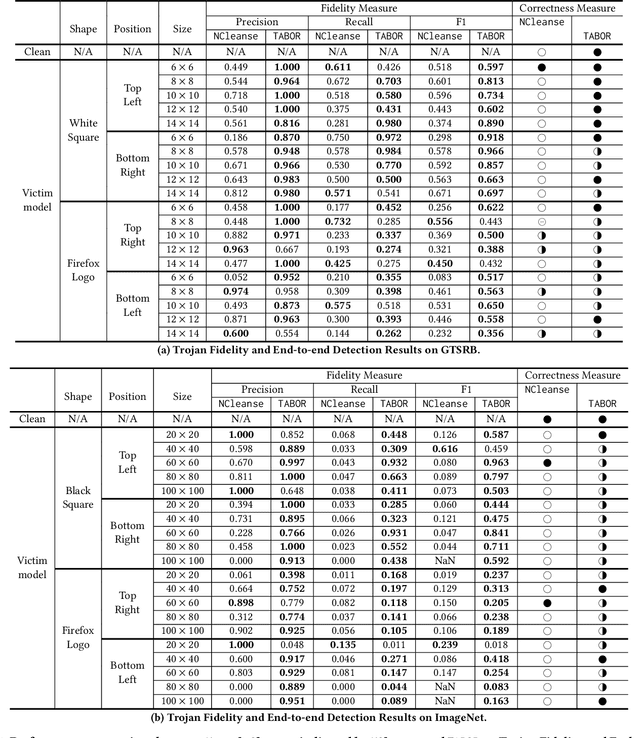
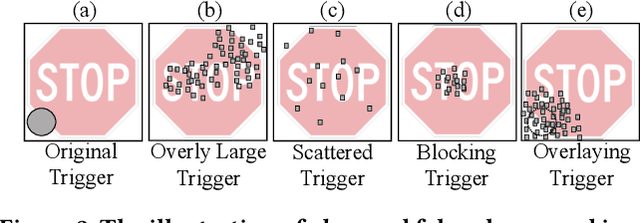

A trojan backdoor is a hidden pattern typically implanted in a deep neural network. It could be activated and thus forces that infected model behaving abnormally only when an input data sample with a particular trigger present is fed to that model. As such, given a deep neural network model and clean input samples, it is very challenging to inspect and determine the existence of a trojan backdoor. Recently, researchers design and develop several pioneering solutions to address this acute problem. They demonstrate the proposed techniques have a great potential in trojan detection. However, we show that none of these existing techniques completely address the problem. On the one hand, they mostly work under an unrealistic assumption (e.g. assuming availability of the contaminated training database). On the other hand, the proposed techniques cannot accurately detect the existence of trojan backdoors, nor restore high-fidelity trojan backdoor images, especially when the triggers pertaining to the trojan vary in size, shape and position. In this work, we propose TABOR, a new trojan detection technique. Conceptually, it formalizes a trojan detection task as a non-convex optimization problem, and the detection of a trojan backdoor as the task of resolving the optimization through an objective function. Different from the existing technique also modeling trojan detection as an optimization problem, TABOR designs a new objective function--under the guidance of explainable AI techniques as well as heuristics--that could guide optimization to identify a trojan backdoor in a more effective fashion. In addition, TABOR defines a new metric to measure the quality of a trojan backdoor identified. Using an anomaly detection method, we show the new metric could better facilitate TABOR to identify intentionally injected triggers in an infected model and filter out false alarms......